SQL> drop table 'BIN$bSXyAHGW3yzgQAB/AQAoOQ==$0' 2 ; drop table 'BIN$bSXyAHGW3yzgQAB/AQAoOQ==$0' * ERROR at line 1: ORA-00903: invalid table name
SQL> drop table 'BIN$bSXyAHGW3yzgQAB/AQAoOQ==$0' cascade constraints 2 ; drop table 'BIN$bSXyAHGW3yzgQAB/AQAoOQ==$0' cascade constraints * ERROR at line 1: ORA-00903: invalid table name
SQL> drop table 'BIN*' ; 2 drop table 'BIN*' * ERROR at line 1: ORA-00903: invalid table name
분석함수는 8i 버전에서 persnal edition, enterprise edition에서 지원하고,
9i버전에서는 모든 버전에 지원된다. 문법은 다음과 같다.
SELECT Analytic_Function ( arguments )
OVER( [ PARTITION BY 칼럼 ] [ ORDER BY 절 ] [ Windowing 절] )
FROM 테이블 명;
- Partition By : 전체 집합을 기준에 의해 소그룹으로 나눔
- Order By : PARTITION BY에 나열된 그룹을 정렬함
- Windowing : 펑션의 대상이 되는 행 기준으로 범위를 세밀하게 조정
(메뉴얼: window IS a physical or logical SET of rows)
* Windowing절에 대한 설명
1. ROWS/RANGE UNBOUNDED PRECEDING/
CURRENT ROW/
value_expr PRECEDING
2. ROWS/RANGE BETWEEN UNBOUNDED PRECEDING/
CURRENT ROW/
value_expr PRECEDING/FOLLOWING
AND UNBOUNDED FOLLOWING
CURRENT ROW/
value_expr PRECEDING/FOLLOWING
: RANGE는 값이며, ROWS는 행의 수를 의미한다.
- RANGE BETWEEN 50 PRECEDING AND 150 FOLLOWING
: BETWEEN Current_Row -50 AND 150 의 파티션 내의 모든행이 window
즉, Current_Row의 값 - 50 ~ Current_Row의 값 + 150의 값은 모두 하나의 그룹
- ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
: 현재행을 기준으로 파티션 내의 앞/뒤 한건이 Window
- RANGE UNBOUNDED PRECEDING
: 현재 행을 기준으로 파티션 내의 첫 번째 행까지가 Window
- ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
: 현재행을 기준으로 파티션 내의 첫 번째 행부터 끝 행까지가 Window. 즉, 파티션 모두가 Window
select
ename
, sal
, sum(sal) over(partition by deptno order by sal) ASC순으로_부서별_sal누적
, sum(sal) over(partition by deptno) 부서별_sal합계
, sum(sal) over(order by deptno, sal) deptno_sal_ASC정렬후_누적
, sum(sal) over() sal총계
from emp
order by deptno, sal;
--over() 안의 oder by는 정렬 후 해당 행과 이전행을 모두 함친 것의 계산 - 여기에서는 SUM()
--over() 안의 partition by는 group by 역할을 한다. 분석에 대한 범위를 지정하는 역할.
/*
ENAME SAL ASC순으로_부서별_SAL누적 부서별_SAL합계 DEPTNO_SAL_ASC정렬후_누적 SAL총계
---------- --------- ------------------------ -------------- ------------------------- ----------
MILLER 1300.00 1300 8750 1300 29025
CLARK 2450.00 3750 8750 3750 29025
KING 5000.00 8750 8750 8750 29025
SMITH 800.00 800 10875 9550 29025
ADAMS 1100.00 1900 10875 10650 29025
JONES 2975.00 4875 10875 13625 29025
SCOTT 3000.00 10875 10875 19625 29025
FORD 3000.00 10875 10875 19625 29025
JAMES 950.00 950 9400 20575 29025
WARD 1250.00 3450 9400 23075 29025
MARTIN 1250.00 3450 9400 23075 29025
TURNER 1500.00 4950 9400 24575 29025
ALLEN 1600.00 6550 9400 26175 29025
BLAKE 2850.00 9400 9400 29025 29025
14 rows selected
*/
* 사원 중 직무별로 가장 많은 월급을 받는 사람의 사원번호, 직무명, 월급을 출력하라
SELECT T1.EMPNO, T2.JOB, T2.MAX_SAL
FROM EMP T1,
(SELECT JOB, MAX(SAL) AS MAX_SAL
FROM EMP
GROUP BY JOB) T2
WHERE T1.JOB = T2.JOB
AND T1.SAL = T2.MAX_SAL;
select empno, sal
from (
select
empno
, min(abs_sal) over() min_sal
, abs_sal
, sal
from (
select
empno
, sal
, abs(sal - avg(sal) over()) abs_sal
from emp) )
where abs_sal = min_sal;
SQL> select avg(sal) from emp;
AVG(SAL)
----------
2073.21428
EMPNO SAL
----- ---------
7782 2450.00
부서별로 일련번호를 붙이되 각각의 부서마다 1로 시작하는 일련번호를 붙인다.
SELECT
deptno
, empno
, ename
, row_number() over(PARTITION BY deptno ORDER BY deptno)
FROM emp;
DEPTNO EMPNO ENAME ROW_NUMBER()OVER(PARTITIONBYDE
------ ----- ---------- ------------------------------
10 7782 CLARK 1
10 7839 KING 2
10 7934 MILLER 3
20 7369 SMITH 1
20 7876 ADAMS 2
20 7902 FORD 3
20 7788 SCOTT 4
20 7566 JONES 5
30 7499 ALLEN 1
30 7698 BLAKE 2
30 7654 MARTIN 3
30 7900 JAMES 4
30 7844 TURNER 5
30 7521 WARD 6
14 rows selected
* 부서별 월급이 많은 순서대로 순위구하기
SELECT
empno
, ename
, sal
, rank() over(PARTITION BY deptno ORDER BY sal DESC)
FROM emp;
--rank() over(PARTITION BY deptno ORDER BY sal DESC)를
--rank() over(PARTITION BY deptno ORDER BY sal ASC)로 고치면 역순이 된다.
--rank()는 동일 순위에 대하여 동일한 값을 리턴하지만 공백이 생긴다.
--즉, 1위에 해당된느 행이 2개이면 2는 존재하지 않고, 바로 3으로 넘어간다.
EMPNO ENAME SAL RANK()OVER(PARTITIONBYDEPTNOOR
----- ---------- --------- ------------------------------
7839 KING 5000.00 1
7782 CLARK 2450.00 2
7934 MILLER 1300.00 3
7788 SCOTT 3000.00 1
7902 FORD 3000.00 1
7566 JONES 2975.00 3
7876 ADAMS 1100.00 4
7369 SMITH 800.00 5
7698 BLAKE 2850.00 1
7499 ALLEN 1600.00 2
7844 TURNER 1500.00 3
7521 WARD 1250.00 4
7654 MARTIN 1250.00 4
7900 JAMES 950.00 6
SELECT
empno
, ename
, sal
, dense_rank() over(PARTITION BY deptno ORDER BY sal DESC)
FROM emp;
dense_rank()는 rank()와는 달리 1위가 2개 존재하면 다음의 순위는 2가 된다.
EMPNO ENAME SAL DENSE_RANK()OVER(PARTITIONBYDE
----- ---------- --------- ------------------------------
7839 KING 5000.00 1
7782 CLARK 2450.00 2
7934 MILLER 1300.00 3
7788 SCOTT 3000.00 1
7902 FORD 3000.00 1
7566 JONES 2975.00 2
7876 ADAMS 1100.00 3
7369 SMITH 800.00 4
7698 BLAKE 2850.00 1
7499 ALLEN 1600.00 2
7844 TURNER 1500.00 3
7521 WARD 1250.00 4
7654 MARTIN 1250.00 4
7900 JAMES 950.00 5
* TOP n개 가져오기
SELECT
empno
, ename
, sal
, rank
FROM (
SELECT
empno
, ename
, sal
, rank() over(PARTITION BY deptno ORDER BY sal DESC) rank
FROM emp)
WHERE rank <= 3;
경우에 따라서 rank(), dense_rank()를 사용한다.
EMPNO ENAME SAL RANK
----- ---------- --------- ----------
7839 KING 5000.00 1
7782 CLARK 2450.00 2
7934 MILLER 1300.00 3
7788 SCOTT 3000.00 1
7902 FORD 3000.00 1
7566 JONES 2975.00 3
7698 BLAKE 2850.00 1
7499 ALLEN 1600.00 2
7844 TURNER 1500.00 3
* 피봇
SELECT
deptno
, max(CASE WHEN rank = 1 THEN sal END) rank_1
, max(CASE WHEN rank = 2 THEN sal END) rank_2
, max(CASE WHEN rank = 3 THEN sal END) rank_3
FROM (
SELECT
sal
, deptno
, rank
FROM (
SELECT
sal
, deptno
, rank() over(PARTITION BY deptno ORDER BY sal DESC) rank
FROM emp)
WHERE rank <= 3 )
GROUP BY deptno
SELECT
empno
, ename
, sal - lag(sal, 1) over(ORDER BY hiredate) pre
, sal
, sal - lead(sal, 1) over(ORDER BY hiredate) NEXT
FROM emp;
EMPNO ENAME PRE SAL NEXT
----- ---------- ---------- --------- ----------
7369 SMITH 800.00 -800
7499 ALLEN 800 1600.00 350
7521 WARD -350 1250.00 -1725
7566 JONES 1725 2975.00 125
7698 BLAKE -125 2850.00 400
7782 CLARK -400 2450.00 950
7844 TURNER -950 1500.00 250
7654 MARTIN -250 1250.00 -3750
7839 KING 3750 5000.00 4050
7900 JAMES -4050 950.00 -2050
7902 FORD 2050 3000.00 1700
7934 MILLER -1700 1300.00 -1700
7788 SCOTT 1700 3000.00 1900
7876 ADAMS -1900 1100.00
* 특정 범위내의 첫행/끝행
SELECT DEPTNO,ENAME,SAL,
FIRST_VALUE(ENAME) OVER(PARTITION BY DEPTNO
ORDER BY SAL DESC
ROWS BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING) AS FV,
LAST_VALUE(ENAME) OVER(PARTITION BY DEPTNO
ORDER BY SAL DESC
ROWS BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING) AS LV
FROM EMP;
DEPTNO ENAME SAL FV LV
------ ---------- --------- ---------- ----------
10 KING 5000.00 KING MILLER
10 CLARK 2450.00 KING MILLER
10 MILLER 1300.00 KING MILLER
20 SCOTT 3000.00 SCOTT SMITH
20 FORD 3000.00 SCOTT SMITH
20 JONES 2975.00 SCOTT SMITH
20 ADAMS 1100.00 SCOTT SMITH
20 SMITH 800.00 SCOTT SMITH
30 BLAKE 2850.00 BLAKE JAMES
30 ALLEN 1600.00 BLAKE JAMES
30 TURNER 1500.00 BLAKE JAMES
30 WARD 1250.00 BLAKE JAMES
30 MARTIN 1250.00 BLAKE JAMES
30 JAMES 950.00 BLAKE JAMES
* RATIO_TO_REPORT : 그룹에서 현재 행의 비율
SELECT JOB, ENAME, SAL,
RATIO_TO_REPORT(SAL) OVER(PARTITION BY JOB) AS RR
FROM EMP
ORDER BY JOB, ENAME;
JOB ENAME SAL RR
--------- ---------- --------- ----------
ANALYST FORD 3000.00 0.5
ANALYST SCOTT 3000.00 0.5
CLERK ADAMS 1100.00 0.26506024
CLERK JAMES 950.00 0.22891566
CLERK MILLER 1300.00 0.31325301
CLERK SMITH 800.00 0.19277108
MANAGER BLAKE 2850.00 0.34441087
MANAGER CLARK 2450.00 0.29607250
MANAGER JONES 2975.00 0.35951661
PRESIDENT KING 5000.00 1
SALESMAN ALLEN 1600.00 0.28571428
SALESMAN MARTIN 1250.00 0.22321428
SALESMAN TURNER 1500.00 0.26785714
SALESMAN WARD 1250.00 0.22321428
SELECT ENAME,SAL,
COUNT(*) OVER(ORDER BY SAL
RANGE BETWEEN 149 PRECEDING
AND 0 FOLLOWING) AS m_cnt
FROM EMP;
ENAME SAL M_CNT
---------- --------- ----------
SMITH 800.00 1
JAMES 950.00 2 ---> 950 - 150 ~ 950 + 0, 만약 149로 범위를 줄이면 1로 된다.
ADAMS 1100.00 2
WARD 1250.00 3
MARTIN 1250.00 3
MILLER 1300.00 3
TURNER 1500.00 1
ALLEN 1600.00 2
CLARK 2450.00 1
BLAKE 2850.00 1
JONES 2975.00 2
SCOTT 3000.00 4
FORD 3000.00 4
KING 5000.00 1
SELECT TO_CHAR (SID) sid, serial# serialNumber,
SUBSTR (TO_CHAR (last_call_et), 1, 6) executeSeconds, userName, machine,
b.sql_text sqlText
FROM v$session a, v$sqltext b
WHERE username NOT IN ('SYSTEM', 'SYS')
AND a.TYPE != 'BACKGROUND'
AND a.status = 'ACTIVE'
AND a.sql_address = b.address(+)
AND a.sql_hash_value = b.hash_value(+)
ORDER BY a.last_call_et DESC,
a.SID,
a.serial#,
b.address,
b.hash_value,
b.piece
이 쿼리를 돌리면 현재 오라클에서 돌고 있는 쿼리와 수행 시간을 알 수 있다.
다만 저 쿼리를 돌리는 계정이 $session과 $sqltext 를 확인할 수 있는 권한이 있어야 한다.
Oracle Text는 모든 오라클 데이터베이스 제품(Express Edition 포함)에 기본적으로 포함되어 제공되는 강력한 검색 테크놀로지입니다. Oracle Text에서 제공되는 개발 API를 이용하여 완성도 높은 컨텐트 검색 애플리케이션을 쉽게 구현할 수 있습니다.
Oracle Text는 SQL 와일드카드 매칭 기능을 보완하는 기능을 제공하며, 구조형/비구조형 문서를 검색하는 용도로 활용됩니다. Oracle Text는 기본적 불리언 연산자(AND, OR, NOT, NEAR 등)의 조합을 지원하며 사운덱스(soundex) 검색, 퍼지(fuzzy) 검색, 결과 랭킹과 같은 고급 기능을 함께 제공하고 있습니다. 또 마이크로소프트 오피스와 PDF를 포함하는 수백여 종의 파일 타입이 지원됩니다. Oracle Text는 다양한 검색 관련 유즈 케이스 및 스토리지 구조에 적합한 검색 모델을 제공합니다. Oracle Text가 적용될 수 있는 몇 가지 예로 e-비즈니스, 문서/기록 관리, 이슈 트랙킹 시스템 등을 들 수 있습니다. 텍스트 정보는 데이터베이스 내에 구조적인 형태로 저장되거나, 또는 로컬 파일 시스템이나 웹에 비구조적인 형태로 저장될 수 있습니다.
Oracle Text는 커스텀 쿼리 연산자, DDL 신택스 확장, PL/SQL 프로시저, 데이터베이스 뷰 등을 포함하는 포괄적인 SQL 기반 검색 API를 제공합니다. 애플리케이션 개발자는 Oracle Text API를 이용하여 인덱싱, 쿼리, 보안, 프리젠테이션, 소프트웨어 설정 등의 컨트롤을 확보할 수 있습니다. 이러한 기능은 커스텀 애플리케이션이 아닌 상용 애플리케이션을 개발하는 경우에 특히 유용합니다. 상용 소프트웨어 제품을 개발하는 경우에는 소프트웨어의 설정을 가능한 한 단순한 형태로 유지하는 것이 관건이 됩니다. 애플리케이션의 복잡성을 최소화하는 것은 기술 지원, 유지 보수, 업그레이드 등 향후 제품 라이프사이클 전반에 걸친 이점을 제공합니다.
Oracle Text는 또 고성능 환경에서 구현이 까다로운 문서 레벨 승인(document level authorization) 기능을 지원하고 있습니다. 관계형 데이터 및 비구조형 데이터에 대해 텍스트가 혼합된 쿼리를 사용하는 것 또한 가능합니다. 이는 단일 쿼리 내에서 전체 텍스트 검색과 승인 기능을 함께 사용할 수 있음을 의미합니다. 최종적인 결과를 얻기 위해 결과 셋을 분리하고 필터링을 적용하는 작업이 최소화되므로 애플리케이션 개발 업무의 단순화가 가능합니다. Oracle Text는 성능 최적화와 관련된 애플리케이션 개발자의 업무 부담을 줄여 줍니다.
Oracle Text는 또 프로그래밍 언어로부터 독립적이며 Java, PHP 애플리케이션과 유연하게 연동됩니다.
언젠가 필자는 엔터프라이즈 컨텐트 관리(ECM) 시스템의 검색 기능을 개선하는 작업에 참여한 일이 있습니다. 필자는 프로젝트를 시작하면서 제일 먼저 Oracle Text의 활용 가능성을 검토하는 작업에 착수했습니다. 검토 결과, Oracle Text가 애플리케이션의 검색 기능 구현에 매우 적합한 도구임이 판명되었습니다. Oracle Text는 고급 검색 기능을 포함하고 있으며, 다양한 파일 유형을 지원할 뿐 아니라, 커스터마이즈 및 확장이 매우 용이합니다. 기존 검색 테크놀로지들의 경우 데이터베이스 외부의 파일 컨텐트를 검색하고, 다시 데이터베이스 메타데이터를 검색하고, 결과를 승인하고, 마지막으로 서로 분리된 결과 셋을 병합하는 번거로운 절차를 요구한다는 문제가 있었습니다. Oracle Text는 이러한 모든 작업을 데이터베이스 내부에서 수행합니다. 이 프로젝트의 ECM 시스템은 이미 오라클 데이터베이스에 메타데이터를 저장하고 있었습니다. 이미 기반이 마련되어 있는 환경에서, 추가적인 비용을 들이지 않고 Oracle Text를 활용하는 것은 어찌 보면 당연한 선택이었습니다.
데이터베이스에서 텍스트 검색 쿼리를 구현하기 위한 일반적인 방법이 아래와 같습니다.
SELECT * FROM issues
WHERE LOWER(author) LIKE '%word1%' AND LOWER(author) LIKE '%word2%' ...
여기서 각각의 키워드는 컬럼별로 제각각 매치되며, 키워드의 순서에 관계없이 매치가 가능합니다. 하지만 관계형 데이터베이스는 이러한 쿼리를 효과적으로 실행하도록 설계되지 않았으며, 따라서 이러한 접근법은 확장성 면에서 심각한 한계를 갖습니다. 물론 별도의 인덱싱/검색 솔루션을 고안해 낼 수도 있겠지만, 이미 검색 테크놀로지 구현 비용을 별도로 지출한 경우가 아니라면 비용효율적인 솔루션을 얻어내기가 매우 어려울 것입니다.
본 문서는 가상의 이슈 트래킹 애플리케이션에서 Oracle Text를 활용하는 방법을 소개하고 있습니다. 애플리케이션에서 사용자에 의해 생성된 '이슈'는 메타데이터와 첨부 파일로 구성됩니다. 애플리케이션은 Oracle Text를 이용하여 메타데이터 및 첨부 파일 컨텐트에 대한 전체 텍스트 검색을 수행합니다.
본 예제는 Linux 기반 Oracle Database XE 환경에서 테스트 되었으며, 다른 오라클 플랫폼에서도 문제 없이 동작할 것으로 예상됩니다.
인덱싱 프로세스와 검색
Oracle Text는 사용자가 컨텐트 검색을 수행하기 전에 조회 가능한 데이터 아이템에 대한 인덱스를 생성합니다. 이는 검색 성능의 개선을 위해 반드시 필요한 작업입니다. Oracle Text 인덱싱 프로세스는 파이프라인을 모델로 하며, 데이터 저장소에서 인출된 데이터 아이템은 일련의 변환 과정을 거친 후 인덱스에 그 키워드가 추가됩니다. 인덱싱 프로세스는 여러 단계로 나뉘며, 각 단계별로 처리되는 엔티티는 애플리케이션 개발자에 의해 설정이 가능합니다.
Oracle Text는 여러 가지 인덱스 타입을 지원하며, 인덱스 타입의 선택은 그 활용 목적에 따라 달라집니다. 대용량 문서에 대한 전체 텍스트 검색을 위해서는 CONTEXT 인덱스 타입이 가장 적합합니다. 인덱싱 프로세스는 다음과 같은 단계를 거쳐 진행됩니다.
데이터 인출: 데이터 저장소(웹 페이지, 데이터베이스 LOB, 로컬 파일 시스템 등)로부터 데이터가 인출되어 다음 단계의 처리를 위해 데이터 스트림으로 전달됩니다.
필터링: 서로 다른 파일 포맷의 데이터를 일반 텍스트로 변환하기 위해 필터링 프로세스가 적용됩니다. 인덱싱 파이프라인의 다른 컴포넌트들은 일반 텍스트 포맷만을 처리하며 원본 파일 포맷(Microsoft Word, Excel 등)에 대해 알지 못합니다.
섹셔닝(Sectioning): 섹셔너(sectioner)가 원본 데이터 아이템의 구조에 대한 메타데이터를 추가합니다.
렉싱(Lexing): 캐릭터 스트림이 아이템의 언어를 기준으로 단어(word)로 분할됩니다.
인덱싱: 키워드가 실제 인덱스에 추가됩니다.
인덱스가 생성되고 나면, 엔드 유저는 애플리케이션에서 SQL 쿼리를 이용하여 검색을 실행할 수 있습니다.
Oracle Text의 설정
Oracle Text는 기본적으로 Oracle Database XE와 함께 설치됩니다. 다른 데이터베이스 버전의 경우, Oracle Text를 별도로 설치해야 합니다. Oracle Text의 설치를 완료한 다음에는, 데이터베이스 사용자를 생성하고 이 사용자에게 CTXAPP 롤을 할당해 주기만 하면 됩니다. CTXAPP 롤을 할당 받은 사용자는 인덱스 관리 작업을 수행할 수 있는 권한을 가집니다.
CREATE USER ot1 IDENTIFIED BY ot1;
GRANT connect,resource, ctxapp TO ot1;
파일 인덱스
이제 이슈 트래킹 시스템에 저장된 첨부 파일의 인덱싱을 위해 텍스트 테이블을 생성해야 합니다. 첨부 파일은 파일 시스템에 저장되어 있습니다. 애플리케이션의 데이터 모델이 요구하는 컬럼과 별도로, 텍스트 기반 테이블은 절대 파일 경로와 포맷 컬럼 정보를 포함하고 있습니다.
CREATE TABLE files (
id NUMBER PRIMARY KEY,
issue_id NUMBER,
path VARCHAR(255) UNIQUE,
ot_format VARCHAR(6)
);
INSERT INTO files VALUES (1, 1, '/tmp/oracletext/found1.txt', NULL);
INSERT INTO files VALUES (2, 2, '/tmp/oracletext/found2.doc', NULL);
INSERT INTO files VALUES (3, 2, '/tmp/oracletext/notfound.txt', 'IGNORE');
ot_format의 값은 인덱싱 과정에서 Oracle Text에 의해 계산됩니다. NULL 값은 파일을 위한 필터가 자동으로 선택됨을 의미하며, IGNORE는 파일을 완전히 무시함을 의미합니다.
텍스트 인덱스를 생성하기 위한 구문이 아래와 같습니다.
CREATE INDEX file_index ON files(path) INDEXTYPE IS ctxsys.context
PARAMETERS ('datastore ctxsys.file_datastore format column ot_format');
이 구문은 인덱싱 프로세스가 베이스 테이블에 저장된 경로 정보를 이용하여 파일 시스템에서 파일을 인출하고, 그 컨텐트에 대한 필터링, 인덱싱을 수행하도록 지시하고 있습니다. CONTEXT 인덱스는 대소문자를 구분하지 않으며 정확한 단어 단위 매칭을 지원합니다. 여기서 인덱싱 프로세스의 커스터마이즈 작업을 통해 접두어(prefix), 접미어(suffix) 매치 등을 지원할 수 있습니다.
필터링은 대부분의 경우 각 파일의 포맷을 명시하지 않은 상태에서도 올바르게 동작하지만, format 컬럼을 베이스 테이블에 포함시킴으로써 인덱싱 프로세스를 보다 정교하게 제어할 수 있다는 장점이 있습니다. 예를 들어, format 컬럼을 이용하여 특정 파일 타입이 인덱싱되지 않도록 설정하는 것이 가능합니다. 이 옵션은 Oracle Text에서 파일 포맷 중 일부만을 지원하고자 하는 경우에 특히 유용합니다.
Oracle Text는 메타데이터의 전체 텍스트 검색을 위해서도 이용될 수 있습니다. 샘플 애플리케이션에서는 각 이슈에 관련한 메타데이터를 저장하기 위해 issues 테이블이 사용되고 있습니다. 이 테이블은 아래와 같이 정의됩니다.
CREATE TABLE issues (
id NUMBER,
author VARCHAR(80),
summary VARCHAR(120),
description CLOB,
ot_version VARCHAR(10)
);
The ot_version column is the index column, which can be used to force reindexing for certain documents. The table can be populated with test data:
INSERT INTO issues VALUES (1, 'Jane', 'Text does not make tea',
'Oracle Text is unable to make morning tea', 1);
INSERT INTO issues VALUES (2, 'John', 'It comes in the wrong color',
'I want to have Text in pink', 1);
사용자 인덱스
Oracle Text는 서로 다른 데이터 소스로부터의 데이터 인덱싱을 지원합니다. 샘플 애플리케이션에서 이슈 메타데이터의 전체 텍스트 검색을 위해 Oracle Text를 활용할 수 있습니다. 디폴트 상태에서 인덱스 값은 단일 컬럼에 저장됩니다. 하지만 여러 테이블의 데이터를 조합하고자 하는 경우라면 커스텀 PL/SQL 필터 프로시저를 생성해야 합니다. 여기에서는 스토리지 추상화(storage abstraction)의 한 방법으로서 프로시저를 생성하여 활용하기로 합니다. 인덱싱 프로세스는 텍스트 테이블의 모든 로우를 스캔하고, 각 로우에 대해 필터 프로시저를 호출합니다. 그런 다음 필터 프로시저는 해당 이슈에 관련하여 인덱싱 되어야 하는 모든 텍스트를 반환합니다.
-- declare indexing procedure
CREATE PACKAGE ot_search AS
PROCEDURE issue_filter(rid IN ROWID, tlob IN OUT NOCOPY CLOB);
END ot_search;
/
-- define indexing procedure
CREATE PACKAGE BODY ot_search AS
PROCEDURE issue_filter(rid IN ROWID, tlob IN OUT NOCOPY CLOB) IS
BEGIN
FOR c1 IN (SELECT author, summary, description FROM issues WHERE rowid = rid)
CREATE INDEX issue_index ON issues(ot_version) INDEXTYPE IS ctxsys.context
PARAMETERS ('datastore issue_store');
검색
CONTAINS 연산자는 CONTEXT 인덱스의 검색을 위해 사용됩니다. 본 예제에서는 키워드의 조합을 위해 간단한 불리언 연산자만을 이용하고 있습니다. 하지만 CONTAINS 연산자는 사운덱스(soundex) 매치와 같은 고급 기능도 함께 제공하고 있음을 참고하시기 바랍니다. Oracle Text에 의해 지원되는 언어가 사용되고 있는 경우, 퍼지(fuzzy) 매칭과 스테밍(stemming)이 디폴트로 활성화됩니다. CONTAINS 연산자와 함께 fuzzy(), $ 등의 쿼리 연산자를 이용하여 이러한 고급 기능을 쉽게 활용할 수 있습니다. 접두어/접미어 매칭을 위해 CONTAINS 쿼리에 와일드카드 문자를 활용할 수도 있습니다. 간단한 검색 쿼리의 예가 아래와 같습니다.
SELECT id FROM issues WHERE CONTAINS(ot_version, 'color AND pink', 1) > 0;
SELECT id FROM issues WHERE CONTAINS(ot_version, 'jane OR john', 1) > 0;
인덱스의 유지 보수
베이스 테이블 데이터는 인덱스에 의해 복제되므로, 인덱스와 데이터를 주기적으로 동기화하는 작업이 필요합니다. 인덱스 유지 보수 프로시저는 CTX_DDL PL/SQL 패키지에 포함되어 있습니다. 베이스 테이블의 변경 사항을 반영하여 인덱스를 업데이트하는 예가 아래와 같습니다.
EXECUTE ctx_ddl.sync_index('issue_index', '2M');
동기화 프로시저는 인덱스 네임과 작업에 사용되는 메모리 사이즈를 입력 매개변수로 받아 들입니다. 데이터베이스에서 이 작업을 일정 간격으로 자동 실행하도록 설정하는 것도 물론 가능합니다. 또 운영 체제 또는 다른 스케줄링 기능을 통해 동기화 작업을 실행할 수도 있습니다. UNIX 시스템의 경우 아래와 같은 쉘 스크립트를 Cron 작업 스케줄링 시스템에 등록하여 동기화를 수행할 수 있습니다.
#!/bin/sh
export ORACLE_SID=orcl
export ORAENV_ASK=NO
source /usr/local/bin/oraenv
sqlplus ot1/ot1@XE > synch.log <<EOF
WHENEVER SQLERROR EXIT 5;
EXECUTE ctx_ddl.sync_index('issue_index', '2M');
EOF
그 밖에도 CTX_DDL 패키지에는 인덱스 최적화, 인덱스 조각 모음, 데이터 폐기 등에 관련한 유용한 프로시저들이 포함되어 있습니다.
문제가 발생한 경우에는 CTX_USER_INDEX_ERROR 뷰에서 인덱싱 에러를 추적할 수 있습니다.
데이터베이스는 인덱스 컬럼의 변경 결과를 기준으로 문서의 변경 여부를 추적합니다. 따라서 Oracle Text에서 특정 문서의 인덱스를 재생성해야 하는 경우, 해당 로우의 인덱스 컬럼을 아래와 같은 방법으로 업데이트할 수 있습니다.
이번 호의 Ask Tom 컬럼은 지금까지와는 조금 다른 내용을 담고 있습니다. 필자는 오라클 데이터베이스에서 Top-N 쿼리와 페이지네이션(pagination) 쿼리를 구현하는 방법에 대해 자주 질문을 받곤 합니다. 하나의 컬럼을 통해 이러한 질문에 한꺼번에 대답하기 위한 방편으로, < Effective Oracle by Design (Oracle Press, 2003)> 의 내용을 인용하기로 했습니다. 컬럼의 포맷에 맞게 책의 내용이 다소 수정되었음을 참고하시기 바랍니다.
결과 셋의 제한
ROWNUM은 오라클 데이터베이스가 제공하는 마술과도 같은 컬럼입니다. 이 때문에 많은 사용자들이 문제를 겪기도 합니다. 하지만 그 원리와 활용 방법을 이해한다면 매우 유용하게 사용할 수 있습니다. 필자는 주로 두 가지 목적으로 ROWNUM을 사용합니다.
Top-N 프로세싱: 이 기능은 다른 일부 데이터베이스가 제공하는 LIMIT 구문과 유사합니다.
쿼리 내에서의 페이지네이션(pagination) – 특히 웹과 같은 "stateless" 환경에서 자주 활용됩니다. 필자는 asktom.oracle.com 웹 사이트에서도 이 테크닉을 사용하고 있습니다.
두 가지 활용 방안을 설명하기 전에, 먼저 ROWNUM의 동작 원리에 대해 살펴 보기로 하겠습니다
ROWNUM의 동작 원리
ROWNUM은 쿼리 내에서 사용 가능한 (실제 컬럼이 아닌) 가상 컬럼(pseudocolumn)입니다. ROWNUM에는 숫자 1, 2, 3, 4, ... N의 값이 할당됩니다. 여기서 N 은 ROWNUM과 함께 사용하는 로우의 수를 의미합니다. ROWNUM의 값은 로우에 영구적으로 할당되지 않습니다(이는 사람들이 많이 오해하는 부분이기도 합니다). 테이블의 로우는 숫자와 연계되어 참조될 수 없습니다. 따라서 테이블에서 "row 5"를 요청할 수 있는 방법은 없습니다. "row 5"라는 것은 존재하지 않기 때문입니다.
또 ROWNUM 값이 실제로 할당되는 방법에 대해서도 많은 사람들이 오해를 하고 있습니다. ROWNUM 값은 쿼리의 조건절이 처리되고 난 이후, 그리고 sort, aggregation이 수행되기 이전에 할당됩니다. 또 ROWNUM 값은 할당된 이후에만 증가(increment) 됩니다. 따라서 아래 쿼리는 로우를 반환하지 않습니다.
select *
from t
where ROWNUM > 1;
첫 번째 로우에 대해 ROWNUM > 1의 조건이 True가 아니기 때문에, ROWNUM은 2로 증가하지 않습니다. 아래와 같은 쿼리를 생각해 봅시다.
select ..., ROWNUM
from t
where <where clause>
group by <columns>
having <having clause>
order by <columns>;
이 쿼리는 다음과 같은 순서로 처리됩니다.
1. FROM/WHERE 절이 먼저 처리됩니다. 2. ROWNUM이 할당되고 FROM/WHERE 절에서 전달되는 각각의 출력 로우에 대해 증가(increment) 됩니다. 3. SELECT가 적용됩니다. 4. GROUP BY 조건이 적용됩니다. 5. HAVING이 적용됩니다. 6. ORDER BY 조건이 적용됩니다.
따라서 아래와 같은 쿼리는 에러가 발생할 수 밖에 없습니다.
select *
from emp
where ROWNUM <= 5
order by sal desc;
이 쿼리는 가장 높은 연봉을 받는 다섯 명의 직원을 조회하기 위한 Top-N 쿼리로 작성되었습니다. 하지만 실제로 쿼리는 5 개의 레코드를 랜덤하게(조회되는 순서대로) 반환하고 salary를 기준으로 정렬합니다. 이 쿼리를 위해서 사용되는 가상코드(pseudocode)가 아래와 같습니다.
ROWNUM = 1
for x in
( select * from emp )
loop
exit when NOT(ROWNUM <= 5)
OUTPUT record to temp
ROWNUM = ROWNUM+1
end loop
SORT TEMP
위에서 볼 수 있듯 처음의 5 개 레코드를 가져 온후 바로 sorting이 수행됩니다. 쿼리에서 "WHERE ROWNUM = 5" 또는 "WHERE ROWNUM > 5"와 같은 조건은 의미가 없습니다. 이는 ROWNUM 값이 조건자(predicate) 실행 과정에서 로우에 할당되며, 로우가 WHERE 조건에 의해 처리된 이후에만 increment 되기 때문입니다.
올바르게 작성된 쿼리가 아래와 같습니다.
select *
from
( select *
from emp
order by sal desc )
where ROWNUM <= 5;
위 쿼리는 salary를 기준으로 EMP를 내림차순으로 정렬한 후, 상위의 5 개 레코드(Top-5 레코드)를 반환합니다. 아래에서 다시 설명되겠지만, 오라클 데이터베이스가 실제로 전체 결과 셋을 정렬하지 않습니다. (오라클 데이터베이스는 좀 더 지능적인 방식으로 동작합니다.) 하지만 사용자가 얻는 결과는 동일합니다.
ROWNUM을 이용한 Top-N 쿼리 프로세싱
일반적으로 Top-N 쿼리를 실행하는 사용자는 다소 복잡한 쿼리를 실행하고, 그 결과를 정렬한 뒤 상위의 N 개 로우만을 반환하는 방식을 사용합니다. ROWNUM은 Top- N쿼리를 위해 최적화된 기능을 제공합니다. ROWNUM을 사용하면 대량의 결과 셋을 정렬하는 번거로운 과정을 피할 수 있습니다. 먼저 그 개념을 살펴보고 예제를 통해 설명하기로 하겠습니다.
아래와 같은 쿼리가 있다고 가정해 봅시다.
select ...
from ...
where ...
order by columns;
또 이 쿼리가 반환하는 데이터가 수천 개, 수십만 개, 또는 그 이상에 달한다고 가정해 봅시다. 하지만 사용자가 실제로 관심 있는 것은 상위 N개(Top 10, Top 100)의 값입니다. 이 결과를 얻기 위한 방법에는 두 가지가 있습니다.
클라이언트 애플리케이션에서 쿼리를 실행하고 상위 N 개의 로우만을 가져오도록 명령
• 쿼리를 인라인 뷰(inline view)로 활용하고, ROWNUM을 이용하여 결과 셋을 제한 (예: SELECT * FROM (your_query_here) WHERE ROWNUM <= N)
두 번째 접근법은 첫 번째에 비해 월등한 장점을 제공합니다. 그 이유는 두 가지입니다. 첫 번째로, ROWNUM을 사용하면 클라이언트의 부담이 줄어듭니다. 데이터베이스에서 제한된 결과 값만을 전송하기 때문입니다. 두 번째로, 데이터베이스에서 최적화된 프로세싱 방법을 이용하여 Top N 로우를 산출할 수 있습니다. Top-N 쿼리를 실행함으로써, 사용자는 데이터베이스에 추가적인 정보를 전달하게 됩니다. 그 정보란 바로 "나는N 개의 로우에만 관심이 있고, 나머지에 대해서는 관심이 없다"는 메시지입니다. 이제, 정렬(sorting) 작업이 데이터베이스 서버에서 어떤 원리로 실행되는지 설명을 듣고 나면 그 의미를 이해하실 수 있을 것입니다. 샘플 쿼리에 위에서 설명한 두 가지 접근법을 적용해 보기로 합시다.
select *
from t
order by unindexed_column;
여기서 T가 1백만 개 이상의 레코드를 저장한 큰 테이블이라고, 그리고 각각의 레코드가 100 바이트 이상으로 구성되어 있다고 가정해 봅시다. 그리고 UNINDEXED_COLUMN은 인덱스가 적용되지 않은 컬럼이라고, 또 사용자는 상위 10 개의 로우에만 관심이 있다고 가정하겠습니다. 오라클 데이터베이스는 아래와 같은 순서로 쿼리를 처리합니다.
1. T에 대해 풀 테이블 스캔을 실행합니다. 2. UNINDEXED_COLUMN을 기준으로 T를 정렬합니다. 이 작업은 "full sort"로 진행됩니다. 3. Sort 영역의 메모리가 부족한 경우 임시 익스텐트를 디스크에 스왑하는 작업이 수행됩니다. 4. 임시 익스텐트를 병합하여 상위 10 개의 레코드를 확인합니다. 5.쿼리가 종료되면 임시 익스텐트에 대한 클린업 작업을 수행합니다. .
결과적으로 매우 많은 I/O 작업이 발생합니다. 오라클 데이터베이스가 상위 10 개의 로우를 얻기 위해 전체 테이블을 TEMP 영역으로 복사했을 가능성이 높습니다.
그럼 다음으로, Top-N 쿼리를 오라클 데이터베이스가 개념적으로 어떻게 처리할 수 있는지 살펴 보기로 합시다.
select *
from
(select *
from t
order by unindexed_column)
where ROWNUM < :N;
오라클 데이터베이스가 위 쿼리를 처리하는 방법이 아래와 같습니다.
1. 앞에서와 마찬가지로 T에 대해 풀-테이블 스캔을 수행합니다(이 과정은 피할 수 없습니다). 2. :N 엘리먼트의 어레이(이 어레이는 메모리에 저장되어 있을 가능성이 높습니다)에서 :N 로우만을 정렬합니다.
상위N 개의 로우는 이 어레이에 정렬된 순서로 입력됩니다. N +1 로우를 가져온 경우, 이 로우를 어레이의 마지막 로우와 비교합니다. 이 로우가 어레이의 N +1 슬롯에 들어가야 하는 것으로 판명되는 경우, 로우는 버려집니다. 그렇지 않은 경우, 로우를 어레이에 추가하여 정렬한 후 기존 로우 중 하나를 삭제합니다. Sort 영역에는 최대 N 개의 로우만이 저장되며, 따라서 1 백만 개의 로우를 정렬하는 대신N 개의 로우만을 정렬하면 됩니다.
이처럼 간단한 개념(어레이의 활용, N개 로우의 정렬)을 이용하여 성능 및 리소스 활용도 면에서 큰 이익을 볼 수 있습니다. (TEMP 공간을 사용하지 않아도 된다는 것을 차치하더라도) 1 백만 개의 로우를 정렬하는 것보다 10 개의 로우를 정렬하는 것이 메모리를 덜 먹는다는 것은 당연합니다.
아래의 테이블 T를 이용하면, 두 가지 접근법이 모두 동일한 결과를 제공하지만 사용되는 리소스는 극적인 차이를 보임을 확인할 수 있습니다.
create table t
as
select dbms_random.value(1,1000000)
id,
rpad('*',40,'*' ) data
from dual
connect by level <= 100000;
begin
dbms_stats.gather_table_stats
( user, 'T');
end;
/
Now enable tracing, via
exec
dbms_monitor.session_trace_enable
(waits=>true);
And then run your top-N query with ROWNUM:
select *
from
(select *
from t
order by id)
where rownum <= 10;
마지막으로 상위 10 개의 레코드만을 반환하는 쿼리를 실행합니다.
declare
cursor c is
select *
from t
order by id;
l_rec c%rowtype;
begin
open c;
for i in 1 .. 10
loop
fetch c into l_rec;
exit when c%notfound;
end loop;
close c;
end;
/
이 쿼리를 실행한 후, TKPROF를 사용해서 트레이스 결과를 확인할 수 있습니다. 먼저 Top-N 쿼리 수행 후 확인한 트레이스 결과가 Listing 1과 같습니다.
Code Listing 1: ROWNUM을 이용한 Top-N 쿼리
select *
from
(select *
from t
order by id)
where rownum <= 10
call count cpu elapsed disk query current rows
-------- -------- ------- ------- ------- -------- -------- ------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.04 0.04 0 949 0 10
-------- -------- ------- ------- ------- -------- -------- ------
total 4 0.04 0.04 0 949 0 10
Rows Row Source Operation
----------------- ---------------------------------------------------
10 COUNT STOPKEY (cr=949 pr=0 pw=0 time=46997 us)
10 VIEW (cr=949 pr=0 pw=0 time=46979 us)
10 SORT ORDER BY STOPKEY (cr=949 pr=0 pw=0 time=46961 us)
100000 TABLE ACCESS FULL T (cr=949 pr=0 pw=0 time=400066 us)
이 쿼리는 전체 테이블을 읽어 들인 후, SORT ORDER BY STOPKEY 단계를 이용해서 임시 공간에서 사용되는 로우를 10 개로 제한하고 있습니다. 마지막 Row Source Operation 라인을 주목하시기 바랍니다. 쿼리가 949 번의 논리적 I/O를 수행했으며(cr=949), 물리적 읽기/쓰기는 전혀 발생하지 않았고(pr=0, pw=0), 불과 400066 백만 분의 일초 (0.04 초) 밖에 걸리지 않았습니다. 이 결과를 Listing 2의 실행 결과와 비교해 보시기 바랍니다.
Code Listing 2: ROWNUM을 사용하지 않은 쿼리
SELECT * FROM T ORDER BY ID
call count cpu elapsed disk query current rows
-------- -------- ------- ------- ------- -------- -------- ------
Parse 1 0.00 0.00 0 0 0 0
Execute 2 0.00 0.00 0 0 0 0
Fetch 10 0.35 0.40 155 949 6 10
-------- -------- ------- ------- ------- -------- -------- ------
total 13 0.36 0.40 155 949 6 10
Rows Row Source Operation
----------------- ---------------------------------------------------
10 SORT ORDER BY (cr=949 pr=155 pw=891 time=401610 us)
100000 TABLE ACCESS FULL T (cr=949 pr=0 pw=0 time=400060 us)
Elapsed times include waiting for the following events:
Event waited on Times
------------------------------ ------------
direct path write temp 33
direct path read temp 5
결과가 완전히 다른 것을 확인하실 수 있습니다. "elapsed/CPU time"이 크게 증가했으며, 마지막 Row Source Operation 라인을 보면 그 이유를 이해할 수 있습니다. 정렬 작업은 디스크 상에서 수행되었으며, 물리적 쓰기(physical write) 작업이 "pw=891"회 발생했습니다. 또 다이렉트 경로를 통한 읽기/쓰기 작업이 발생했습니다. (10 개가 아닌) 100,000 개의 레코드가 디스크 상에서 정렬되었으며, 이로 인해 쿼리의 실행 시간과 런타임 리소스가 급증하였습니다.
ROWNUM을 이용한 페이지네이션
필자가 ROWNUM을 가장 즐겨 사용하는 대상이 바로 페이지네이션(pagination)입니다. 필자는 결과 셋의 로우 N 에서 로우 M까지를 가져오기 위해 ROWNUM을 사용합니다. 쿼리의 일반적인 형식이 아래와 같습니다.
select *
from ( select /*+ FIRST_ROWS(n) */
a.*, ROWNUM rnum
from ( your_query_goes_here,
with order by ) a
where ROWNUM <=
:MAX_ROW_TO_FETCH )
where rnum >= :MIN_ROW_TO_FETCH;
where
여기서,
FIRST_ROWS(N)는 옵티마이저에게 "나는 앞부분의 로우에만 관심이 있고, 그 중 N 개를 최대한 빨리 가져오기를 원한다"는 메시지를 전달하는 의미를 갖습니다.
:MAX_ROW_TO_FETCH는 결과 셋에서 가져올 마지막 로우로 설정됩니다. 결과 셋에서 50 번째 – 60 번째 로우만을 가져오려 한다면 이 값은 60이 됩니다.
:MIN_ROW_TO_FETCH는 결과 셋에서 가져올 첫 번째 로우로 설정됩니다. 결과 셋에서 50 번째 – 60 번째 로우만을 가져오려 한다면 이 값은 50이 됩니다.
이 시나리오는 웹 브라우저를 통해 접속한 사용자가 검색을 마치고 그 결과를 기다리고 있는 상황을 가정하고 있습니다. 따라서 첫 번째 결과 페이지(그리고 이어서 두 번째, 세 번째 결과 페이지)를 최대한 빨리 반환해야 할 것입니다. 쿼리를 자세히 살펴 보면, (처음의 :MAX_ROW_TO_FETCH 로우를 반환하는) Top-N 쿼리가 사용되고 있으며, 따라서 위에서 설명한 최적화된 기능을 이용할 수 있음을 알 수 있습니다. 또 네트워크를 통해 클라이언트가 관심을 갖는 로우만을 반환하며, 조회 대상이 아닌 로우는 네트워크로 전송되지 않습니다.
페이지네이션 쿼리를 사용할 때 주의할 점이 하나 있습니다. ORDER BY 구문은 유니크한 컬럼을 대상으로 적용되어야 합니다. 유니크하지 않은 컬럼 값을 대상으로 정렬을 수행해야 한다면 ORDER BY 조건에 별도의 조건을 추가해 주어야 합니다. 예를 들어 SALARY를 기준으로 100 개의 레코드를 정렬하는 상황에서 100 개의 레코드가 모두 동일한 SALARY 값을 갖는다면, 로우의 수를 20-25 개로 제한하는 것은 의미가 없을 것입니다. 여러 개의 중복된 ID 값을 갖는 작은 테이블을 예로 들어 설명해 보겠습니다.
SQL> create table t
2 as
3 select mod(level,5) id,
trunc(dbms_random.value(1,100)) data
4 from dual
5 connect by level <= 10000;
Table created.
ID 컬럼을 정렬한 후 148-150 번째 로우, 그리고 148–151 번째 로우를 쿼리해 보겠습니다.
SQL> select *
2 from
3 (select a.*, rownum rnum
4 from
5 (select id, data
6 from t
7 order by id) a
8 where rownum <= 150
9 )
10 where rnum >= 148;
ID DATA RNUM
------- ---------- -----------
0 38 148
0 64 149
0 53 150
SQL>
SQL> select *
2 from
3 (select a.*, rownum rnum
4 from
5 (select id, data
6 from t
7 order by id) a
8 where rownum <= 151
9 )
10 where rnum >= 148;
ID DATA RNUM
------- ---------- -----------
0 59 148
0 38 149
0 64 150
0 53 151
로우 148의 경우 DATA=38의 결과가 반환되었습니다. 두 번째 쿼리에서는 DATA=59의 결과가 반환되었습니다. 두 가지 쿼리 모두 올바른 결과를 반환하고 있습니다. 쿼리는 데이터를 ID 기준으로 정렬한 후 앞부분의 147 개 로우를 버린 후 그 다음의 3 개 또는 4 개의 로우를 반환합니다. 하지만 ID에 중복값이 너무 많기 때문에, 쿼리는 항상 동일한 결과를 반환함을 보장할 수 없습니다. 이 문제를 해결하려면 ORDER BY 조건에 유니크한 값을 추가해 주어야 합니다. 위의 경우에는 ROWID를 사용하면 됩니다.
SQL> select *
2 from
3 (select a.*, rownum rnum
4 from
5 (select id, data
6 from t
7 order by id, rowid) a
8 where rownum <= 150
9 )
10 where rnum >= 148;
ID DATA RNUM
------- ---------- -----------
0 45 148
0 99 149
0 41 150
SQL>
SQL> select *
2 from
3 (select a.*, rownum rnum
4 from
5 (select id, data
6 from t
7 order by id, rowid) a
8 where rownum <= 151
9 )
10 where rnum >= 148;
ID DATA RNUM
------- ---------- -----------
0 45 148
0 99 149
0 41 150
0 45 151
이제 쿼리를 반복 실행해도 동일한 결과를 보장할 수 있게 되었습니다. ROWID는 테이블 내에서 유니크한 값을 가집니다. 따라서 ORDER BY ID 조건과 ORDER BY ROWID 기준을 함께 사용함으로써 사용자가 기대한 순서대로 페이지네이션 쿼리의 결과를 확인할 수 있습니다.
데이터베이스가 대용량으로 변화면서 우리는 항상 성능을 고민하게 된다. 이는 많은 데이터 중 우리가 원하는 데이터를 추출하는 것이 말처럼 쉽지만은 않기 때문이다. 이와 같은 현상은 데이터가 증가하면 증가할수록 더욱 심해질 것이다. 그래서 대용량의 데이터에서 우리가 원하는 적은 데이터를 추출하기 위해 인덱스를 이용하게 된다. 보통 인덱스는 결합 칼럼 인덱스나 단일 칼럼 인덱스로 구성할 수 있다. 그렇다면 과연 우리는 어떤 형태의 인덱스를 선택해야 할까? 결론부터 말하자면 대부분의 SQL에서는 결합 칼럼 인덱스를 선택하는 편이 좋다. 이제부터 그 이유에 대해 알아보자.
권순용 | kwontra@hanmail.net
SQL의 성능은 무엇에 의해 좌우되는가? 여러 가지 요소에 의해 SQL의 성능은 좌우될 것이다. SQL의 성능은 다음의 세 가지 항목에 의해 좌우된다.
● 처리 범위의 양 ● 랜덤 액세스의 양 ● 정렬의 양
그 럼 처리 범위가 적다는 뜻은 무엇을 의미할까? 처리 범위가 적다는 말은 액세스해야 하는 데이터가 적다는 것을 의미한다. 액세스해야 하는 데이터가 적다면 우리는 인덱스를 이용하여 성능을 보장 받을 수 있을 것이다. 이는 마치 우리가 사전에서 GIRL이라는 단어를 찾을 때 사전의 인덱스를 이용하여 찾는 것과 같을 것이다. 다음 예제를 확인해 보자.
SQL> SELECT 카드번호, 사용액 FROM 거래내역 WHERE 거래일자 = ‘200803’ AND 사용_구분 = ‘정상’;
여기에서 인덱스에 의한 처리 범위를 확인해 보자. 그렇다면 위의 SQL을 위해 생성할 수 있는 인덱스의 종류는 어떻게 되는가?
거 래일자 인덱스를 이용한다면 처리 범위는 거래일자 칼럼에 의해서만 감소하게 된다. 따라서, 거래일자 칼럼의 값이 ‘200803’인 데이터를 모두 액세스할 것이다. 액세스한 데이터에 대해 사용_구분 칼럼의 값이 ‘정상’인 데이터만을 결과로 추출하게 된다. 결국, 거래일자 칼럼에 의해서만 처리 범위가 감소하게 되며 사용_구분 칼럼에 의해서는 처리 범위가 감소하지 않게 된다.
사용_구분 인덱스 사 용_구분 칼럼으로 인덱스를 생성하면 사용_구분 칼럼의 값이 ‘정상’인 모든 데이터를 액세스한다. 거래일자 칼럼의 값은 처리 범위를 감소시키기 위한 어떠한 역할도 수행하지 않게 된다. 결국, 사용_구분 인덱스로 인덱스를 생성하게 되면 사용_구분 칼럼의 값만으로 처리 범위가 감소하게 된다.
거래일자+사용_구분 인덱스 해당 인덱스는 거래일자 칼럼의 값이 ‘200703’인 데이터 중 사용_구분 칼럼의 값이 ‘정상’인 데이터만 액세스한다. 거래일자+사용_구분 인덱스를 이용하는 순간 처리 범위는 거래일자 칼럼에 의해 감소하게 되며 감소된 처리 범위에서 사용_구분 칼럼의 값이 ‘정상’인 데이터만을 액세스하게 된다. 거래일자 칼럼과 사용_구분 칼럼에 의해 처리 범위가 감소한다. 따라서, 앞서 언급한 단일 칼럼 인덱스에 비해 처리 범위가 더 많이 감소하게 되므로 성능은 더욱 향상될 것이다.
사용_구분+거래일자 인덱스 세 번째 인덱스와 마찬가지로 사용_구분 칼럼의 값이 ‘정상’인 데이터 중에 거래일자 칼럼의 값이 ‘200803’인 데이터만을 추출하게 된다. 따라서, 해당 인덱스도 사용_구분 칼럼과 거래일자 칼럼에 의해 동시에 처리 범위가 감소하게 된다. 이와 같이 결합 칼럼 인덱스를 생성한다면 처리 범위를 더 많이 감소시킬 수 있게 된다. 이와 같은 이유에서 단일 칼럼 인덱스보다는 결합 칼럼 인덱스를 생성하는 것이 해당 SQL에 대해 더 빠른 성능을 기대할 수 있게 한다.
WHERE 절에 사용되는 연산자
그렇다면 WHERE 조건에 존재하는 모든 칼럼으로 순서에 상관 없이 결합 칼럼 인덱스를 생성하면 인덱스를 구성하는 모든 칼럼에 의해 처리 범위가 감소하게 되는가? 당연히 그것은 아니다. 이를 이해하려면 WHERE 절에 사용하는 연산자의 종류를 이해해야 한다.
● 점 조건 : IN, = 연산자를 이용한 조건을 의미하며 해당 연산자는 하나의 점만을 의미하게 된다. ● 선분 조건 : LIKE, BETWEEN, <, > 등과 같이 점 조건을 제외한 연산자를 사용한 조건을 의미한다. 선분 조건은 하나의 점만을 의미하는 것이 아니면 해당 조건을 만족하는 모든 실수를 의미하게 된다. WHERE 절에 사용하는 조건은 점 조건과 선분 조건으로 구분된다. 이와 같이 조건에 사용된 연산자에 의해 액세스해야 하는 처리 범위의 차이가 발생한다. ● 점 조건+점 조건 : 두 조건에 의해 처리 범위 감소 ● 점 조건+선분 조건 : 두 조건에 의해 처리 범위 감소 ● 선분 조건+선분 조건 : 앞의 선분 조건에 의해 처리 범위 감소 ● 선분 조건+점 조건 : 앞의 선분 조건에 의해서만 처리 범위 감소
이 내용은 간단하지만 매우 중요한 의미를 내포하고 있다. 예를 들어 확인해 보자.
SQL> SELECT 카드번호, 사용액 FROM 거래내역 WHERE 거래일자 > ‘200803’ AND 사용_구분 = ‘정상’;
이 런 SQL을 수행한다면 앞서 언급한대로 거래일자 조건은 선분 조건이며 사용_구분 조건은 점 조건이 된다. 따라서, 해당 SQL에 대해 최적의 인덱스를 이용하고자 한다면 사용_구분+거래일자 인덱스를 생성해야 한다. 이와 같이 인덱스를 생성한다면 점 조건+선분 조건으로 구성되므로 두 개의 조건에 의해 처리 범위가 감소하게 된다. 이와 같은 현상이 왜 발생하는지는 다음 호에서 자세히 언급하도록 하겠다. 인덱스에서 가장 중요한 요소는 처리 범위를 최소화 시킬 수 있어야 한다는 것이다. 그 중심에는 결합 칼럼 인덱스가 존재한다는 것을 명심하길 바란다. 또한, 결합 칼럼 인덱스를 생성하고자 한다면 점 조건과 선분 조건의 순서에 의해 처리 범위가 변한다는 것에 주의해야 할 것이다.
많은 기업들이 서로 다른 부서, 지역, 지사 별로 다양한 이기종 애플리케이션을 운영하고 있습니다. 비즈니스 조직의 요구사항을 만족하기 위해서는 다수의 ERP 시스템이 필요할 수 있으며, 이로 인해 데이터의 파편화(fragmentation)가 발생할 수 있습니다. 이러한 시스템의 통합 작업은 복잡할 뿐 아니라 비표준적인 방법으로 처리되는 것이 일반적입니다. 또 의사결정을 위해 다수의 ERP 시스템에 존재하는 분산된 정보를 수집하는 과정에서 많은 시간과 노력이 소모되곤 합니다.
BPEL은 이기종 시스템의 통합을 위한 표준적, 프로세스 중심적 방법론을 제공합니다. Oracle BPEL Process Manager는 SOA(service-oriented architecture)의 구현을 위한 Oracle Fusion Middleware의 핵심 툴로써, Microsoft, IBM, SAP, BEA 등에 의해 제안된 이후 통합 프로젝트의 비용, 복잡성 절감 및 유연성 개선을 위한 엔터프라이즈 청사진으로써 활용되고 있는 BPEL 표준을 지원합니다.
이번 BPEL Cookbook 시리즈에서는 BPEL을 이용하여 PeopleSoft 8.9 CRM과 Oracle Application 11i를 통합하는 방법을 설명하기로 합니다. 특히, 샘플 비즈니스 시나리오를 통해 PeopleSoft의 모듈을 웹 서비스의 형태로 공개하고, 오라클 애플리케이션과의 연동을 위해 BPEL Applications 어댑터를 설정하는 방법을 예시하게 될 것입니다.
비즈니스 시나리오
일반적으로 주문 관리 비즈니스 시나리오에서는, 주문이 CRM 시스템에 입력된 후 백-오피스 ERP에 의해 처리되는 과정을 거칩니다. 본 문서의 예제에서는, PeopleSoft를 프론트 애플리케이션으로 사용하여 마케팅, 세일즈, 서비스 업무를 관리하고 Oracle E-Business Suite를 ERP (주문 관리, 인벤토리, 재무) 솔루션으로 사용하고 있습니다. 여기에서는 Quote-to-Order(주문 견적) 프로세스를 중심적으로 다루기로 합니다.
견적 및 주문 입력을 위한 비즈니스 프로세스는 CRM 시스템 상에서 실행되며, 주문 처리 작업은 ERP 시스템을 통해 실행됩니다. 전체 Quote-to-Order 비즈니스 프로세스는 작업 능률의 최적화를 위해 완전 자동화됩니다.
비즈니스 프로세스의 통합 과정에서 구현되는 기능이 다음과 같습니다. (그림 1 참고):
PeopleSoft에서 Sales Orders 생성
PeopleSoft에서 견적을 세일즈 주문으로 변환하거나 Order Capture 스크린을 이용하는 방법으로 세일즈 주문(sales order)가 생성됩니다.
주문이 입력되면, 시스템은 필요한 정보를 점검하고 상태(status)를 OPEN으로 변경합니다. (그렇지 않은 경우 HOLD 상태가 유지됩니다.)
Sales Order Process는 주문 정보를 호출하여 Integration Process에 제출합니다. 이 과정에서 BPEL Process Manager가 호출됩니다.
BPEL Process Manager는 메시지 데이터를 Oracle ERP Order Management 모듈에서 요구하는 포맷으로 변환합니다.
세일즈 주문 생성 작업은 Oracle ERP 애플리케이션 상에서 실행되며, 주문의 실행 결과가 PeopleSoft로 전달.
Oracle ERP의 ATP Check
주문 생성 프로세스가 진행되는 동안, 세일즈 담당자는 발송 일자를 확정하기 위해 재고를 점검할 수 있습니다.
PeopleSoft CRM은 ERP 애플리케이션에 동기식 호출을 발생시키고, Item/Product Availability 질의 컴포넌트를 이용하여 현재 사용 가능한 물량을 확인합니다.
BPEL Process Manager는 ATP Check 요청을 Oracle ERP에 전달합니다.
Oracle ERP는 해당 아이템의 수량을 인벤토리에서 확인한 후, 상세 정보를 BPEL Process Manager에 전달합니다.
BPEL Process Manager는 ATP 응답 정보를 PeopleSoft CRM에 전달합니다. 이 작업 결과에 따라, 고객에게 발송 가능 일자를 전달합니다.
주문 상태의 업데이트 정보를 Oracle ERP에서 PeopleSoft CRM으로 전달
세일즈 주문이 ERP 애플리케이션으로 전달되면, 주문은 ERP에서 예약 처리되고, 그 결과가 BPEL Process를 거쳐 PeopleSoft CRM 시스템으로 전달됩니다. PeopleSoft CRM 시스템은 주문 상태(order status)를 “In Process"로 변경합니다.
Oracle ERP는 주문 상태가 변경될 때마다 그 내역을 CRM으로 전달합니다. ERP의 상태 정보는 CRM 상의 대응되는 상태 정보로 매핑됩니다.
비즈니스 프로세스를 개략적으로 이해했다면, 이제 아키텍처에 대해 살펴보기로 합시다. 그림 2는 Oracle BPEL Process Manager를 플랫폼으로 하여 PeopleSoft CRM과 오라클 애플리케이션을 통합한 환경의 하이 레벨 아키텍처를 예시하고 있습니다.
그림 2
Enterprise Integration Point (EIP)란 PeopleSoft 애플리케이션이 써드 파티 시스템 또는 다른 PeopleSoft 소프트웨어와 연동하기 위해 사용되는 웹 서비스 연결입니다. PeopleSoft CRM에 주문이 입력되면, PeopleSoft의 EIP가 주문을 XML 포맷으로 변환합니다. 그런 다음 Order XML이 PeopleCode 메소드(WSDL_ORDER)로 전달됩니다. (PeopleCode는 비즈니스 룰 구현, 또는 기타 커스터마이즈 작업을 위해 사용되는 PeopleSoft의 프로그래밍 언어입니다.) WSDL_ORDER는 수신된 Order XML을 SOAP XML로 변환하고 PeopleSoft 원격 노드에 요청을 전달합니다. 원격 노드(remote node)란 BPEL Process Manager의 웹 서비스와 핸드쉐이크(handshake) 작업을 수행하는 노드를 의미합니다.
WSIF(Web Service Invocation Framework) 바인딩을 이용하여 원격 노드를 WSDL로 매핑함으로써 PeopleSoft의 웹 서비스 호출 작업이 수행됩니다. BPEL Process Manager는 WSIF 바인딩을 완벽하게 지원합니다. SOAP XML을 수신한 PeopleSoft 노드는 해당 노드에 임포트 및 설정된 WSDL을 기준으로 웹 서비스를 호출합니다. 그런 다음, 웹 서비스가 BPEL Process Manager에서 호출 및 실행됩니다.
BPEL Process Manager는 데이터를 SOAP XML로 처리하고 오라클 애플리케이션에 전달합니다. 이때 Oracle Applications (OA) Adapter를 이용하여 11i와의 커뮤니케이션을 수행합니다. OA Adapter는 퓨어 JCA 1.5 Resource Adapter로, E-Business Suite 환경의 메시지 전송/수신을 위해 사용됩니다. 오라클 애플리케이션은 이 어댑터를 통해 외부 애플리케이션으로 API 및 테이블의 일부를 노출합니다.
오라클 애플리케이션이 주문을 처리한 후 결과를 전송하면, BPEL Process Manager가 이를 수신하여 PeopleSoft 노드에 전달합니다. PeopleSoft 노드는 웹 서비스를 요청한 PeopleCode에 결과를 전달합니다. PeopleCode는 XML 데이터를 인출하여 PeopleSoft에 구성된 컴포넌트 인터페이스에 전달합니다. 컴포넌트 인터페이스(component interface)란 (Java 또는 PeopleCode로 작성된) 다른 애플리케이션으로부터의 동기식 접근을 위해 PeopleSoft 컴포넌트를 노출하는 인터페이스를 말합니다.
PeopleSoft와 오라클 애플리케이션 간에 이루어지는 Order 데이터의 하이 레벨 플로우가 지금까지 설명한 바와 같습니다. 다음으로, PeopleSoft CRM 모듈을 웹 서비스의 형태로 노출하고, BPEL 프로세스를 구성하고, OA Adapter를 설정하는 방법에 대해 알아 보겠습니다.
PeopleSoft CRM과 Oracle ERP의 통합
주문이 PeopleSoft CRM에 입력되고 나면, 해당 주문에 대한 정보 오라클 애플리케이션으로 전달되어야 합니다. 이 과정에서 세 단계의 작업이 수행됩니다.
Oracle BPEL Process Manager에서 비즈니스 프로세스를 설계합니다.
Oracle Applications Adapter를 설정합니다.
PeopleSoft를 설정합니다.
각 단계별로 자세히 살펴보도록 합시다:
1 단계: BPEL 프로세스의 설계
이 단계에서는 BPEL Designer를 이용하여 프로세스를 생성합니다. BPEL Process Manager는 세일즈 주문 정보를 포함한 SOAP XML을 PeopleSoft로부터 수신하고, 이를 OA Adapter의 XML 포맷으로 변환합니다. (스키마는 호출 API를 위한 파트너 링크가 생성되는 시점에 OA Adapter에 의해 자동으로 생성됩니다.) 그런 다음, OA Adapter Partner 링크가 호출되어 변환 작업을 거친 Order XML이 오라클 애플리케이션으로 전달됩니다. Oracle API는 주문을 처리하고 결과 확인(output acknowledgement) XML을 통해 주문 번호(order number)를 반환합니다.
BPEL Process Manager는 원격 폴트(remote fault) 및 바인딩 폴트(binding fault)를 처리합니다. 연결이 끊어진 경우, 5 차례에 걸쳐 접속이 재시도된 후 익셉션(exception)을 발생시킵니다. 바인딩 익셉션이 발생하고 나면 바인딩 폴트가 자동으로 처리됩니다.
BPEL Process Manager를 위해 설계된 통합 비즈니스 프로세스의 예가 아래와 같습니다.
(이미지를 클릭하면 큰 그림을 보실 수 있습니다)
이 프로세스에서 실행되는 작업이 아래와 같습니다:
Applications > New Application Workspace > New Project > BPEL Process Project 메뉴를 선택합니다.
참고: 위의 경우, BPEL Process Manager가 오라클 레코드 타입을 지원하지 않기 때문에, PROC_ORDERENTRY_ARRAY가 PROCESS_ORDER pre-seeded API를 위한 래퍼(wrapper) API로 사용됩니다. 따라서 PROCESS_ORDER에서 사용된 레코드 타입과 유사한 오브젝트 타입을 래퍼 프로시저(wrapper procedure)에서 사용해야 합니다. 이 인터페이스는 오라클 애플리케이션에서 세일즈 주문을 처리하는 작업을 담당합니다.
이제 WSDL Repository 페이지를 이용하여 WSDL 리포지토리의 WSDL에 액세스할 수 있습니다.
CreateOrder WSDL을 PeopleSoft에 임포트한 다음에는, BPEL 프로세스와의 커뮤니케이션을 위해 원격 노드를 설정해야 합니다. 이를 위해 request message, response message, and message channel를 아래와 같이 추가합니다.
새로운 원격 노드를 생성하는 방법이 아래와 같습니다:
Create a New Node Definition 버튼을 선택합니다.
Node Name 필드에서, BPEL_CREATEORDER를 입력하여 새로운 노드를 정의합니다.
Node Description 필드에 노드에 대한 설명을 입력합니다.
Authentication 드롭다운 리스트에서 인증 방법(None, Certificate, Password)을 선택합니다. (디폴트는 None입니다.)
(옵션) Password 필드에 암호를 입력합니다.
(옵션) Confirm Password 필드에 암호를 다시 입력합니다.
Next 버튼을 클릭하여 WSDL Operation Wizard의 다음 페이지로 진행하여 서비스의 요청/응답 메시지(request/response message)를 선택합니다. 요청/응답 메시지는 PeopleSoft 내부에서 비구조형 메시지로 정의되며 SOAP Request / Response 메시지로 활용됩니다.
새로운 요청/응답 메시지를 생성하는 방법이 아래와 같습니다:
해당 섹션에서 Create a New Message 옵션을 선택합니다.
새로운 요청 메시지를 생성하기 위해 Request Message 섹션의 옵션을 선택합니다. message name 필드에는 BPEL_ORDER_REQ를 입력합니다.
새로운 응답 메시지를 생성하기 위해 Response Message 섹션의 옵션을 선택합니다. message name 필드에는 BPEL_ORDER_RES를 입력합니다.
d. 새로 생성된 메시지의 버전은 디폴트로 VERSION_1로 정의됩니다. PeopleSoft Integration Broker는 이 값을 이용하여 Message Version 필드를 채웁니다.
PeopleSoft Integration Broker는 새로운 메시지 채널에 자동으로 메시지를 할당합니다. 마법사 실행이 완료되면, 새로운 메시지를 이용하여 노드에 아웃바운드 동기식 트랜잭션이 생성됩니다.
channel name 필드의 New Message Channel Name을 BPEL_SERVICES로 입력합니다.
이로써 1 단계가 완료되었습니다. WSDL을 임포트함으로써 어떤 웹 서비스를 호출할 것인지 PeopleSoft에 알리고, 웹 서비스(CreateOrder BPEL Process)에 정보를 전달하기 위한 노드, 메시지, 채널 등을 설정하였습니다. 다음 단계에서는 Sales Order EIP와 새로 설정된 노드 간의 관계를 설정합니다.
2. EIP와 노드 간의 관계 설정
이 단계에서는 CRM_SALES_ORDER EIP와 새로운 노드 간의 링크를 생성합니다. CRM_SALES_ORDER EIP가 Integration Broker를 통해 공개되고, 생성된 링크를 통해 CRM_SALES_ORDER 요청 메시지를 노드에 전달합니다.
이 단계에서는 WSDL_ORDER Application Engine 프로그램을 생성합니다. (Application Engine은 PeopleSoft의 대용량 애플리케이션 프로세서입니다. Application Engine 프로그램은 Application Designer를 통해 작성되며, 레코드, PeopleCode, SQL 오브젝트와 같은 PeopleTool의 기능을 활용할 수 있습니다.) WSDL_ORDER는 EIP로부터 수신된 세일즈 주문 메시지를 BPEL 요청 메시지(SOAP 메시지)로 변환하고 변환된 메시지를 노드 채널로 배포합니다.
아래 코드를 추가하여 요청 메시지를 변환한 후 노드에 전송합니다. 요청이 노드에 전송되고 나면, 노드가 웹 서비스를 호출하는 작업을 수행하게 됩니다. 웹 서비스가 호출되면, XML 메시지를 PeopleCode 메소드로 전송하고 응답 메시지를 노드에 전달하는 작업이 수행됩니다.
/* Get the data from the AE Runtime */
Local TransformData &transformData = %TransformData;
Local File &logFile = GetFile("TestSyncReqResStep3.log", "W", %FilePath_Absolute);
Local string &destNode = &transformData.DestNode;
&logFile.WriteLine("DestNode: " | &destNode);
/* Set a temp object to contain the incoming document */
Local XmlDoc &xmlDoc = &transformData.XmlDoc;
Local string &xmlStr = &xmlDoc.GenXmlString();
&logFile.WriteLine("Transformed XML : " | &xmlStr);
/* Maps the &xmlDoc to the BPEL_ORDER_REQ and publish to the BPEL_CREATEORDER node.
Node will invoke BPEL CreateOrder process.
Response will be assigned to &response variable. */
Local XmlDoc &response = SyncRequestXmlDoc(&xmlDoc, Message.BPEL_ORDER_REQ, Node.BPEL_CREATEORDER);
&logFile.WriteLine("Response XML Data: " | &response.GenXmlString());
&logFile.Close();
4. WSDL_ORDER Application Engine 프로그램과 노드의 연결
이 단계에서는, 변환 코드를 CreateOrder 노드에 연결하는 작업을 수행합니다. 이와 같이 함으로써, BPEL Process Manager가 호출될 때마다 변환 코드가 실행되게 할 수 있습니다.
새로운 WSDL_ORDER 관계(relationship)를 생성하고, 생성된 관계를 WSDL_ORDER 노드에 연결합니다:
People Tools > Integration Setup에서 Relationships을 선택하고 Add New Value를 선택합니다.
Initial Node를 BPEL_CREATEORDER로, CRM_SALES_ORDER를 Request Message로, Transaction Type을 OA로, Result Node를 BPEL_CREATEORDER로, Request Message Name을 CRM_SALES_ORDER로 설정하고 디폴트 버전을 그대로 사용합니다. Add를 클릭합니다.
Transformation Request를 WSDL_ORDER로 설정합니다.
T이로써 Sales Order 생성 작업을 완료하였습니다. 디자인 타임 viewlet을 통해 설정 과정을 다시 한 번 확인하실 수 있습니다. 또 런타임 viewlet에서는 PeopleSoft에 입력된 세일즈 주문이 오라클 애플리케이션으로 전달되는 과정을 확인할 수 있습니다.
결론
각 부서별로 서로 다른 애플리케이션을 사용하는 기업 환경에서 정보를 통합하는 문제가 중요한 이슈로 떠오르고 있습니다. 시스템의 통합에는 많은 비용 투자가 필요합니다. 본 문서에서 제시한 것과 같은 방법을 이용하여 BPEL 표준 기반의 애플리케이션 통합을 수행함으로써 문제를 쉽게 해결하는 것이 가능합니다.
이기종 EAI 환경에 BPEL 추가하기 저자: Praveen Chandran and Arun Poduval
Oracle BPEL Process Manager의 통합(orchestration) 기능을 이용하여 고전적인 EAI 미들웨어를 아우르는 표준 기반 비즈니스 프로세스 통합 환경을 구현하는 방법에 대해 알아봅니다.
오늘날 대부분의 기업은 다수 벤더 제품으로 구성된 다양한 애플리케이션과 플랫폼, 그리고 서로 다른 테크놀로지를 포함하는 고도로 분산된 이기종 애플리케이션 인프라스트럭처를 보유하고 있습니다. 지난 10년 동안에는 TIBCO, webMethods, Vitria, SeeBeyond 등 고전적인 EAI(enterprise application integration) 벤더들이 통합 문제를 해결하기 위한 새로운 솔루션을 출시하는 움직임이 두드러지게 나타나기도 했습니다. 또 지난 몇 년 동안, 많은 기업이 이러한 EAI 솔루션에 많은 투자를 하면서, 기업 환경이 단일 벤더 환경에 종속되고 긴밀하게 커플링된(tightly coupled) 통합 컴포넌트 구성이 일반화되기 시작하였습니다.
이처럼 벤더 종속적인 통합 환경을 유지하고 관리하는 데에는 만만치 않은 비용이 듭니다. 비용과 안정성 문제를 해결하기 위해서는 전문적인 스킬이 요구될 뿐 아니라, 기존 EAI 솔루션을 다른 대안으로 완전하게 대체하려면 막대한 비용을 EAI 영역에 쏟아 부어야 할 수도 있습니다.
BPEL이 제공하는 표준 기반, 플랫폼 중립적인 솔루션을 이용함으로써 이러한 문제를 해결하는 것이 가능합니다. 느슨하게 커플링된(loosely coupled) BPEL 프로세스는 벤더 종속 요소를 제거하고, 통합 비용을 절감하고, 호환성을 개선하는 효과를 제공합니다. 또 보안, 예외 관리, 로깅 등을 위한 계층 구현을 가능하게 합니다. 가장 중요한 사실은 기업들이 기존 인프라스트럭처를 활용하여 서비스를 구현하고 BPEL을 이용하여 전체 서비스를 통합할 수 있다는 점입니다.
“BPEL Cookbook” 시리즈의 이번 연재에서는 Oracle BPEL Process Manager를 이용하여 새로운 통합 솔루션을 개발하고 기존 인프라스트럭처와 인터페이스 하기 위한 아키텍처의 청사진을 제시합니다. 또 TIBCO BusinessWorks와 webMethods에 기반한 이기종 EAI 솔루션을 웹 서비스와 통합하는 사례를 함께 살펴보기로 합니다.
또, 완벽한 비즈니스 프로세스의 구현을 위해서는 용의주도한 에러 관리, 보안, 로깅 프레임워크가 필수적입니다. 여기에서는 BPEL scope와 compensation handler를 이용하여 프로세스의 안정성을 높이고 BPEL 프로세스 및 서비스의 보안을 보장하는 방법에 대해 함께 알아보도록 하겠습니다.
사례 연구 배경정보
EAI는 기존 애플리케이션의 서비스화(service-enabling)을 위한 훌륭한 촉매제 역할을 합니다. 기존 미들웨어 프로세스를 웹 서비스로 공개하고, 이를 다시 BPEL을 통해 통합하는 것이 가능합니다.
아래 다이어그램은 Oracle BPEL Process Manager를 이용하여 기존 EAI 인터페이스와 새로운 애플리케이션을 통합하는 일반적인 접근법을 보여주고 있습니다. 아래에서는 미들웨어가 비즈니스 프로세스를 웹 서비스 형태로 공개할 수 있으며, 애플리케이션 서버 내부적으로 웹 서비스 인터페이스가 구현되어 있다고 가정하고 있습니다.
그림 1 EAI 환경의 Oracle BPEL Process Manager — 전체 개념도
본 문서에서는 두 가지 고전적인 EAI 미들웨어 제품에 대한 사례 연구를 통해, BPEL이 제품간 통합 과정에서 어떤 역할을 담당하는지 알아보기로 하겠습니다.
특정 고객의 “기록 시스템(system of record)”이 고객 데이터가 관리되고 있는 다른 시스템으로 원활하게 전달되지 않는 경우를 자주 찾아볼 수 있습니다. 이러저러한 이유로 기업이 두 가지 벤더의 미들웨어 제품(예: Siebel CRM과 TIBCO BusinessWorks, SAP R/3와 webMethods 등)을 동시에 사용하고 있는 경우를 고려해 봅시다. (그림 2 참고).
그림 2 Customer Details Management Module과 미들웨어 인터페이스
이러한 모델에서는, SAP 시스템과 Siebel 시스템 간의 고객 데이터 불일치로 인한 고객 서비스 수준의 저하, 또는 기업 매출의 저하가 발생할 소지가 높습니다. 따라서, TIBCO 및 webMethods와 다수의 인터페이스 포인트(interfacing point)를 갖는 공통 Customer Details Management Module을 구현함으로써 데이터 일관성을 보장하는 것이 바람직합니다. 예를 들어, Siebel 시스템에 고객 데이터가 접수된 경우, 시스템은 고객이 신규 고객인지 아니면 기존 고객인지 확인한 후 SAP 시스템에 새로운 데이터를 추가하거나 기존 데이터를 업데이트하는 작업을 수행하게 됩니다.
이러한 통합 목표의 달성을 위해 기존 미들웨어 툴(TIBCO와 webMethods)를 이용할 수도 있습니다. 하지만 이 경우 벤더 종속성이 더욱 심화될 뿐 아니라 표준 기반의 통합이 불가능하다는 문제가 있습니다. 따라서 이와 같은 환경을 애플리케이션의 서비스화(service-enabling)를 위한 새로운 기회로 활용하고, 표준 기반, 벤더 중립적인 솔루션을 구현하는 것이 바람직할 것입니다.
표준 기반의 EAI 인터페이스를 구현하기 위한 첫 단계로서, 프로세스를 웹 서비스로 공개하는 작업이 필요합니다. 대부분의 미들웨어 플랫폼은 웹 서비스를 이용한 다른 플랫폼 간의 커뮤니케이션을 지원합니다. 하지만 일련의 인터페이스 서비스를 관련된 비즈니스 로직과 연계해야 하는 경우에는 문제가 복잡해질 수 있습니다.
또 다른 미들웨어 프로세스, 또는 복잡한 Java 코드를 이용하여 웹 서비스를 통합하는 방법을 고려해 볼 수도 있습니다. 하지만 이 경우에도 아래와 같은 기능을 프로세스를 통해 직접 구현해야 한다는 문제가 남습니다:
병렬 웹 서비스 호출
비동기식 웹 서비스 호출
서비스 간의 느슨한 커플링(loose coupling) 및 호환성
표준 기반 인터페이스를 이용하여 전체 통합(orchestration) 환경을 공개
통합 모니터링 (orchestration monitoring)
그림 3에서 확인할 수 있는 것처럼, BPEL을 기반으로 한 표준 기반 통합 솔루션을 이용하면 이러한 문제를 쉽게 해결할 수 있습니다.
그림 3 웹 서비스 인터페이스를 이용한 Customer Details Management Module
이와 같은 시나리오에 BPEL을 도입함으로써 기대할 수 있는 이점이 다음과 같습니다:
BPEL은 느슨하게 커플링된(loosely coupled) 웹 서비스 통합을 지원합니다.
비즈니스 로직을 (심지어 병렬 플로우까지도!) 단순한 XML 태그를 이용해 표현할 수 있습니다.
간단한 assign (copy 룰),invoke 구문을 이용하여 서비스 간의 데이터 라우팅을 수행할 수 있습니다.
다른 통합 툴, 미들웨어 툴, 또는 웹 애플리케이션으로부터 Customer Details Management Module을 독립적인 웹 서비스 컴포넌트로 호출할 수 있습니다.
Oracle BPEL Process Manager 등의 제품이 제공하는 단순한 GUI를 통해 프로세스를 쉽게 관리할 수 있습니다.
대부분의 미들웨어 툴은 비즈니스 프로세스를 웹 서비스의 형태로 공개함으로써, BPEL을 이용한 통합을 한층 용이하게 하는 기능을 제공합니다. 더 나아가, 사용 중인 모든 미들웨어 서비스 인터페이스가 공통 메시지 포맷을 사용하도록 설정하는 것도 가능합니다.
이제, Oracle BPEL Process Manager를 이용하여 SAP 시스템과 Siebel 시스템의 고객 데이터를 동기화하는 방법에 대해 알아보기로 합시다.
Customer Details Management Module의 구현
BPEL은 SAP 시스템과 Siebel 시스템 간의 고객 데이터 동기화 프로세스를 자동화하는 과정에서 매우 중요한 역할을 담당합니다. BPEL 프로세스를 구현하기 위한 작업 단계가 아래와 같습니다:
TIBCO, webMethods 프로세스를 웹 서비스로 공개합니다.
BPEL 프로세스를 이용하여 웹 서비스를 통합(orchestrate)합니다.
BPEL 프로세스에 예외 관리(exception management) 기능을 추가합니다.
Oracle BPEL Process Manager, 애플리케이션 어댑터, EAI 툴 간의 커뮤니케이션 보안 환경을 구현합니다.
로깅, 통보 프로세스를 중앙집중화 합니다.
1 단계: TIBCO, webMethods 프로세스를 웹 서비스로 공개. 고객 정보는 정규 포맷(canonical format)으로 표시되며, 포맷 내에는 SAP과 Siebel이 사용하는 필드가 모두 포함되어 있습니다. TIBCO와 webMethods는 이 포맷을 각각 Siebel, SAP 고객 레코드 포맷으로 변환하여 사용합니다.
BusinessWorks 프로세스를 웹 서비스로 공개하기 위한 방법이 아래와 같습니다:
BusinessWorks 프로세스가 제공하는 기능을 분석하고, 해당 기능이 통합 시나리오 내에서 독립적인 컴포넌트로써 구현될 수 있는지 확인합니다.
프로세스 입력 및 출력을 정의합니다.
input과 output이 복잡한 경우, W3C XML 스키마(XSD)를 이용하여 정의합니다. XSD를 이용하여 커스텀 폴트 스키마(custom fault schema)를 정의할 수도 있습니다.
WSDL 팔레트를 이용하여 WSDL을 생성하고input과 output 메시지 포맷을 정의합니다 (이때 필요한 경우, 메시지 포맷을 사전정의된 XSD와 연결합니다). 기존 WSDL을 임포트(import)할 수도 있습니다.
HTTP Connection 리소스를 설정합니다.
SOAP Event Source 를 첫 번째 액티비티로 사용하고, 비즈니스 로직, SOAP Send Reply 등의 순으로 프로세스를 서비스 형태로 공개합니다.
발생 가능한 예외(exception)을 처리하고 SOAP Send Fault를 이용하여 서비스 클라이언트에 예외를 전달합니다.
10. 머신 네임이 mymachine이고, HTTP Connection 리소스를 위해 8000번 포트를 사용하며, 프로세스 네임이 SOAPService인 경우, 다음 URL을 통해 서비스에 접근할 수 있습니다. http://mymachine:8000/SOAPService.
Event Source 액티비티의 WSDL 탭에서 서비스의 WSDL을 가져옵니다.
webMethods에서 사용하는 방법이 아래와 같습니다:
webMethods Flow Service가 통합 시나리오에서 독립적인 컴포넌트로써 구현될 수 있는지 확인합니다.
해당 웹 서비스를 별도의 인증 과정 없이 webMethods 외부에서 호출하고자 하는 경우 Permissions 탭의 "Execute ACL to Anonymous"를 체크합니다.
WSDL 다큐먼트를 생성하는 과정에서 프로토콜(SOAP-RPC/SOAP-MSG/HTTP-GET/HTTP-POST)과 전송 메커니즘(HTTP/HTTPS)을 정의합니다.
WSDL 다큐먼트의 타겟 네임스페이스(target namespace)를 정의합니다.
webMethods Integration Server가 실행되는 호스트명 또는 IP 주소를 Host 필드에 입력합니다.
현재 Integration Server에 연결할 때 사용하는 포트 넘버를 Port 필드에 입력합니다.
WSDL 다큐먼트를 로컬 파일 시스템에 저장합니다. 생성된 WSDL 다큐먼트에서 서비스 엔드포인트(service endpoint)를 확인할 수 있습니다.
참고: webMethods Integration Server는 특정 에러 상황이 발생한 경우 사전 정의된 SOAP 폴트(fault)를 전송합니다. 커스텀 SOAP 폴트를 전송하고자 하는 경우에는 커스텀 SOAP 프로세서를 이용해야 합니다. 또 서비스를 다큐먼트/리터럴(document/literal) 웹 서비스로 공개하고자 하는 경우에는 래퍼 서비스(wrapper service) 또는 커스텀 SOAP 프로세서를 사용해야 합니다.
이제, 아래와 같은 3 개의 TIBCO 웹 서비스가 존재한다고 가정해 봅시다 (TIBCO BusinessWorks 프로세스와 TIBCO Adapter for Siebel을 사용하여 구현).
Siebel Add
Siebel Update
Siebel Query
마찬가지로, 아래와 같은 webMethods 웹 서비스가 존재합니다 (webMethods Integration Server와 webMethods SAP R/3 Adapter를 이용하여 구현).
SAP Add
SAP Update
솔루션 아키텍처는 아래와 같이 요약할 수 있습니다:
그림 4 솔루션 아키텍처
위 그림에서 확인할 수 있는 것처럼, BPEL 프로세스는 EAI 툴을 이용한 프론트 오피스 콜 센터와 백엔드 SAP 및 Siebel CRM 애플리케이션 간의 커뮤니케이션을 중개하는 역할을 담당합니다.
미들웨어 프로세스를 웹 서비스로 공개하기 위한 몇 가지 베스트 프랙티스가 아래와 같습니다:
가능한 한 WS-I 표준을 준수합니다.
서비스를 리터럴 인코딩(literal encoding)을 사용한 “document” 스타일로 공개합니다. 이것이 불가능한 경우에는, 리터럴 인코딩을 이용한 “rpc” 스타일로 공개합니다. 두 가지 스타일 모두 WS-I 표준에 의해 권장되고 있지만, document 스타일이 좀 더 사용하기 쉬운 것이 사실입니다 (특히 BPEL assign 액티비티에 대한 copy 룰을 생성하는 경우에 특히 그러합니다). rpc 스타일의 경우 모든 스키마 엘리먼트가 별도의 메시지 파트로 구성되는 반면, document 스타일에서는 전체 메시지가 하나로 전달됩니다. 따라서 전체 스키마를 하나의 copy 룰을 사용하여 복사할 수 있기 때문에, 개발 작업이 단순화되고 최종 WSDL 다큐먼트의 스타일과 인코딩을 검증하기 쉽다는 장점이 있습니다.
SOAP 인코딩의 사용을 피합니다. WSDL의 SOAP Action 속성은 빈 문자열(empty string)으로 구성됩니다.
미들웨어가 웹 서비스의 인터페이스 기술을 위해 WSDL 1.1을 사용하고 있는지 확인합니다.
SOAP의 HTTP 바인딩을 사용합니다.
스키마 기술에 사용되는 모든 XSD가 W3C가 제안한 XML Schema Specification을 준수하는지 확인합니다. 예를 들어, 글로벌 엘리먼트 선언에 다른 글로벌 엘리먼트에 대한 참조가 포함되어서는 안됩니다 (다시 말해, ref 속성 대신 type 속성이 사용되어야 합니다).
2 단계: 웹 서비스의 통합(orchestration). H미들웨어 프로세스를 웹 서비스로 공개했다면, 다음은 Oracle BPEL Process Manager의 강력한 GUI 기반 BPEL 인터페이스를 이용하여 서비스들을 통합할 차례입니다.
앞부분에서 Customer Details Management Module이 SAP 시스템 및 Siebel 시스템의 고객 데이터를 동기화하는 역할을 담당한다고 설명한 바 있습니다. 이 프로세스를 BPEL Designer의 비주얼 인터페이스를 이용하여 생성한 결과가 아래 그림과 같습니다.
그림 5 Oracle BPEL Process Manager를 이용한 Customer Details Management Module의 통합
프로세스 플로우는 아래와 같이 요약될 수 있습니다:
receive 액티비티가 customer detail 정보를 접수합니다 (enterprise schema).
Detail 정보가 assign, invoke (Siebel Query 서비스) 액티비티를 통해 Siebel에 전달됩니다.
pick 액티비티에서 Siebel Query의 결과를 통해 고객이 신규 고객인지 기존 고객인지를 확인합니다.
신규 고객인 경우 병렬 플로우가 호출되고, flow 액티비티가 Siebel와 SAP에 고객 정보를 동시에 추가합니다. 또는 기존 고객인 경우, 양쪽 애플리케이션에 고객 정보를 업데이트하기 위한 병렬 플로우가 호출됩니다.
고객 정보가 SAP에 존재하지 않는 경우, Siebel Query 를 통해 필요한 필드를 가져옵니다. 업데이트가 필요한 SAP 필드는 일련의 assign copy 룰을 통해 SAP Update로 전달됩니다.
reply 액티비티를 통해 Customer Update/Addition의 최종 결과가 반환됩니다.
그림에서 확인할 수 있는 것처럼, 양측의 비즈니스 프로세스에는 Siebel 및 SAP 데이터의 추가와 업데이트를 위한 웹 서비스가 각각 구현됩니다. 1 단계에서 설계되는 이 웹 서비스들은 내부적으로EAI 프로세스들을 호출합니다.
이 BPEL 프로세스는 고객 관에 관련한 비즈니스 요구사항을 해결하고 있지만, 여전히 예외 사항을 처리하고 있지 못하다는 문제가 있습니다. 예를 들어, 특정 고객의 레코드가 Siebel에서는 성공적으로 추가되었지만 SAP에서 실패한 경우에는 어떻게 해야 할까요? 이러한 문제를 해결하기 위해서는 비즈니스 프로세스에 예외 관리(exception management)가 구현되어야 합니다.
3 단계: 예외 관리(Exception Management) 기능의 추가. 예외 관리 기능을 구현함으로써 BPEL 프로세스 또는 웹 서비스 외부에서 반환되는 에러 메시지 및 기타 예외 사항을 처리하고 비즈니스 에러 또는 런타임 에러 발생시 대응되는 에러 메시지를 생성할 수 있습니다.
아래 표는 고객 관리 BPEL 프로세스를 보다 안정적으로 구현하기 위한 예외 상황을 요약하고 있습니다.
No.
Case
해결 방안
1
Siebel Query 실패
프로세스 종료; 재시도
2
Siebel Add 실패; SAP Add 성공
SAP 레코드의 삭제를 통한 보정; 재시도
3
Siebel Add 성공; SAP Add 실패
정상 플로우; 재시도
4
Siebel Add 실패; SAP Add 실패
정상 플로우; 재시도
5
Siebel Update 성공; SAP Update 실패
정상 플로우; 재시도
6
Siebel Update 실패; SAP Update 성공
SAP 레코드 롤백을 통한 보정; 재시도
7
Siebel Update 실패; SAP Update 실패
정상 플로우; 재시도
1, 2, 6 번을 제외한 나머지 케이스는 별도의 예외 처리를 필요로 하지 않음을 확인할 수 있습니다.
Exception을 캐치하고 적절한 대응 조치를 취하기 위해서는 웹 서비스의 상태를 추적하는 것이 중요합니다. 케이스 1, 2, 6이 어떻게 처리되는지 논의 하기 전에, 특정 웹 서비스의 상태를 어떻게 추적할 수 있는지 설명해 보기로 하겠습니다.
BPEL 프로세스에는 아래와 같은 reply 스키마 속성이 포함됩니다:
Siebel_Add_Status
Siebel_Update_Status
SAP_Add_Status
SAP_Update_Status
위의 4가지 속성은 Failed , Success 또는 NA 의 값을 가지며, BPEL 프로세스에 의해 임의의 시점에 설정될 수 있습니다. Failed 상태로 설정하려는 경우, 프로세스는 타겟 웹 서비스에서 발생되는 SOAP 폴트(fault)를 캐치합니다 (이때 각각의 invoke 액티비티에 대해 catch handler가 사용됩니다). Customer Details Management Module을 호출하는 클라이언트는 에러가 발생한 경우 고객 상세정보를 재전송할 수 있습니다.
이제 각 케이스 별로 예외가 어떻게 관리되는지 살펴보기로 합시다:
Case 1 Siebel 쿼리가 실패한 경우, 프로세스를 종료하고 클라이언트 호출 과정을 재시도합니다.
Case 2 고객 상세정보의 INSERT 작업이 Siebel에서는 실패하고 SAP에서는 성공한 경우 (두 가지 작업은 병렬적으로 실행됩니다), 데이터 일관성이 훼손될 수 있습니다. 또, 같은 작업을 재시도하는 경우 아래와 같은 문제가 발생할 수 있습니다:
BPEL 프로세스를 호출하여 Siebel에 고객 상세정보를 INSERT하려 시도하는 과정에서, SAP에 중복된 정보가 입력될 수 있습니다.
해당 고객의 정보를 업데이트하는 BPEL 프로세스를 호출하려 시도하는 경우, Siebel에서의 업데이트가 (해당 레코드가 존재하지 않기 때문에) 실패하게 됩니다.
위의 상황을 처리하려면, 같은 작업이 재시도되기 전에 다른 webMethods 웹 서비스와 BPEL compensation handler 및 scope를 사용하여 SAP 고객 레코드를 먼저 삭제해야 합니다.
scope와 compensate 액티비티는 가장 핵심적인 BPEL 개발 툴의 하나입니다. 스코프(scope)는 다른 액티비티에 대한 container 겸 context로써 활용됩니다. 스코프 액티비티(scope activity)는 프로그래밍 언어의 {} 블록에 대응됩니다. 스코프는 BPEL 플로우를 기능적으로 유사한 구조로 그룹화하고, 에러, 이벤트, 보정(compensation) 및 데이터 변수, correlation set 등을 위한 핸들러(handler)를 제공합니다.
Oracle BPEL Process Manager는 보정 처리를 위해 두 가지 컨스트럭트를 제공합니다:
Compensation handler—롤백 작업을 위한 비즈니스 로직을 처리합니다. 프로세스 및 스코프 별로 핸들러를 정의할 수 있습니다.
Compensate activity—이 액티비티는 성공적으로 완료된 inner scope 액티비티를 통해 compensation handler를 호출합니다. 그리고 이 액티비티는 fault handler 또는 다른 compensation handler 내부에서만 호출이 가능합니다.
Exception은 catch handler를 통해 스코프 레벨에서 캐치됩니다. 그런 다음, catch handler는 compensate activity를 이용하여 inner scope를 위한 compensation handler를 호출합니다. 이 compensation handler는 롤백에 필요한 작업을 수행하게 됩니다.
다시 예제로 돌아가, BPEL 프로세스가 내부(inner), 외부(outer)의 두 가지 스코프를 갖는다고 가정해 봅시다. SAP Add 및 Siebel Add 서비스의 호출은 outer scope를 통해 수행되며, SAP Add 서비스 만이 inner scope를 통해 수행됩니다. compensation handler는 inner scope와 연계가 가능하며, SAP Delete 서비스를 위한 액티비티를 호출합니다.
BusinessWorks 웹 서비스가 전송한 SiebelAddfault 를 캐치하기 위해 catch block을 outer scope와 연계할 수 있습니다. SiebelAddfault가 발생할 때마다, compensate activity는 inner scope에 대한 보정작업을 수행하고 SAP 고객 레코드를 삭제합니다. 이때 inner scope의 모든 액티비티가 성공적인 경우에만 보정 작업이 성공적으로 완료될 수 있음을 참고하시기 바랍니다.
scope와 compensation handler를 수정한 BPEL 프로세스가 그림 6과 같습니다.
그림 6 SAP 고객 레코드 삭제를 위한 compensation logic
Case 6 Siebel 업데이트가 실패하고 SAP 업데이트만 성공한 경우에도 트랜잭션은 실패합니다. 이로 인해 데이터 일관성에 문제가 발생할 수 있습니다. 따라서, SAP에서 발생한 트랜잭션을 롤백 하기 위한 compensation logic이 필요합니다. Compensation handler는 SAP Update 서비스와 연계되어 SAP Rollback 서비스를 호출합니다. BPEL 프로세스의 수정 작업은 위에서 설명한 가이드라인을 준수하는 형태로 수행됩니다.
compensate activity를 명시적으로 호출할 수 있는 기능은 BPEL 에러 핸들링 프레임워크의 핵심으로 활용됩니다. 고전적인 EAI 보정 메커니즘과 달리, BPEL은 표준화된 롤백 방법론을 제공하고 있습니다.
TIBCO 및 webMethods 서비스의 통합을 위한 BPEL 프로세스를 생성했다면, 이제 BPEL 어댑터와 EAI 툴 간의 커뮤니케이션을 보다 효과적으로 수행할 수 있는 방법을 알아보기로 합시다.
4 단계: 비즈니스 커뮤니케이션의 보안. 보안은 아웃바운드(TIBCO, webMethods 서비스 호출의 보안)와 인바운드(BPEL 프로세스의 보안)의 두 레벨로 나누어 구현됩니다.
아웃바운드 보안 (Outbound Security) 먼저 TIBCO 및 webMethods 서비스에 대한 불법적인 액세스를 차단하기 위한 보안 대책이 필요합니다. Oracle BPEL Process Manager는 외부 서비스 호출 시 HTTP basic authentication 또는 WS-Security authentication을 지원합니다. 본 문서의 예제에서는 HTTP 인증을 사용하여 TIBCO 및 webMethods 서비스 및 BPEL 프로세스로부터의 호출 메커니즘의 보안을 구현하는 방법을 설명합니다.
TIBCO BusinessWorks와 webMethods Integration Server에 구현된 웹 서비스는 기본적으로 HTTP basic authentication을 지원합니다. TIBCO 웹 서비스를 설계하는 과정에서 SOAP event source activity의 Transport Details 탭에서 Use Basic Authentication 체크박스를 체크해야 합니다. TIBCO Administrator를 이용하여 웹 서비스를 구축하는 과정에서 사용자/역할 별로 서비스 액세스 레벨을 설정할 수 있습니다. 또 webMethods Developer를 이용하여 웹 서비스를 설정하는 과정에서 각각의 operation 별로 ACL(Access Control List)을 작성할 수 있습니다.
TIBCO, webMethods 서비스를 구축하는 과정에서 basic authentication을 사용하였다면, 서비스에 대한 호출이 수행될 때마다 인증정보가 BPEL 프로세스에 전달되어야 합니다. 두 개의 Partner Link 속성(httpUsername과 httpPassword)을 이용하면 이 작업을 쉽게 수행할 수 있습니다. 이 속성의 값은 아래와 같이 정적으로 설정될 수 있습니다.
또, WS-Security를 이용하여 TIBCO, webMethods 서비스의 보안을 구현하는 것도 가능합니다. 이때 BPEL 프로세스는 WS-Security authentication header를 웹 서비스로 전달합니다. 이때 서비스가 지원하는 WS-Security 헤더를 WSDL 다큐먼트에 정의해 두어야 합니다. message body 데이터 엘리먼트와 마찬가지로, 이 헤더 필드는 BPEL 프로세스에 의해 변수로 활용됩니다. WS-Security 인증에 대한 자세한 정보는 OTN에서 HotelShopFlow 샘플 코드를 다운로드하셔서 확인하실 수 있습니다.
인바운드 보안 (Inbound Security) HTTP 인증을 이용하면 BPEL 프로세스가 불법적인 사용자에 의해 차단되는 것을 방지할 수 있습니다. 또 각 BPEL 프로세스 별로 다른 인증 정보를 설정하는 것이 가능합니다.
이 기능을 사용하려면, 애플리케이션 서버 레벨에서 HTTP basic authentication을 활성화해야 합니다. 그런 다음 인증 정보는 BPEL 프로세스에 의해 호출되고 Partner Link 속을 통해 TIBCO, webMethods 웹 서비스로 전달됩니다.
5 단계: 중앙집중적 로깅 및 에러 핸들링. 비즈니스 프로세스의 보안과 안정성을 확보하는 것만큼이나, 중앙집중적인 로깅, 통보 기능을 구현하는 것 또한 중요합니다. 중앙집중적인 로깅, 에러 핸들링 프레임워크를 구현함으로써 애플리케이션의 안정성을 한층 더 강화하고, 재활용성을 증가시키고, 개발 비용을 절감할 수 있습니다. BPEL 프로세스의 웹 서비스 또는 미들웨어를 이용하여 이러한 프레임워크를 구축하는 것이 가능합니다. Oracle BPEL Process Manager의 파일 어댑터를 이용하여 서비스에 로깅 기능을 추가하고 에러 발생시 이메일 통보 기능을 구현할 수 있습니다.
프레임워크에 사용하게 될 샘플 스키마가 아래와 같습니다:
스키마 엘리먼트
설명
ROLE
ERROR, DEBUG, WARNING, INFO 등
CODE
에러 코드
DESCRIPTION
에러 설명
SOURCE
에러 소스
EMAIL
통보를 전달할 이메일 ID
이 BPEL 프로세스는 비동기식 단방향 웹 서비스로서 공개되므로, 서비스의 클라이언트에는 별도의 시간 지연이 수반되지 않습니다. 중앙집중적 로깅 및 통보를 위한 LogNotify 프로세스가 아래 그림과 같습니다.
그림 8 Oracle BPEL Process Manager를 이용한 로깅 및 에러 핸들링 프레임워크
그림 8에서 확인할 수 있는 것처럼, LogNotify 프로세스는 아래와 같은 작업을 수행합니다:
외부 프로세스로부터 전달되는 정보를 로그에 저장합니다
Log Service를 호출하여 데이터를 로그 파일에 저장합니다. 이 과정에서 Log Service는 파일 어댑터를 활용합니다.
로깅이 성공적인 경우 프로세스가 완료됩니다. 또 ROLE 필드에ERROR가 포함된 경우, 서비스는 이메일을 통해 담당자에게 통보를 수행합니다. 이메일 정보는 수신된 메시지 원본으로부터 추출됩니다 (샘플 스키마를 참고하십시오.).
이메일 통보 작업이 실패한 경우, 에러가 로그 파일에 저장된 후 프로세스가 종료됩니다.
메인 BPEL 프로세스에 포함된 각각의 invoke 액티비티는 별도의 try-catch 블록을 갖습니다. 미들웨어 프로세스가 전송한 SOAP 폴트(애플리케이션에서 발생한 exception 포함)는 catch블록에 의해 처리되며, 중앙 로깅/에러 핸들링 프레임워크에 라우팅됩니다.
그림 9는 Siebel Add가 실패한 경우 LogNotify 프로세스가 호출되는 과정을 보여주고 있습니다.
결론
오늘날의 통합 시장은 강력한 EAI 제품으로 넘치고 있으며, 많은 통합 기능이 구현되어 제공되고 있습니다. BPEL은 기존 EAI 솔루션의 서비스 전환을 위한 독자적인 대안을 제공합니다. 기존 미들웨어 프로세스를 웹 서비스로 공개하고, 웹 서비스들을 Oracle BPEL Process Manager로 통합함으로써, 기업은 SOA를 위한 첫 걸음을 내디딜 수 있을 것입니다.
로젝트에서 성능을 향상시키기 위해 SQL 튜닝에 전념하는 사이트들이 많이 있을 것이다. SQL 튜닝을 통해 성능 향상을 기대할 수 있는 것은 사실이다. 예전에는 성능 저하가 발생하는 경우 SQL 튜닝 보다도 해당 시스템의 CPU, 디스크 등의 자원을 증설하는 부분에 초점을 맞추었다. 이와 같이 자원을 증설하는 것보다 SQL을 튜닝하여 성능을 최적화하고자 하는 것은 매우 고무적인 현상임에는 틀림 없다. 그 만큼 관리자들의 생각이 IT 선진화로 가는 것은 아닐까? 하지만, 아직도 SQL 튜닝의 성능을 배가시킬 수 있는 물리적 구성에는 많은 허점과 편견이 존재한다. 이번 호에는 SQL 튜닝의 효과를 배가 시킬 수 있는 그 물리적 구성에 대해 자세히 확인해 보자.
성능을 향상시키는 물리적 구성을 이해해라
물리적 구성이 최적화되어 있지 않은 상태에서 SQL 튜닝으로 10배의 성능이 향상된다고 가정하자. 이런 경우 물리적 구성을 최적화한 후 SQL을 튜닝한다면 15배 이상의 성능 향상을 기대할 수 있을 것이다. 반드시 15배의 성능 향상은 아니지만 물리적 구성의 최적화 만으로도 우리는 성능 향상을 기대할 수 있게 된다. 필자가 어느 사이트를 지원했을 때의 일이다. 해당 사이트에서는 SQL 튜닝보다는 물리적 구성의 최적화에 초점을 두었었다. 디스크 I/O 분산과 파티션 테이블만을 이용하여 SQL 튜닝을 수행하지 않고 4배의 성능 향상을 확인했었다. 이 얼마나 놀라운 사실인가? 여기에 SQL 튜닝까지 수행한다면 10배의 성능이 향상될 SQL의 성능은 그 이상의 성능 향상을 기대할 수 있을 것이다. 이는 절대 놀라운 사실이 아니다. 이와 같은 이유에서라도 우리는 SQL 튜닝과 물리적 구성의 최적화를 병행해야만 할 것이다. 이제는 물리적 구성의 최적화를 간과해서는 안될 것이다. 한번 구성된 후에는 변경되기 힘든 것이 물리적 구성이다. SQL은 하나하나 최적화를 수행하여 적용하면 될 것이다. 하지만 물리적 구성은 한번 구성된 후 변경하기 위해서는 많은 어려움을 경험해야 할 것이다. 이와 같은 물리적 구성을 이제는 소홀히 여기지 말고 프로젝트 초기부터 성능과 연관 지어 수많은 고려를 해야 할 것이다. 성능을 고려할 경우에도 최적의 물리적 구성에 대한 정답은 없다. 하지만, 성능을 고려하여 물리적 구성에 대해 많은 고민을 한다면 우리는 성능을 보장할 수 있는 최적의 물리적 구성을 구현할 수 있을 것이다. 결국, 항상 생각하고 고민하는 습관이야 말로 해당 시스템을 최적의 시스템으로 구현할 수 있는 최선의 방법인 셈이다. 물리적 구성의 최적화는 여러 가지 요소에 의해 구성될 것이다. 그렇다면 어떠한 물리적 구성에 의해 성능은 향상되거나 저하될 수 있는 것일까? 아래와 같은 물리적 구성에 의해 우리는 성능 향상을 기대할 수 있을 것이다.
·데이터 저장 아키텍쳐 - 클러스터 팩터(CLUSTER FACTOR) 아키텍쳐 ·테이블 아키텍쳐 - 파티션 테이블, IOT 테이블 ·인덱스 아키텍쳐 - 결합 인덱스, 단일 컬럼 인덱스 ·엑세스 아키텍쳐 - 병렬 프로세싱(PARALLEL PROCESSING) 아키텍쳐
위와 같은 물리적 구성 요소를 통해 우리는 성능을 향상시킬 수 있을 것이다. 새로운 시스템을 구축할 경우 위의 항목들을 항상 고려해야만 할까? 위의 항목들은 시스템이 서비스를 개시한 후에는 적용하기 힘들다. 그 이유는 물리적인 구성 요소이기 때문이다. 이제부터 각각의 항목에 대해 프로젝트 중에 어떻게 적용해야 그 성능을 최적화할 수 있는지 확인해 보자.
데이터 저장 아키텍쳐를 고려하자
여기서 언급하는 데이터 저장 아키텍쳐는 클러스터 팩터를 의미한다. 그렇다면 클러스터 팩터는 무엇을 의미하는가? 클러스터 팩터를 이해하기 위해서는 테이블에서 원하는 데이터를 액세스하는 유형과 저장되는 데이터에 대한 분석이 필요하다. 예를 들어 보자. 어느 카드사에 거래내역 테이블이 존재한다고 가정하자. 해당 카드사의 카드에 대한 거래가 발생하면 해당 테이블에 거래내역 데이터가 저장된다고 가정하자. 그렇다면 해당 테이블에는 어떻게 데이터가 저장되겠는가? 삭제되는 데이터가 없다면 테이블의 데이터는 INSERT되는 순서대로 데이터가 저장될 것이다. 그렇다면 거래일자에 의해 데이터가 발생하고 저장되므로 해당 테이블에는 거래일자 순으로 데이터가 저장될 것이다. 이는 무엇을 의미하게 되는가? 거래내역 테이블의 데이터를 저장하는 블록을 확인해보면 하나의 블록에는 동일한 거래일자가 저장된다. 데이터를 저장하는 하나의 블록을 확인해 보면 해당 블록에 거래일자 기준으로 2008년 4월 30일인 데이터가 저장되어 있다면 해당 블록에는 거의 대부분의 데이터가 2008년 4월 30일 데이터가 저장되어 있을 것이다. 물론 해당 블록이 2008년 4월 30일 데이터를 저장하는 처음 블록이라면 2008년 4월 29일 데이터가 같이 저장되어 있을 수도 있다. 여기서 중요한 것은 각각의 블록들은 대부분 동일한 거래일자 값을 가지는 데이터를 저장한다는 것이다. 이는 무엇을 의미하는가? 하나의 블록에는 10건의 데이터가 저장된다고 가정하자. 그리고 하루 데이터는 1000건의 데이터가 발생한다고 가정하자. 그렇다면 해당 1000건의 데이터는 몇 개의 블록에 저장되어 있겠는가? 1000건의 데이터는 100개의 블록에 10건씩 저장될 것이다. 이와 같기 때문에 해당 일자의 데이터를 모두 조회한다면 우리는 100개의 블록만 액세스하여 모든 데이터를 추출할 수 있게 된다. 그렇다면 우리는 불필요하게 액세스한 블록은 존재하지 않게 되며 또한 하나의 블록에서 대부분의 데이터를 결과로 추출하게 되므로 매우 효율적이라고 할 수 있을 것이다. 이와 같은 이유에서 거래내역 테이블은 거래일자 값에 의해 클러스터 팩터가 양호하다고 하게 된다. 결국 클러스터 팩터가 양호하다는 뜻은 각각의 블록은 클러스터 팩터가 양호한 컬럼의 값이 동일한 데이터로 저장되어 있어 우리가 액세스하고자 하는 데이터가 모여 있는 것을 의미하게 된다. 그렇다면 거래내역 테이블에서 거래일자 컬럼이 아닌 다른 컬럼에 대해 확인해 보자. 카드 회사의 가장 기본이 되는 카드번호 컬럼은 어떻게 되는가? 거래내역 테이블은 저장되는 순서에 의해 데이터가 저장될 것이다. 그리고 거래내역 테이블에서 많은 경우에 카드번호 컬럼의 값으로 데이터를 조회하게 된다. 그렇다면 ‘111’번 카드번호에 대해 거래내역 데이터를 조회한다고 가정하자. 해당 카드번호에 의해 생성된 거래내역 데이터는 100건이라고 가정하자. 그렇다면 해당 데이터를 액세스하기 위해 얼마나 많은 블록을 액세스해야 할 것인가? 거래일자 컬럼의 경우에는 각각의 블록에 동일한 거래일자 컬럼의 값을 가지는 데이터가 저장될 확률이 매우 높았다. 그 이유는 거래일자 값에 의해 순차적으로 데이터가 저장되기 때문이다. 그렇다면 카드번호 컬럼은 어떠한가? 해당 고객이 하루에 2번씩 사용하여 100번을 사용했다 하여도 각 데이터는 동일한 블록에 저장될 확률은 매우 낮게 된다. 이는 카드를 2번 연속해서 사용했다고 동일 블록에 저장되기 힘들 것이다. 그 이유는 전국에서 많은 사람들이 동시에 카드를 이용하게 되며 그렇기 때문에 해당 데이터들은 카드번호 값이 동일한 데이터들이 동일한 블록에 저장되기 매우 힘들게 된다. 이와 같은 상황에서 해당 카드번호 컬럼에 대해 조회를 수행해야 한다면 테이블에서 거의 100개의 블록을 액세스하게 된다. 결국 각 블록에 결과로 추출하고자 하는 데이터는 한건 씩 저장되어 있기 때문에 거래내역 테이블에 대해 카드번호 컬럼에 대해서는 클러스터 팩터가 불량하다고 이야기 하게 된다. 우리가 조회하는 데이터의 클러스터 팩터가 매우 양호하다면 각각의 블록에는 해당 컬럼의 값이 동일한 데이터들이 저장되므로 적은 블록을 액세스할 수 있게 되어 성능은 향상될 것이다. 우리가 조회하는 데이터의 클러스터 팩터가 불량하다면 각각의 블록에는 해당 컬럼의 값이 동일한 데이터들이 함께 저장되지 않게 되므로 많은 블록을 액세스해야 한다. 따라서 디스크 I/O의 증가로 성능은 저하될 것이다. 결국, 우리가 추출하고자 하는 데이터의 클러스터 팩터는 성능에 있어 매우 중요한 역할을 수행하게 된다.
클러스터 팩터의 정의를 이해하자
앞서 클러스터 팩터에 대한 예제를 통해 개념을 확인해 보았다. 클러스터 팩터는 우리가 추출하고자 하는 데이터가 얼마나 동일한 블록에 저장되어 있는가를 의미하게 된다. 그렇다면 클러스터 팩터는 어떤 기준으로 구분되는가? 아래 그림을 확인해 보자
클러스터 팩터 값은 위와 같이 정의할 수 있을 것이다. 인덱스를 통해 추출된 데이터가 100건이라고 가정하자. 인덱스를 액세스한 후에는 테이블을 액세스하게 되는 것은 당연한 사실일 것이다. 이 경우 인덱스에서 추출된 데이터는 100건의 데이터인데 테이블을 액세스하는 블록의 개수가 100이라면 위의 공식에 대입해보면 1이라는 값이 추출된다. 이와 같다면 우리가 원하는 데이터는 각 블록에 1건의 데이터만이 존재한다는 의미가 된다. 그러므로 해당 액세스는 클러스터 팩터가 불량하게 된다. 이와 같다면 우리도 모르게 성능 저하가 발생할 수 있게 된다. 반대로 인덱스에서 100건의 데이터가 추출되었지만 테이블 블록은 2개만 액세스했다면 위의 공식에 적용하면 값은 100/2이므로 50의 값이 추출되어 양호한 클러스터 팩터가 될 것이다. 클러스터 팩터가 양호하면 액세스하는 블록의 개수는 감소하게 되므로 자연스럽게 성능은 향상 될 것이다. 위의 클러스터 팩터 값의 정의에서 우리는 무엇을 이해해야 하는 것일까? 공식을 외운다고 우리가 클러스터 팩터에 대해 모든 것을 해결할 수 있는 것은 아니다. 우리에게 지금 필요한 것은 우리가 엑세스하는 데이터에 대해 클러스터 팩터를 최적화한다면 성능을 향상시킬 수 있다는 것이다. 이제부터 클러스터 팩터의 속성을 파악하고 우리가 엑세스하고자 하는 데이터에 대해 클러스터 팩터를 최적화하는 방법을 확인해 보자.
클러스터 팩터의 속성을 파악해라
클러스터 팩터에는 우리가 아직까지 언급하지 않은 하나의 속성이 존재한다. 그렇다면 클러스터 팩터의 속성은 무엇인가? 하나의 테이블에서는 하나의 컬럼에 의해서는 클러스터 팩터를 최적화할 수 있다는 것이다. 이는 우리에게 클러스터 팩터를 최적화하는 방법에 많은 고려 사항과 제한 사항을 발생시키게 된다. 그렇다면 정말로 하나의 테이블은 하나의 컬럼으로만 클러스터 팩터를 양호하게 할 수 있는 것인가? 앞서 언급한 거래내역 테이블을 다시 한번 확인해 보자. 거래내역 테이블은 거래일자 순으로 데이터가 저장되기 때문에 각각의 블록은 동일한 거래일자 데이터가 저장될 것이다. 그렇기 때문에 이 상태 그대로라면 해당 테이블은 거래일자 컬럼에 의해 클러스터 팩터가 최적화된다. 거래내역 테이블은 거래일자 컬럼의 값으로도 조회를 하지만 카드번호 컬럼의 값으로 많은 조회가 발생한다고 가정하자. 그렇다면 거래일자로 조회하는 액세스는 클러스터 팩터가 양호하기 때문에 자동으로 성능이 향상될 수 있지만 카드번호 컬럼으로 조회하는 액세스는 클러스터 팩터가 양호하지 않기 때문에 해당 액세스에 대해서는 성능이 저하될 것이다. 이와 같은 경우 우리는 카드번호 컬럼으로 클러스터 팩터 최적화를 수행해야 할 것이다. 거래내역 테이블에 대해 카드번호 컬럼으로 클러스터 최적화를 수행한다면 해당 거래내역 테이블에는 어떤 현상이 발생하게 되는가? 카드번호 컬럼으로 클러스터 팩터를 최적화하므로 거래내역 테이블은 각각의 블록에 카드번호 컬럼의 값이 동일한 데이터들이 저장될 것이다. 이와 같이 데이터가 저장되어야만 우리는 거래내역 테이블이 카드번호 컬럼에 의해 클러스터 팩터가 양호하다고 이야기할 수 있을 것이다. 이처럼 구성하는 방법을 클러스터 팩터 최적화라고 한다. 카드번호 컬럼으로 클러스터 팩터 최적화를 수행하면 어떤 현상이 발생하게 되는가?
·카드번호 컬럼 - 각각의 블록에 동일한 카드번호 컬럼의 값이 저장 ·거래일자 컬럼 - 각각의 블록에 서로 다른 거래일자 컬럼의 값이 저장
위와 같은 현상이 발생하게 된다. 이 뜻은 거래일자 컬럼의 값에 대해서 기존에는 클러스터 팩터의 값이 양호했지만 카드번호 컬럼으로 클러스터 팩터 값을 최적화한다면 더 이상 거래일자 컬럼의 값으로는 클러스터 팩터가 최적화되지 않는다는 의미가 된다. \2008년 4월 30일 사용한 거래내역 데이터를 확인해 보자. 2008년 4월 30일에 사용한 거래내역 데이터는 연속된 블록에 저장될 것이다. 따라서, 해당 블록들을 확인해 본다면 동일한 2008년 4월 30일 데이터들이 저장될 것이다. 이러한 이유에서 거래일자 컬럼에 의해 클러스터 팩터가 최적화되었었다. 하지만 해당 데이터의 카드번호 값은 어떠한가? 하루에 동일한 카드가 몇 번이나 사용되겠는가? 업무적으로 차이가 발생할 수 있지만 하나의 카드가 동일한 일자에 수 십번 아니 수 백번 사용되지는 않을 것이다. 그렇다는 이야기는 무엇인가? 각각의 블록에 동일한 카드번호 컬럼의 값을 가지는 데이터를 저장하는 순간 각각의 블록에는 동일한 거래일자 값의 데이터는 블록에 저장되지 못한다는 것이다. 그러므로 카드번호 컬럼으로 클러스터 팩터를 최적화한다면 그 동안 클러스터 팩터가 양호했던 거래일자 컬럼의 클러스터 팩터는 불량해 진다. 결국 하나의 컬럼으로 클러스터 팩터를 최적화 한다면 다른 컬럼들은 일반적으로 클러스터 팩터가 불량하게 된다. 이는 무엇을 의미하는 것일까? 카드번호 컬럼으로 클러스터 팩터를 최적화한다면 카드번호 컬럼의 값으로 조회하는 액세스의 성능을 최적화할 수 있지만 그에 반해 거래일자 컬럼으로 데이터를 액세스하는 경우에는 클러스터 팩터가 불량해 지므로 성능은 저하된다. 이처럼 클러스터 팩터의 최적화에는 장점과 단점이 존재하게 된다. 어떤 컬럼으로 클러스터 팩터를 최적화한다면 다른 컬럼들의 클러스터 팩터는 불량해 지게 된다. 어떤 카드회사에서 필자가 실제로 거래내역 테이블에 대해 카드번호 컬럼으로 클러스터 팩터를 최적화해 보았었을 때의 일이다. 카드번호 컬럼으로 데이터를 액세스하는 어플리케이션은 전체적으로 성능이 안정화되었다. 하지만 거래일자 컬럼으로 매일 작업을 수행하는 어플리케이션은 기존 성능에 비해 10배 정도의 성능 저하가 발생했었다. 그래서 개발자로부터 연락이 왔으며 필자는 내일이 되면 거래일자 컬럼으로 클러스터 팩터가 최적화되니 원래의 성능을 보장할 수 있을 것이라고 언급했다. 다음 날이 되자 필자가 말한 것이 현실로 나타났다. 기존 거래일자 컬럼으로 데이터를 액세스하는 애플리케이션은 기존 성능을 보장 받게 되었다. 이는 무엇을 의미하는가? 테이블의 클러스터 팩터는 해당 테이블을 액세스하는 어플리케이션에 엄청난 영향을 미친다는 것이다. 이와 같이 성능에 있어 큰 영향을 미치는 클러스터 팩터를 더 이상 간과해서는 안될 것이다. 프로젝트 중에 중요 테이블에 대해 클러스터 팩터를 고려했는지 안 했는지는 해당 시스템의 전체 성능에 있어 매우 중요한 역할을 수행하게 된다. 아직도 많은 사람들은 클러스터 팩터에 대한 중요성을 인식하지 못하고 있는 것이 현실이다. 관리자부터 클러스터 팩터에 대한 중요성을 인식해야지만 많은 시스템에 필요한 클러스터 팩터를 최적화할 수 있을 것이다. 데이터베이스의 데이터가 대용량으로 변하면서 또한 많은 애플리케이션이 수행되는 시스템에서는 클러스터 팩터가 성능에 있어서는 매우 중요한 역할을 수행하게 된다. 이제는 더 이상 클러스터 팩터를 간과해서는 안될 것이다. 우리가 많이 액세스하는 컬럼으로 클러스터 팩터를 최적화하는 순간 우리는 최적의 성능을 기대할 수 있을 것이다. 클러스터 팩터를 최적화하는 방법에는 많은 방법이 존재한다. 테이블 재구성 방법부터 파티션 테이블을 이용하는 방법까지 여러 방법이 존재하며 이에 대한 방법은 다음 호에 자세히 언급하도록 하겠다. 우리가 생각하지 못한 클러스터 팩터에 대한 생각의 전환이야 말로 대용량 데이터베이스에 대해 성능을 최적화할 수 있는 핵심 요소이다.
수많은 프로젝트에서 프로그램을 개발하면서 해당 프로그램에 필요한 인덱스를 생성하고 인덱스를 이용하여 성능 향상을 계획하는 사이트를 많이 보아왔다. 하지만, 많은 사이트에서 인덱스의 잘못된 선정으로 성능 문제가 발생하고 이로 인해 많은 고통을 경험하는 것을 수없이 많이 보아 왔다. 도대체 인덱스에는 어떠한 비밀이 존재하기 때문에 우리는 SQL을 위해 인덱스를 생성하고 성능 저하를 경험해야 하는 것인가? 이는 우리가 인덱스에 대해 두 가지의 잘못된 사실을 진실로 간주하기 때문이다. 이제부터 인덱스의 잘못된 두 가지 사실에 대해 정확히 파헤쳐 보자.
인덱스는 무엇인가?
나를 알고 적을 안다면 100전 100승이라고 했던가? 따라서, 인덱스를 효과적으로 이용하기 위해서는 인덱스에 대한 정확한 이해가 필요할 것이다. 인덱스의 정확한 이해 없이 인덱스를 논한다는 것은 수박 겉핥기에 지나지 않을 것이다.
여기서는 인덱스의 물리적 구조를 이야기하고 싶지는 않다. 인덱스의 물리적 구조도 필요하겠지만 우리가 반드시 이해해야 할 것은 인덱스의 논리적 구조이다. 많은 개발자들과 이야기를 하다 보면 인덱스에 대해 많은 것을 알고 있다고 생각하지만 많은 사람들이 인덱스의 논리적 구조에 대해 정확히 이해하지 못하는 경우가 매우 많았다. 필자는 인덱스의 논리적 구조는 사전의 인덱스와 동일하다고 자주 이야기를 한다. 그럼 이제부터 우리가 잘 알고 있는 사전의 인덱스를 정확히 분석해 보자. 이것이 우리가 인덱스의 논리적 구조를 정확히 이해하는 가장 빠른 지름길이 될 것이다.
우리가 학창 시절부터 사용하던 사전을 생각해 보자. 사전의 옆에는 사전의 인덱스가 존재할 것이다. 여기서 각각의 영어 알파벳은 컬럼의 값이라고 생각하면 된다. 예를 들어, GIRL이라는 단어는 4개의 컬럼의 값이며 첫 번째 컬럼의 값은 ‘G’이며 두 번째 컬럼의 값은 ‘I’가 된다고 가정하자. 이와 같은 가정에서 인덱스의 논리적 구조를 확인해 보자.
첫 번째로 인덱스는 첫 번째 컬럼의 값으로 정렬되어 구성되는 특징에 대해 확인해 보자. 사전의 인덱스를 확인해 보면 첫 번째 알파벳이 ‘A’로 시작하는 단어부터 시작하여 알파벳 순서로 정렬되어 사전을 구성하게 된다. 인덱스도 이와 같이 인덱스를 구성하는 첫 번째 컬럼의 값으로 정렬되어 구성된다. 이와 같은 사실은 대부분의 개발자들이나 또는 관리자들이 알고 있는 사실이다.
두 번째로 인덱스의 첫 번째 컬럼의 값이 동일한 경우에는 인덱스의 두 번째 컬럼의 값으로 정렬되는 특징에 대해 확인해 보자. 인덱스를 구성하는 첫 번째 컬럼의 값이 동일한 경우에는 어떻게 인덱스가 구성되겠는가? 이 또한 사전의 인덱스를 생각해보면 바로 답을 유추할 수 있음에도 불구하고 많은 사람들이 정확히 모르고 있다는 것이 현실이다. 만약, 사전이 ‘A’로 시작하는 단어를 순서 없이 모아두고 ‘B’로 시작하는 단어를 어떠한 순서에 상관 없이 모아 둔다면 이와 같이 구성된 사전이 의미 있겠는가?
예를 들어, GIRL이란 단어를 찾는다면 ‘G’로 시작하는 단어를 모아둔 사전의 페이지를 모두 읽어봐야 할 것이다. 이처럼 단어의 첫 번째 알파벳으로만 사전의 인덱스를 구성한다면 동일한 알파벳으로 시작하는 단어를 모아두었다는 약간의 의미는 있겠지만 그렇게 큰 의미는 없을 것이다. 사전의 인덱스를 확인해 보면 ‘A’로 시작하는 단어는 어떤 순서로 사전에 저장되어 있는가? 동일한 알파벳으로 시작하는 단어는 단어를 구성하는 두 번째 알파벳으로 정렬되어 저장된다.
이와 같기 때문에 GIRL이라는 단어를 찾는다면 ‘G’로 시작하는 단어 중 두 번째 알파벳이 ‘I’인 단어를 바로 찾게 된다. 두 번째 알파벳이 동일한 단어에 대해서는 세 번째 알파벳으로 정렬되어 사전에 저장될 것이다. 사전의 단어들이 이와 저장되기 때문에 우리는 사전을 효과적으로 사용할 수 있을 것이다. 정렬된 구조로 저장되기 때문에 우리가 원하는 단어를 바로 찾아갈 수 있을 것이다.
인덱스의 논리적 구조에는 위와 같은 특징을 가진다. 인덱스의 첫 번째 컬럼으로 인덱스는 정렬되어 구성되며 인덱스를 구성하는 첫 번째 컬럼의 값이 동일한 경우에는 인덱스를 구성하는 두 번째 컬럼으로 정렬되어 구성된다는 사실은 매우 중요한 사실이다. 이를 이해하고 이제부터 우리가 잘못 알고 있는 인덱스의 비밀을 확인해 보자.
인덱스를 이용해야만 성능은 향상되는가
우리가 SQL을 작성하면서 성능을 보장하기 위해 가장 먼저 무엇을 고려하는가? 가장 먼저 고려하는 사항은 인덱스일 것이다. 많은 경우에 작성한 SQL에 대해 인덱스를 생성한다면 성능을 보장 받을 수 있다고 생각하게 된다. 과연, 인덱스만 생성한다면 해당 SQL의 성능을 보장할 수 있겠는가? 어떤 SQL은 인덱스 때문에 성능이 엄청 저하될 수 있는 것이 현실이다. 이러한 경우는 경험해본 사람이라면 쉽게 이해할 수 있을 것이다.
그렇다면 어떤 경우의 SQL에는 인덱스가 필요하고 어떤 경우의 SQL에는 인덱스가 필요하지 않은 것일까? 인덱스를 이용하여 성능을 최적화하기 위해서 어떤 컬럼으로 인덱스를 구성할 것인가에 대한 것보다도 해당 SQL이 인덱스를 이용해야 할지 아니면 해당 SQL이 인덱스를 이용하면 안 되는지에 대한 정확한 기준이 필요하다. SQL을 작성하는 사람들은 이러한 기준을 가지고 있는가? 아마도 많은 사람들이 이러한 기준을 가지고 있지 않을 것이다. 이러한 문제는 SQL을 작성하는 개발자들만의 문제가 아니다.
우리가 많이 사용하는 툴들은 해당 SQL의 실행 계획에서 인덱스를 이용하지 못하는 경우에 빨간색을 표시하게 된다. 이와 같은 현상이 마치 무조건 문제인 것처럼 보이게 만들어 무조건 인덱스를 생성하게 만드는 경우도 많다. 이제부터 우리는 어떤 SQL은 인덱스를 이용하고 어떤 SQL은 인덱스를 이용해서는 안 되는지에 대해 정확하게 구분해야 할 것이다.
첫 번째로 인덱스를 이용해서는 안 되는 SQL에 대해 확인해 보자. 어떤 SQL이 인덱스를 이용하면 안 되는지에 대해 언급하기 전에 하나의 예제를 확인해 보자. 어떤 사이트를 지원 했을 때의 일이다. 개발 담당자는 매일 저녁 9시부터 1시간 동안 야간 통계 작업을 수행한 후 SQL의 수행 결과를 확인하고 퇴근을 하는 경우를 보았다. 해당 담당자는 매일 저녁 이와 같은 작업을 1년 동안 수행하고 있었다.
해당 SQL을 확인한 결과 해당 SQL은 해당 테이블의 대부분의 데이터를 액세스하여 통계 데이터를 추출하고 있었다. 해당 데이터를 액세스 하는 과정에는 인덱스를 이용하고 있었다. 해당 SQL을 최적화한 후에는 1시간 동안 수행되던 SQL이 단지 50초 정도에 종료할 수 있었다. 최적화 하는 과정은 해당 SQL이 인덱스를 이용하지 못하게 하고 테이블을 전체 스캔하도록 변경해 주었다.
단지, 인덱스를 이용하는가 아니면 인덱스를 이용하지 않는가에 의해 이와 같이 큰 영향을 미치게 된 것이다. 다른 어느 사이트에서도 이러한 문제를 인식하지 못하고 당연히 오래 수행되는 작업이라고 생각하고 매일 작업을 수행하고 있는 사이트가 있을 것이다.
바로 이것이 SQL이 인덱스를 이용해야 하는지 이용해서는 안 되는지에 기준을 제시해 줄 것이다. 그렇다면 인덱스를 이용해야 할지 인덱스를 이용하면 안되는지에 대한 기준을 제시하는 요소는 무엇인가? 바로 액세스 하는 데이터의 양이다.
해당 테이블에서 많은 양의 데이터를 액세스 한다면 인덱스를 이용하여 테이블을 액세스 하는 경우에는 인덱스를 액세스 한 후 테이블을 액세스 하는 랜덤 액세스 가 발생하기 때문에 성능은 매우 저하된다. 이와 같은 경우라면 인덱스를 이용하여 테이블을 액세스 하는 방법보다는 인덱스를 이용하지 않고 테이블을 전체 액세스 하는 경우가 더 빠른 성능을 보장하게 될 것이다.
예를 들어, 1만개의 단어를 저장하고 있는 사전에서 5000개의 단어를 찾는다고 가정하자. 해당 사전은 한 페이지에 20개 씩의 단어가 기록되어 있으며 그렇기 때문에 전체 페이지는 500 페이지가 된다고 가정하자. 이와 같다면 여러분들은 사전의 인덱스를 이용하여 원하는 5000개의 단어를 찾을 것인가 아니면 사전의 인덱스를 이용하지 않고 테이블의 데이터를 액세스 할 것인가?
대부분의 사람들은 사전의 인덱스를 이용하지 않고 테이블의 데이터를 액세스 해야 더 빠른 성능을 보장할 수 있을 거라고 이야기한다. 이는 분명히 맞는 답이다. 20개의 단어가 저장되어 있는 하나의 페이지에서 평균 10개의 단어는 우리가 찾고자 하는 단어일 것이다. 이와 같은 경우 사전의 인덱스를 이용한다면 하나의 페이지를 10번씩 액세스 하게 된다. 하지만, 사전의 인덱스를 이용하지 않고 사전을 처음부터 끝까지 읽게 된다면 하나의 페이지에서 10개의 단어를 찾을 수 있기 때문에 우리는 하나의 페이지를 한번만 액세스 하면 될 것이다. 하나의 페이지를 10번 액세스 하는 것이 빠르겠는가 아니면 하나의 페이지를 한번만 액세스 하는 것이 빠르겠는가? 두 말할 것도 없이 하나의 페이지를 한번만 액세스 하는 것이 빠를 것이다. 이와 같은 차이에 의해 성능에 있어서는 엄청난 차이가 발생할 수 밖에 없게 된다.
결국, 인덱스를 이용해야 할지 아닐지는 액세스 하는 데이터의 양에 의해 좌우된다. SQL의 성능을 최적화하기 위해 무조건 인덱스를 생성해서는 안될 것이다. 해당 SQL이 테이블의 많은 데이터를 액세스 해야 한다면 인덱스를 이용하는 것보다는 테이블을 전체 스캔하는 방법이 성능을 보장한다는 것을 명심하길 바란다.
두 번째로 인덱스를 이용해야 하는 SQL을 확인해 보자. SQL은 위와 같이 테이블을 전체 스캔해야 하는 SQL을 제외하면 인덱스를 이용하여 데이터를 액세스 해야 할 것이다.
그렇다면 테이블의 데이터 중 어느 정도의 데이터를 액세스 하는 것이 많은 양의 데이터를 액세스 하는 것일까? 또는 어느 정도의 데이터를 액세스 해야 적은 양의 데이터를 액세스 하는 것일까? 일반적으로 해당 테이블의 3%~5% 정도의 데이터가 기준이 된다. 해당 테이블의 데이터가 10만건이라고 가정하자. 그렇다면 3000건에서 5000건의 데이터가 기준이 될 것이다. 따라서, 1000건의 데이터를 액세스 해야 한다면 인덱스를 이용하는 것이 성능을 보장할 수 있게 된다.
하지만 10만건의 데이터를 액세스 하는 경우에는 3%~5%의 기준을 넘게 되므로 인덱스를 이용하는 것보다는 인덱스를 이용하지 않는 것이 더 유리할 것이다. 테이블의 데이터가 대용량이라면 3%~5%의 기준 값은 낮아질 것이다. 그렇기 때문에 초 대용량 테이블은 1%가 기준이 되기도 한다. 이와 같은 정확한 기준 값이 중요한 것은 아니다.
중요한 것은 많은 데이터를 액세스 하는 SQL이 인덱스를 이용한다면 우리가 원하는 성능을 보장 받을 수 없으며 반대로 인덱스를 이용해야 하는 SQL이 인덱스를 이용하지 않는다면 이 또한 성능을 보장 받을 수 없다는 것이다.
이와 같기 때문에 SQL을 작성하는 경우 해당 SQL이 인덱스를 이용해야 할지 아니면 테이블을 전체 스캔해야 할지를 가장 먼저 고려해야 할 것이다. 이제는 맹목적으로 해당 SQL에 인덱스를 생성해야 성능을 보장 받을 수 있다는 잘못된 사실에서 벗어나야 할 것이다.
인덱스 컬럼들의 순서와 분포도는 많은 상관 관계가 없다
SQL에 필요한 인덱스를 생성한다면 우리는 많은 경우에 결합 인덱스를 생성하게 된다. 결합 인덱스를 생성하면서 많은 경우에는 해당 컬럼의 분포도를 고려하여 분포도가 좋은 컬럼을 인덱스의 첫 번째 컬럼으로 구성하는 경우를 많이 보았을 것이다. 과연, 이와 같이 분포도가 좋은 컬럼을 결합 인덱스의 첫번째 컬럼으로 선정하는 방식이 우리가 선택할 수 있는 최상의 인덱스 선정일까?
결론부터 언급하자면 결합 인덱스에서는 컬럼의 분포도는 의미가 없게 된다. 이 뜻은 결합 인덱스를 생성하는 경우 각 컬럼의 분포도는 의미가 없다는 것이다. 분포도를 고려하지 않고 결합 인덱스를 생성한다는 것은 말이 되지 않는다고 할 수도 있을 것이다. 하지만, 분명한 것은 결합 인덱스에서의 분포도는 큰 의미를 가지지 않는다. 왜 이와 같은 현상이 발생하는 것일까?
카드 회사에서 카드 가입자의 카드번호만을 관리하는 테이블에서 카드번호 컬럼은 분포도가 매우 좋을 것이다. 하지만, 여기서 우리는 하나의 함정에 빠지게 된다. 그것은 무엇인가? 바로 분포도가 좋다는 뜻에 대한 함정이다. 우리가 카드번호 값에 대해 분포도가 좋다는 뜻은 무엇을 의미하는가? 이는 하나의 카드번호만을 액세스 하는 경우에 해당할 것이다.
모든 카드번호는 ‘1’로 시작한다고 가정하자. 만약, 카드번호 값에 대해 ‘1’로 시작하는 카드번호 값을 액세스 한다면 분포도는 어떠한가? 이와 같이 데이터를 액세스 한다면 아무리 분포도가 좋은 카드번호 컬럼도 많은 데이터가 추출되며 분포도는 안 좋게 된다. 결국, 우리가 항상 이야기 하는 분포도가 좋은 컬럼과 분포도가 나쁜 컬럼 컬럼의 기준에는 우리도 모르게 동일한 데이터를 액세스 하는 경우를 의미하게 된다.
‘111111’번 카드번호 값을 액세스 한다면 우리가 원하는 데이터는 한건의 데이터가 되므로 분포도는 좋게 된다. 하지만, SQL에서 ‘1’로 시작하는 모든 카드번호 데이터를 액세스 한다면 분포도는 나쁘게 된다. 이와 같이 우리가 말하는 분포도는 서로 약속은 안 했지만 해당 컬럼의 값과 동일한 데이터를 추출하는 경우에 해당하게 된다.
결국, 우리가 말하는 분포도는 동일한 값을 의미하게 된다. 하지만, 우리가 추출하고자 하는 데이터는 항상 동일한 데이터만을 의미하지는 않게 된다. 때로는 LIKE 연산자 또는 BETWEEN 연산자 등을 많이 이용하기 때문에 이런 경우라면 해당 컬럼의 분포도는 의미 없게 된다. 이와 같은 이유에서 해당 컬럼의 분포도는 더 이상 결합 인덱스를 생성하는 컬럼의 순서에 중요한 역할을 수행하지 못하게 된다.
인덱스 컬럼들의 순서를 효과적으로 선정하자
인덱스를 구성하는 각각의 컬럼의 분포도가 중요하지 않다면 결합 인덱스를 구성하는 컬럼의 순서를 고려할 경우 가장 먼저 고려해야 하는 요소는 무엇인가? 결합 인덱스를 구성할 경우 우리가 반드시 고려해야 하는 요소는 아래와 같다.
점 조건과 선분 조건
결합 인덱스의 순서를 정하는 가장 중요한 요소는 해당 컬럼에 사용되는 연산자이다. 아직도 많은 교육과 문서에서 컬럼의 분포도가 인덱스 선정에 중요하다고 언급하는 경우가 있다. 하지만, 이러한 것이 우리에게 많은 오류를 발생시킨다는 것을 이해하길 바란다. 가장 중요한 요소는 해당 컬럼을 액세스 하는 연산자라는 것을 명심하길 바란다. 위에서 점 조건에는 =과 IN 연산자만이 포함되며 나머지 연산자는 선분 조건에 해당된다.
SQL> SELECT …… FROM TAB1 WHERE COL1 = ‘A’ AND COL2 BETWEEN ‘A’ AND ‘B’;
위와 같은 SQL이 수행되며 각 컬럼의 분포도는 COL1 컬럼의 경우에는 분포도가 좋으며 COL2 컬럼의 경우에는 분포도가 좋지 않다고 가정하자. 그렇다면 많은 사람들은 분포도만을 고려하여 COL2+COL1 인덱스를 생성하려고 하는 경우가 많다. 하지만, COL2 컬럼은 BETWEEN 연산자를 사용했으므로 해당 컬럼의 분포도는 의미가 없게 된다. 따라서, 위의 SQL에서 최적의 인덱스는 COL1+COL2 인덱스가 된다.
결국, 분포도를 배제하고 연산자를 통해 결합 인덱스를 생성해야 한다. 이와 같이 인덱스를 구성해야만 COL1 컬럼과 COL2컬럼에 의해 처리 범위가 감소하게 된다. 앞의 값의 하나의 값이 아닌 선분 조건이라면 처리 범위는 증가하기 때문이다. 결합 인덱스는 반드시 아래와 같은 특성을 가지게 된다.
● 점 조건+점 조건: 두 컬럼에 의해 처리 범위 감소 ● 점 조건+선분 조건: 두 컬럼에 의해 처리 범위 감소 ● 선분 조건+선분 조건: 앞의 선분 조건에 의해서만 처리 범위 감소 ● 선분 조건+점 조건: 앞의 선분 조건에 의해서만 처리 범위 감소
위와 같이 컬럼의 분포도가 아닌 컬럼의 연산자에 의해 인덱스는 처리 범위를 감소시키게 되며 처리 범위를 가장 많이 감소시킬 수 있는 형태의 결합 인덱스만이 성능을 보장할 수 있게 된다. 분포도에 의한 결합 인덱스 선정이 아닌 연산자에 의한 결합 인덱스 선정의 중요성을 인식하길 바란다. 이것이야 말로 해당 SQL의 성능을 보장할 수 있는 유일한 방법이다.
SQL을 작성한 후 무조건 인덱스를 만들려고 하는 생각과 결합 인덱스에서 연산자를 고려하지 않고 분포도가 좋은 컬럼을 앞에 위치시키는 인덱스야 말로 성능을 저하시키는 주범이 된다. 이제부터 최적의 인덱스를 선정하기 위해 우리 함께 노력해야 할 것이다. 인덱스에 대한 우리가 쉽게 빠질 수 있는 함정에 빠지지 않게 항상 주의해야 할 것이다.
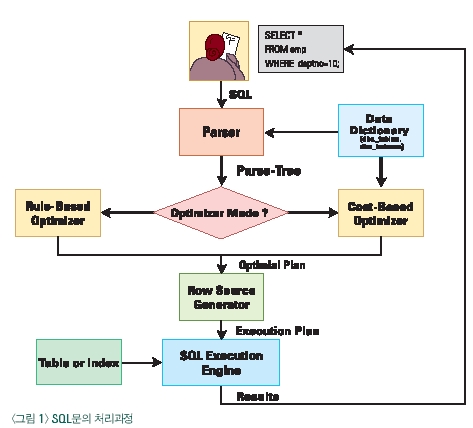
이번호 technical tips에서는 SQL문의 성능을 결정하는 비용기반 옵티마이저의 핵심 원리 중에 비용계산 방법에 대해 알아 보도록 하겠다. 대부분의 개발자들이 작성하는 SQL문은 비용기반 옵티마이저 환경에서 작성된 실행계획을 통해 실행 되어지는데, 이때 옵티마이저의 비용계산 방법에 대해 정확히 이해한다면 더 좋은 성능을 보장 받는 SQL문을 작성할 수 있을 것이다.
옵티마이저의 비용계산 방법을 소개하기 전에 우선 SQL문의 처리과정의 대해 알아보자. 사용자가 실행하는 SQL문은 파서(Parser)에게 전달되고 파서는 데이터 딕셔너리 정보를 참조하여 SQL문에 대한 구문분석(Syntax와 Symantics)을 수행한다. 이 결과를 파스-트리(Parse-Tree)라고 한다. 파스-트리는 옵티마이저에게 전달되는데 오라클 데이터베이스에는 공식기반 옵티마이저(Rule-Based Optimizer)와 비용기반 옵티마이저(Cost-Based Optimizer)가 있다. 비용기반 옵티마이저에 의해 산출된 적정 플랜(Optimal Plan)은 로우 소스 생성기(Row Source Generator)에게 전달되고 이것은 실행 계획(Execution Plan)으로 결정된다. 우리가 SET AUTOTRACE, SQL*TRACE와 TKPROF와 같은 튜닝 도구들을 통해 참조할 수 있는 결과에 바로 이 실행계획이 포함되어 있다. 이 실행계획은 SQL 실행엔진(SQL Execution Engine)에 의해 테이블과 인덱스를 참조하여 그 결과를 사용자에게 리턴하게 되는 것이다.
이어서, 비용기반 옵티마이저가 어떤 비용계산 방법을 통해 적절한 실행 계획을 찾아내는지를 소개할 것이다. 개발작업 때 처음부터 좋은 실행계획을 작성할 수 있도록 SQL문을 작성한다면 SQL 튜닝에 대한 불필요한 시간과 비용을 줄여 나감으로써 좋은 성능의 시스템을 개발할 수 있는 첫걸음이 되는 것이다.
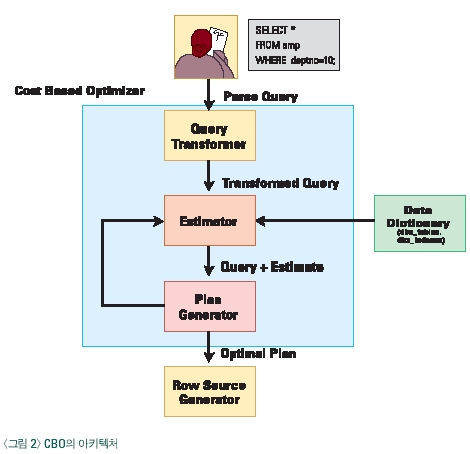
2. 비용기반 옵티마이저의 구조
이번에는 구체적으로 비용기반 옵티마이저의 아키텍처에 대해 알아보도록 하겠다. CBO(Cost Based Optimizer)가 어떻게 비용을 계산하고 어떻게 실행계획을 작성하는지를 알기 위해서는 보다 구체적으로 CBO의 아키텍처의 대해 알고 있어야 한다. <그림 2>에서와 같이 CBO는 쿼리 변형기(Query Transformer), 비용 계산기(Estimator), 쿼리 작성기(Query Generator) 3가지 구조로 구성되어 있다. 그럼, 각 구성 요소와 비용계산 알고리즘을 통해 실행계획 작성 방법에 대해 알아 보자.
3. 쿼리 변형기(Query Transformer)
쿼리 변형기는 파서(Parser)에 의해 구문 분석된 결과를 전달 받아 잘못 작성된 SQL문을 정확한 문장으로 변형시키는 역할을 수행한다.
? 잘못된 데이터 타입으로 조건 값을 검색하면 변형된다. (S_DATE 컬럼은 날짜 컬럼인데 문자 값을 검색할 때 사용하는 인용부호를 사용한 경우)
SQL> SELECT * FROM emp WHERE s_date = '1999-01-01'; --> SQL> SELECT * FROM emp WHERE s_date = TO_DATE('1999-01-01');
? LIKE 연산자는 %(와일드 카드)와 함께 검색하는 경우 사용되지만, 그렇지 않은 경우 =(동등) 조건으로 변형되어 검색된다.
SQL> SELECT * FROM emp WHERE ename LIKE '주종면‘; --> SQL> SELECT * FROM emp WHERE ename = ‘주종면’;
? BETWEEN ~ AND 조건은 > AND < 조건으로 변형되어 검색된다.
SQL> SELECT * FROM emp WHERE salary BETWEEN 100000 AND 200000; --> SQL> SELECT * FROM emp WHERE salary >= 100000 and salary <= 200000;
? 인덱스가 생성되어 있는 컬럼의 IN 연산자의 조건은 OR 연산자의 조건으로 변형된다.
SQL> SELECT * FROM emp WHERE ename IN ('SMITH', 'KING'); --> SQL> SELECT * FROM emp WHERE ename = 'SMITH' or ename = 'KING';
? 인덱스가 생성되어 있는 컬럼의 OR 연산자의 조건은 UNION ALL로 변형된다.
SQL> SELECT * FROM emp WHERE ename = 'SMITH' or sal = 1000; SQL> SELECT * FROM emp WHERE ename = 'SMITH' UNION ALL SELECT * FROM emp WHERE sal = 1000;
이와 같이 쿼리 변형기는 부적절하거나 잘못 작성된 SQL문장을 정확한 문장으로 변형시켜주는 역할을 수행하는 알고리즘이다.
4. 비용 계산기(Estimator)
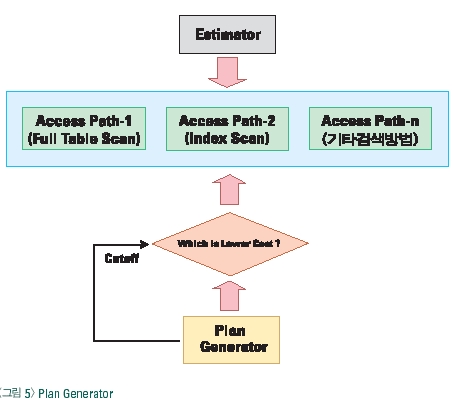
비용 계산기는 비용기반 옵티마이저가 가지고 있는 비용 계산 공식에 의해 다양한 실행방법 중에 가장 좋은 성능의 실행계획을 찾아 주는 알고리즘이다.
1) 테이블과 인덱스의 통계정보
먼저, ANALYZE 명령어에 의해 수집되는 통계정보의 상태와 용어에 대해 설명하겠다. 먼저, 테이블에 대한 통계정보이다.
NUM_ROWS : 인덱스 행 수 L_BLOCKS : 하나의 LEAF 블록에 저장되어 있는 인덱스 키의 수 D_BLOCKS : 하나의 DATA 블록에 저장되어 있는 인덱스 키의 수 CL-FAC : CLUSTER FACTOR BLEVEL : INDEX의 DEPTH LEAF : LEAF 블록의 수
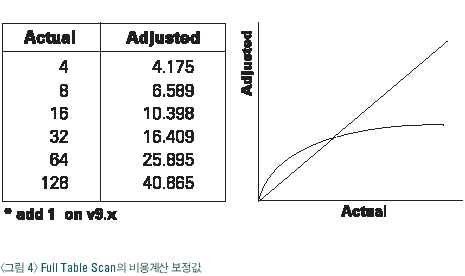
통계 정보는 오라클 10g 이전 버전까지는 사용자가 실행하는 ANALYZE 명령어에 의해 생성되었으며 10g 버전부터는 오라클 서버의 자동화된 알고리즘에 의해 자동 생성된다. 오라클 9i 버전 때까지는 사용자에 의해 통계정보를 생성해 주지 않으면 비용기반 옵티마이저는 부정확한 실행계획을 작성함으로써 성능이 저하되는 경우들이 많이 발생했었다. <그림 3>은 통계정보가 생성되어 있지 않은 경우 비용기반 옵티마이저가 참조하는 통계정보의 기본 값이다. 데이터를 저장하고 있는 테이블과 인덱스의 실제 구조정보와 다른 값을 참조하기 때문에 결론적으로 좋은 실행계획을 작성하지 못하는 것이다.
2) 용어에 대한 이해 SQL> SELECT * FROM big_emp;
Execution Plan ---------------------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=19 Card=28955 Bytes=1042380) 1 0 TABLE ACCESS (FULL) OF 'BIG_EMP' (Cost=19 Card=28955 Bytes=1042380)
COST : SQL문을 실행하여 조건을 만족하는 행을 검색하는데 소요되는 횟수 CARDINALITY : 전체 테이블에서 SQL문의 조건을 만족하는 행 수
3) Cardinality
일반적으로 cardinality는 SQL문이 실행되었을 때 조건을 만족하는 행수를 의미하는 것이긴 하지만 이것은 검색되는 컬럼이 어떤 속성을 가지고 있느냐에 따라 계산 공식이 달라진다.
3-1) Distinct Cardinality(Unique-Key)인 경우
이 경우는 주로 Full Table Scan과 같이 테이블 전체 행을 검색하는 경우의 cardinality를 계산하는 공식이다.
SQL> SELECT count(*) FROM big_dept; count(*) ------------------ 289
SELECT * FROM emp WHERE empno > 200; --> Selectivity = (범위값 - 최소값) / (최대값 - 최소값) = (29799 - 1) / (29999 - 1) = 29798 / 29998 = 0.9 SELECT * FROM emp WHERE empno BETWEEN 100 AND 200; --> Selectivity = (최대 조건값 - 최소 조건값) / (최대값 - 최소값) = (200 - 100) / (29999 - 1) = 100 / 29998 = 0.003
4-4) 바인드 변수를 가진 비동등식의 경우
SELECT * FROM emp WHERE empno < :a ; --> Selectivity = 0.25 % (나쁜 선택도)
SELECT * FROM emp WHERE empno BETWEEN :a AND :b ; --> Selectivity = 0.5 % (나쁜 선택도)
5. 비용 계산 방법
지금까지 비용기반 옵티마이저가 비용을 계산하기 위해 알아야 할 여러 가지 내용에 대해 알아보았다. 그럼 지금부터는 다양한 SQL문의 비용 계산 공식에 대해 알아보자.
5-1) Full Table Scan인 경우
Cost = 전체 블록 수 / DB_FILE_MULTIBLOCK_READ_COUNT의 보정 값
인덱스를 사용하지 않고 해당 테이블의 첫 번째 블록부터 전체 블록을 검색해야 하는 전체 테이블 스캔의 경우에는 init.ora 파일에 정의되어 있는DB_FILE_MULTOBLOCK_READ_COUNT 파라메터 값에 의해 비용이 계산된다. 이 파라메터는 FULL TABLE SCAN의 경우 한번에 하나의 I-O로는 성능을 기대할 수 없기 때문에 보다 빠른 성능을 기대하기 위해 제공되는 다중 블록 읽기를 위한 파라메터이다. 즉, 한번 I-O에 8개, 16개, 32개, 64개의 다중 블록을 읽게 하기 위함이다.
SQL> SHOW PARAMETER db_file_multiblock_read_count NAME TYPE VALUE ------------------------------------------------------------------------------------- db_file_multiblock_read_count integer 16 SQL> SELECT * FROM big_emp;
Execution Plan ---------------------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=19 Card=28955 Bytes=1042380) 1 0 TABLE ACCESS (FULL) OF 'BIG_EMP' (Cost=19 Card=28955 Bytes=1042380)
앞에서 소개된 비용 계산 공식을 적용해보면 COST = 180 / 16 = 11.25의 결과가 나와야 하는데 실제 비용은 COST=19의 결과가 계산되었다 !! 이것은 DB_FILE_MULTIBLOCK_READ_COUNT 파라메터의 실제 값처럼 한번 I-O에 8, 16, 32, 64개의 블록을 읽을 수는 없기 때문에 파라메터의 실제 값이 아닌 보정 값으로 비용을 계산했기 때문이다. <그림 4>의 왼쪽 표는 ACTUAL (DB_FILE_MULTIBLOCK_READ_COUNT 파라메터 값)에 따른 Adjusted(보정 값)이며 <그림 4>의 오른쪽 그림은 이 파라메터가 실제로 성능의 영향을 미치게 되는 영향도를 그림으로 나타낸 것이다. 즉, COST = 19는 (180 / 10.398) +1의 계산 공식 결과임을 알 수 있다. 사용자가 실행하는 SQL문의 실행계획이 FULL TABLE SCAN으로 결정되도록 유도하기 위해서는 이 파라메터 값을 조절하면 된다.
SQL> ALTER SESSION SET db_file_multiblock_read_count = 8; SQL> SELECT * FROM big_emp;
Execution Plan ------------------------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=29 Card=28955 Bytes=1042380) 1 0 TABLE ACCESS (FULL) OF 'BIG_EMP' (Cost=29 Card=28955 Bytes=1042380)
위 SQL문의 비용은 Cost = (180 / 6.589) + 1 = 29 이다. 파라메터 값의 변경에 따라 비용이 달라지는 것을 확인할 수 있을 것이다.
SQL> ALTER SESSION SET db_file_multiblock_read_count = 32; SQL> SELECT * FROM big_emp;
Execution Plan ------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=13 Card=28955 Bytes=1042380) 1 0 TABLE ACCESS (FULL) OF 'BIG_EMP' (Cost=13 Card=28955 Bytes=1042380)
위 SQL문의 비용은 Cost = (180 / 16.409) + 1 = 13이다.
5-2) Unique Index Scan인 경우
Cost = blevel + 1
UNIQUE INDEX를 이용한 비용은 LEAF 블록의 DEPTH +1 이 된다.
SQL> CREATE UNIQUE INDEX I_big_emp_empno ON BIG_EMP (EMPNO); SQL> ANALYZE INDEX I_big_emp_empno compute statistics;
SQL> SELECT INDEX_NAME, BLEVEL FROM USER_INDEXES WHERE INDEX_NAME = 'I_BIG_EMP_EMPNO';
SQL> SELECT /*+index(big_emp I_big_emp_empno )*/ ename FROM big_emp WHERE empno = 7499; -------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=1 Bytes=20) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'BIG_EMP' (Cost=2 Card=1 Bytes=20) 2 1 INDEX (UNIQUE SCAN) OF 'I_BIG_EMP_EMPNO' (UNIQUE) (Cost=1 Card=100)
위 SQL문의 비용은 Cost = 1 + 1 = 2이다.
5-3) Fast Full Index Scan인 경우
Cost = leaf_blocks / db_block_size
SQL> CREATE INDEX emp_job_deptno ON BIG_EMP (job, deptno); SQL> ANALYZE INDEX emp_job_deptno compute statistics; SQL> SELECT INDEX_NAME, LEAF_BLOCKS FROM USER_INDEXES WHERE INDEX_NAME = 'EMP_JOB_DEPTNO';
SQL> SELECT /*+INDEX(BIG_EMP i_big_emp_deptno)*/ * FROM BIG_EMP WHERE DEPTNO = 10 ;
Execution Plan ------------------------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=53 Card=294 Bytes=10584) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'BIG_EMP' (Cost=53 Card=294 Bytes=10584) 2 1 INDEX (RANGE SCAN) OF 'I_BIG_EMP_DEPTNO' (NON-UNIQUE) (Cost=1 Card=294)
위 SQL문의 비용은 Cost = 1 + (1/98 * 57) +(1/98 * 5036) = 53이다.
SQL> ALTER SESSION SET optimizer_index_cost_adj = 50; SQL> SELECT /*+INDEX(BIG_EMP)*/ * FROM BIG_EMP WHERE DEPTNO = 10 ;
Execution Plan ------------------------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=27 Card=294 Bytes=10584) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'BIG_EMP' (Cost=27 Card=294 Bytes=10584) 2 1 INDEX (RANGE SCAN) OF 'I_BIG_EMP_DEPTNO' (NON-UNIQUE) (Cost=1 Card=294)
위 SQL문의 비용은 Cost = 53 X 0.5 = 27이다.
SQL> ALTER SESSION SET optimizer_index_cost_adj = 150; SQL> SELECT /*+INDEX(BIG_EMP)*/ * FROM BIG_EMP WHERE DEPTNO = 10 ;
Execution Plan ------------------------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=80 Card=294 Bytes=10584) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'BIG_EMP' (Cost=80 Card=294 Bytes=10584) 2 1 INDEX (RANGE SCAN) OF 'I_BIG_EMP_DEPTNO' (NON-UNIQUE) (Cost=1 Card=294)
위 SQL 문의 비용은 Cost = 53 X 1.5 = 80이다.
5-5) Sort-Merge Join인 경우
다음은 소트-머지 조인의 경우 비용 계산 공식이다. Cost = (Outer 테이블의 Sort Cost +Inner 테이블의 Sort Cost) -1 SQL> SELECT /*+use_merge(big_dept big_emp)*/ * FROM big_emp, big_dept WHERE BIG_EMP.DEPTNO = BIG_DEPT.DEPTNO;
사용자가 실행한 SQL문은 쿼리 변형기의 비용 계산기에 의해 여러 가지 유형의 실행계획으로 비용 분석된다. 그 중에 가장 적은 비용으로 실행되어질 수 있는 실행계획 하나가 선택되는데 이것을 Optimal Plan이라고 한다. 다음 문장들은 동일한 결과를 제공하지만 실행계획 생성기에 의해 가장 적은 비용의 실행계획을 선택한 결과이다.
6-1) 적정 플랜(Optimal Plan)
Index Scan인 경우
SELECT ename FROM big_emp WHERE deptno = 20 AND empno BETWEEN 100 AND 200 ORDER BY ename; Execution Plan ------------------------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=9 Card=1 Bytes=12) 1 0 SORT (ORDER BY) (Cost=9 Card=1 Bytes=12) 2 1 TABLE ACCESS (BY INDEX ROWID) OF 'BIG_EMP' (Cost=5 Card=1 Bytes=12) 3 2 INDEX (RANGE SCAN) OF 'I_BIG_EMP_EMPNO' (UNIQUE) (Cost=2 Card=1)
이 실행계획은 비용기반 옵티마이저에 의해 I_BIG_EMP_EMPNO 인덱스가 선택되었으며 이때 계산된 I-O COST는 9이다. I_BIG_EMP_DEPTNO 인덱스가 선택된 경우
SELECT /*+index(big_emp I_BIG_EMP_DEPTNO)*/ ename FROM big_emp WHERE deptno = 20 AND empno BETWEEN 100 AND 200 ORDER BY ename;
Execution Plan ------------------------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=70 Card=1 Bytes=12) 1 0 SORT (ORDER BY) (Cost=70 Card=1 Bytes=12) 2 1 TABLE ACCESS (BY INDEX ROWID) OF 'BIG_EMP' (Cost=66 Card=1 Bytes=12) 3 2 INDEX (RANGE SCAN) OF 'I_BIG_EMP_DEPTNO' (NON-UNIQUE) (Cost=2 Card=1)
이 실행계획은 I_BIG_EMP_DEPTNO 인덱스가 선택되었으며 이때 계산된 I-O COST는 70이다.
Full Table Scan인 경우
SELECT /*+full(big_emp)*/ ename FROM big_emp WHERE deptno = 20 AND empno BETWEEN 100 AND 200 ORDER BY ename; Execution Plan ------------------------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=61 Card=1 Bytes=12) 1 0 SORT (ORDER BY) (Cost=61 Card=1 Bytes=12) 2 1 TABLE ACCESS (FULL) OF 'BIG_EMP' (Cost=57 Card=1 Bytes=12)
이 실행계획은 Full Table Scan이 선택되었으며 이때 계산된 IO COST는 61이다. 결론적으로, 5-1, 5-2, 5-3의 SQL문장들은 동일한 문장, 동일한 결과를 제공하지만 이 문장이 실행될 수 있는 실행계획은 다양하다는 것을 알 수 있다. 이와 같이, 비용기반 옵티마이저는 여러 가지 실행계획 중에 가장 비용이 적게 발생하는 I_BIG_EMP_EMPNO 인덱스를 이용한 실행계획을 Optimal Plan으로 선택하게 된다.
6-2) 비용계산 분석 명령어
다음 문장은 비용분석기(Estimator)와 실행계획 생성기(Plan Generator)에 의해 비용 분석된 결과를 모니터링 하는 방법이다. SQL> ALTER SESSION SET EVENTS '10053 trace name context forever, level 1'; SQL> SELECT * FROM BIG_EMP, BIG_DEPT, ACCOUNT WHERE BIG_EMP.DEPTNO = BIG_DEPT.DEPTNO AND ACCOUNT.CUSTOMER = BIG_EMP.EMPNO SQL> EXIT [C:\] CD C:\ORACLE\ADMIN\ORA92\UDUMP [C:\] DIR ORA92_ORA_xxxx.trc <-- 워드패드 편집기를 통해 결과 확인
<분석결과>
*** 2005-07-17 10:41:27.000 *** SESSION ID:(10.976) 2005-07-17 10:41:27.000 QUERY SELECT * FROM BIG_EMP, BIG_DEPT, ACCOUNT WHERE BIG_EMP.DEPTNO = BIG_DEPT.DEPTNO AND ACCOUNT.CUSTOMER = BIG_EMP.EMPNO
분석된 결과 중에 Join order[n]는 여러 개의 테이블을 조인하는 경우 어떤 테이블부터 검색하여 어떤 순서에 의해 조인해 나가는 방법인지 분석하는 경우를 나타낸다. Join order[1]에서 Best NL cost: 5493은 중첩루프 조인의 비용 결과이며, Best SM cost : 257은 소트-머지 조인의 경우 비용 결과이다. 비용기반 옵티마이저는 하나의 조인순서가 결정되면 다양한 실행 방법들에 대한 비용을 일일이 계산하게 된다. 그 중에 가장 적은 비용이 발생하는 조인 순서와 실행 방법을 실행 계획으로 선택하게 되는 것이다.
데이터베이스 관련 책을 읽다보면 Relation과 Table을 같은 용어로 이야기하는 경우가 있다.
어떤 책의 경우 "릴레이션이 테이블이다." 라고 되어있다. 하지만 사실상 릴레이션은 테이블과는 약간 다르다. 결론적으로 말하자면 릴레이션은 모두 테이블이지만 모든 테이블이 다 릴레이션은 아니라는 이야기다.
Codd, E.F의 "A Reational Model of Data for Larger Shared Databanks"의 논문에 보면 릴레이션의 특징을 정의하였다.
행은 개체에 대한 데이터를 포함한다.
열은 개체의 속성에 대한 데이터를 포함한다.
한 열의 모든 항목은 동일한 종류다.
각 열은 유일한 이름을 가진다.
테이블의 셀은 단일 값을 포함한다.
열의 순서는 중요하지 않다.
행의 순서는 중요하지 않다.
어떤 두개의 행도 동일하지 않다.
아래는 DAVID M. KROENKE의 DATABASE PROCESSING이라는 책에서 나온 해설이다.
테이블이 릴레이션이 되기 위해서는 테이블의 행들이 개체에 대한 데이터를 저장해야하고, 테이블들의 열이 그 개체들의 특성에 대한 데이터를 저장해야 한다. 릴레이션은 한 열의 모든 값들이 동일한 종류여야 한다.
예를 들어 어떤 릴레이션의 첫번째 행의 두번째 열이 FirstName을 가진다면 그 릴레이션의 모든 행의 두번째 열도 FistName을 가져야 한다. 또한 열의 이름은 유일해야 한다. 즉 동일 릴레이션에 속한 두 열은 같은 이름을 가질 수 없다.
릴레이션의 각 Cell은 단일한 값 또는 항목만 가진다. 다중 항목은 허용되지 않는다. (제 1 정규화)
마지막으로 주어진 테이블이 릴레이션이 되기 위해서는 동일한 행이 존재하면 안된다.
간단한 예를 들면
위의 표는 테이블이지만 릴레이션은 아니다.
사원번호 300의 오돌이가 복수로 테이블 안에 저장되어 있기 때문이다.
릴레이션 특성에서 "어떤 두개의 행도 동일하지 않다."를 위반했다.
또 하나의 예를 들면
이 표도 역시 테이블이지만 릴레이션은 아니다.
릴레이션의 특성에서 "테이블의 셀은 단일 값을 포함한다."를 위반하였다.
RDBMS 이론이 소개 된 지 어느덧 30년이 지났다. 30년의 긴 세월이 흐르면서 RDBMS는 우리의 일상에도 많은 부분을 차지하게 된 것 같다. 우리가 사용하는 대부분의 웹 사이트에서 RDBMS를 사용하고 있으며 이로 인해 우리의 정보는 체계적으로 관리되고 있을 것이다. RDBMS의 보급화와 함께 RDBMS의 기술은 계속 향상되고 있지만 이 중에서 RDBMS의 탄생과 함께 태어난 조인은 그 중요성에 비해 많은 천대를 받는 것 같다. 이제라도 우리는 RDBMS의 꽃인 조인을 정확히 이해해 보자.
권순용 | kwontra@hanmail.net
지금도 수많은 사이트에서 데이터 연결에 대한 불신을 가지고 있는 것이 현실이다. 어떤 사이트에 가보면 데이터 연결 방법 중에 하나인 조인을 사용하지 못하게 하고 또 어떤 사이트에 가보면 서브쿼리를 사용하지 못하게 하는 것을 지켜보는 경우가 있었다. 물론, 서브쿼리도 데이터 연결의 한가지 방법이며 조인과 거의 유사하게 수행된다.
분명 조인은 RDBMS의 꽃이며 이러한 핵심 기술을 이용하지 않는다면 RDBMS를 이용해서 무슨 효과를 기대할 수 있겠는가? 조인의 실제 수행 방식을 이해하지 않으려 하고 조인을 잘못 사용했기 때문에 나타나는 현상을 그대로 받아들이고 그것만을 가지고 모든 것을 평가하는 것이 현실인 것 같다.
조인의 수행 방식을 정확히 이해했다면 우리는 이와 같은 성능 저하 현상을 바로 잡을 수 있다는 사실을 명심해야 할 것이다. ‘조인은 성능을 저하시킨다’는 잘못 알고 있는 사실을 다시 확인해 보는 기회로 삼아보았으면 좋겠다.
조인은 데이터를 감소시킨다
조인은 현재 데이터베이스의 크기를 감소시킬 수 있는 유일한 방법이다. 이와 같이 이야기한다면 의아해 할 것이다. 조인이 어떻게 데이터베이스의 크기를 감소시킬 수 있겠는가? 당연히 조인을 이용하여 데이터베이스의 크기를 감소시킬 수는 없다.
여기서 말하는 것은 데이터베이스의 정규화를 거치게 되면 데이터베이스에 존재하는 테이블은 분리되며 테이블이 분리된다면 일반적으로 데이터베이스의 크기는 감소하게 된다. 이와 같이 테이블을 분리하여 두 개 이상의 테이블에서 우리가 원하는 데이터를 추출하기 위해서는 조인을 이용해야 한다는 것이다.
이와 같기 때문에 정확히 이야기한다면 데이터를 감소시키기 위해 조인을 사용한다기 보다는 크기가 감소된 데이터에 대해 조회를 수행하기 위해 조인을 사용한다는 것이다.
예를 들어, 어느 회사에 직원 테이블이 존재하며 또 하나의 경우는 사원 테이블과 부서 테이블이 별도로 존재한다고 가정하자. 회사에는 1,000,000명의 직원이 존재하며 해당 회사에는 1,000개의 팀이 존재한다고 가정하자. 그렇다면 아래와 같이 구성될 수 있을 것이다.
<그림>처럼 테이블을 구성했다고 가정하자. 그렇다면 각각의 테이블의 크기는 어떻게 되겠는가? 먼저, 직원 테이블을 확인해 보자. 직원 테이블의 하나의 데이터의 길이는 1055Byte의 길이이다. 또한, 직원 테이블에는 1,000,000건의 데이터가 저장되므로 해당 테이블의 전체 크기는 데이터만 1,000,000건*1055Byte=1055MB가 되므로 약 1GB 정도의 크기가 된다. 그렇다면 위의 그림에서 밑에 존재하는 사원 테이블과 부서 테이블을 분리한 경우는 어떠한가?
<그림> 조인이 필요없는 테이블과 조인이 필요한 테이블
사원 테이블은 1,000,000건의 데이터가 저장되어 있으며 하나의 데이터의 길이는 535Byte가 된다. 사원 테이블의 전체 데이터 건수는 1,000,000건이므로 1,000,000*535 Byte = 535MB가 되므로 사원 테이블의 크기는 535MB 정도가 된다. 그렇다면 부서 테이블의 크기는 어떠한가? 부서 테이블의 하나의 데이터의 길이는 525 Byte가 된다.
부서 테이블에는 1,000건의 데이터가 존재하므로 테이블의 전체 크기는 1,000*530Byte이므로 530KB의 크기가 된다. 따라서 위의 그림의 아래와 같이 부서 테이블과 사원 테이블로 구성한다면 두 테이블의 크기를 모두 합해도 535MB 정도의 크기가 될 것이다.
그렇다면 위의 테이블 크기 및 구조를 통해 우리는 무엇을 알 수 있겠는가? 우리가 유추해 낼 수 있는 항목은 크게 두 가지이다.
첫 번째로 두 가지 경우에 대해 모든 데이터를 추출하기 위해 액세스해야 하는 데이터의 양이다. 위의 그림에서 직원 테이블로만 구성되어 있는 경우를 확인해 보자. 직원 테이블의 데이터를 모두 추출하고자 한다면 직원 테이블의 크기만큼 디스크 I/O가 발생하게 된다. 따라서, 직원 테이블의 크기인 1055MB만큼의 디스크 I/O가 발생하게 된다.
반면에 위의 그림에서 사원 테이블과 부서 테이블을 분리한 경우는 어떠한가? 사원 테이블과 부서 테이블을 액세스하여 모든 데이터를 추출해야 한다면 각각의 테이블을 모두 액세스해야 할 것이다. 그렇기 때문에 위에서 계산한 것과 같이 535MB의 디스크 I/O가 발생하게 된다.
이와 같다면 과연 어떻게 테이블을 구성해야 하겠는가? 물론, 위의 그림에서 테이블을 어떻게 구성하는가에 상관 없이 결과는 동일한 데이터가 추출될 것이다. 직원 테이블로만 구성한 경우에는 1055MB의 디스크 I/O를 발생시키게 되며 사원 테이블과 부서 테이블로 분리하여 모든 데이터를 액세스한다면 535MB의 디스크 I/O를 발생시키게 된다.
디스크 I/O를 통해 확인한다면 직원 테이블로 구성하는 것보다는 사원 테이블과 부서 테이블로 분리하는 형태를 선택해야 할 것이다. 사원 테이블과 부서 테이블로 분리하는 형태를 선택한다면 우리는 더 적은 디스크 I/O를 통해 원하는 모든 데이터를 추출할 수 있을 것이다.
두 번째로 원하는 데이터를 추출하기 위한 데이터의 액세스 방법을 예상할 수 있을 것이다. 직원 테이블 하나로 구성하는 경우에는 하나의 테이블만 존재하게 되므로 하나의 테이블을 통해 모든 데이터를 액세스할 수 있게 된다.
그렇기 때문에 인덱스가 존재한다면 인덱스를 이용하는 수행 방식을 이용하거나 또는 인덱스가 존재하지 않는다면 인덱스를 이용하지 않고 테이블을 처음부터 끝까지 액세스하게 될 것이다. 반면에 사원 테이블과 부서 테이블로 분리하는 경우는 두 테이블의 데이터를 동시에 추출하기 위해서는 조인을 사용해야 할 것이다.
이와 같이 테이블을 분리한다면 전체 데이터의 크기는 감소한다. 데이터의 감소는 우리에게 많은 혜택을 주게 된다. 이러한 데이터의 감소를 위해서는 테이블을 분리해야 하며 분리된 테이블에서 원하는 데이터를 추출하기 위해서는 조인을 이용해야 한다. 이처럼 대용량 데이터베이스의 데이터를 감소시키기 위해서는 조인은 필수 불가결할 것이다.
조인을 수행하기 위한 경우의 수를 이해하자
조인을 수행하기 위해서는 다양한 경우의 수가 존재한다고 것을 이해하겠는가? 그렇다면 과연 조인 방식에는 어느 정도 다양한 경우의 수가 존재하는 것일까? 그 중 어떤 조인 방식이 최적의 성능을 보장하겠는가? 이제부터 조인을 수행하기 위한 경우의 수에 대해 확인해 보자.
SQL> SELECT COL1, COL2, COL3 FROM TAB1, TAB2, TAB3 WHERE TAB1.KEY1 = TAB2.KEY2 AND TAB2.KEY2 = TAB3.KEY3;
위와 같은 기본적인 조인 SQL을 수행한다고 가정하자. SQL은 데이터베이스에 존재하는 테이블의 데이터를 액세스하는 언어이다. 그렇다면 위의 조인 SQL이 수행될 수 있는 경우의 수에는 어떤 경우가 존재하는가? 여기서 말하는 경우의 수는 조인이 수행되는 방법을 의미한다. 조인이 수행될 수 있는 경우의 수는 아래와 같은 두 가지 요소에 의해 다양하게 발생할 수 있다.
·테이블의 조인 순서-먼저 액세스되는 테이블과 뒤에 액세스되는 테이블
·조인 방식-중첩 루프 조인, 해쉬 조인, 소트 먼지 조인
첫 번째로 위의 요소 중 테이블의 조인 순서를 확인해 보자. 조인은 두 개 이상의 테이블에서 필요한 데이터를 추출하게 되므로 먼저 액세스하는 테이블과 뒤에 액세스하는 테이블이 존재하게 된다. 그렇기 때문에 세 개의 테이블에 대해 조인을 수행하게 된다면 조인 순서는 3*2*1=6의 경우의 수가 존재하게 된다.
예를 들어, TAB1 테이블이 먼저 액세스되고 뒤에 TAB2 테이블이 액세스되며 마지막에 TAB3 테이블이 액세스되는 조인 순서도 이 경우의 수에 포함이 될 것이다. 결국, 테이블 조인 순서에 의해 발생할 수 있는 경우의 수는 6개가 된다.
두 번째로 조인 방식에 의한 경우의 수를 확인해 보자. 조인 방식은 조인을 수행하는 내부 수행 방법을 의미한다. 앞서 언급했듯이 조인은 세 가지 방식이 존재하게 된다. 따라서, 조인 방식은 세 가지의 경우의 수가 존재할 것이다.
이와 같다면 해당 조인 SQL에서 최종적으로 발생하는 경우의 수는 어떻게 되겠는가? 두 가지 경우의 수의 곱이 전체 경우의 수가 될 것이다. 그렇기 때문에 전체 경우의 수는 6*3=18가지의 경우의 수가 존재하게 된다.
예를 들어, TAB1 테이블, TAB2 테이블 및 TAB3 테이블 순으로 조인이 수행되며 TAB1 테이블과 TAB2 테이블은 해쉬 조인을 사용하고 그 결과 값과 TAB3 테이블은 중첩 루프 조인을 수행하는 경우도 18가지의 경우의 수에 포함될 것이다.
이와 같이 하나의 조인 SQL은 우리가 생각지도 않은 다양한 경우의 수가 존재하며 해당 조인 SQL이 수행될 경우에는 18가지 경우의 수 중 하나의 방법을 선택하여 조인 SQL을 수행하게 된다.
그렇다면 조인 SQL의 수행을 위한 경우의 수와 성능은 어떤 관계를 가지게 되는가? 이는 성능과 매우 밀접한 관계를 가지게 된다. 위의 예제에서 18가지의 경우의 수중 최적의 성능을 보장하는 경우는 몇 가지 안 된다. 나머지 경우의 수는 성능을 저하시키는 경우에 해당된다. 이제부터 우리는 이러한 조인의 경우의 수를 고려하여 조인 SQL을 작성해야만 성능을 보장 받을 수 있을 것이다.
조인의 성능은 다양하다
전체 데이터를 액세스하는 경우에는 하나의 테이블을 액세스하는 경우보다는 분리된 테이블의 데이터를 액세스하는 경우에 디스크 I/O가 감소했다. 디스크 I/O만 고려한다면 성능과 관련된 모든 항목은 고려된 것인가? 그것만은 아닐 것이다. 그렇다면 성능 관련해서 과연 무엇을 고려해야 하는가?
그것은 분리된 테이블에서 원하는 데이터를 추출하기 위해 사용하는 조인의 수행 방식이다. 하나의 테이블을 액세스한다면 인덱스를 이용한 테이블 액세스 방식 또는 테이블을 처음부터 마지막까지 액세스하는 테이블 전체 스캔 방식이 존재하게 된다. 이와 같이 하나의 테이블을 액세스한다면 매우 단순한 액세스가 발생하게 된다.
하지만, 조인을 이용한다면 이와 같이 단순한 방식으로만 수행되는 것은 아니다. 조인을 수행하기 위한 조인 방식이 존재하며 이와 같은 조인 방식을 이용하여 조인을 수행하게 된다.그렇다면 조인 방식에는 어떠한 것이 존재하는가?
·중첩 루프 조인(NESTED LOOP JOIN)
·해쉬 조인(HASH JOIN)
·소트 머지 조인(SORT MERGE JOIN)
위와 같은 조인 방식이 존재한다는 것은 무엇을 의미하는가? 하나의 조인은 위의 방법 중 하나의 조인 방식을 이용할 수도 있으며 경우에 따라서는 위의 조인 방식 중 하나의 조인 방식이 아닌 두 개 이상의 조인 방식을 이용할 수도 있다.
이는 무엇을 의미하는가? 경우의 수가 많다는 것은 다양한 처리 방법이 존재하는 것이며 이와 같이 모든 경우의 조인 방법이 동일한 성능을 보장할 수는 없을 것이다. 그렇기 때문에 어떻게 수행되는가에 따라 성능을 보장할 수도 있고 성능을 저하시킬 수도 있을 것이다.
결국, 하나의 테이블을 액세스하는 경우에는 SQL의 실행 계획이 매우 단순하기 때문에 거의 예외가 없지만 두 개 이상의 테이블에서 데이터를 추출하는 조인의 경우에는 위와 같이 많은 경우의 수가 존재하게 된다.
이와 같이 존재하는 많은 경우의 수에는 하나의 테이블로 구성하여 데이터를 액세스하는 경우보다 성능이 저하되는 경우도 존재하며 또는 하나의 테이블로 구성하여 데이터를 액세스하는 경우보다 성능이 더 좋아지는 경우도 존재하게 된다. 일반적으로 많은 경우의 수는 하나의 테이블로 구성하여 데이터를 액세스하는 경우보다 성능이 저하된다.
문제는 여기에 존재하게 된다. 조인을 수행하는 많은 경우의 수가 단일 테이블을 액세스하는 경우보다 성능이 저하될 수 있으며 이와 같은 경우 중 하나의 수행 방식이 선택된다면 우리는 조인이 항상 성능을 저하시킨다는 고정관념에 빠지게 된다. 그렇게 된다면 이와 같은 성능 저하를 경험한 사람은 다시는 조인을 사용하지 않고 단일 테이블로 구성하여 조인을 사용하지 않으려 할 것이다.
이와 같다면 데이터는 자연스럽게 증가하게 된다. 과연, 이것이 올바른 방법인가? 조인을 사용하는 경우에 다양한 수행 방식 중 가장 최적의 조인 방식을 선택한다면 어떻게 되겠는가? 이와 같다면 단일 테이블을 액세스하는 경우보다 조인을 이용하는 경우가 더 좋은 성능을 보장할 수 있을 것이다. 여기서 우리는 결론을 내릴 수 있을 것이다.
테이블을 분리함으로써 우리는 조인을 사용해야 하며 조인을 수행하기 위한 방식에는 다양한 경우의 수가 존재하게 된다. 다양한 경우의 수 중 우리는 최적의 조인 방식을 찾아야만 한다는 것이다. 이 것이 조인을 효과적으로 사용하면서 데이터를 감소시킬 수 있는 유일한 방법이 될 것이다.
조인은 다양하게 표현된다
앞에서 언급한 SQL의 경우는 누가 보더라도 조인이라는 것을 이해할 것이다. 과연, 분리된 테이블에서 원하는 데이터를 추출하는 방법에는 위와 같이 FROM 절에 필요한 테이블을 나열하는 방법밖에는 존재하지 않는 것일까? 이와 같은 방법 외에도 여러 가지 방법으로 분리된 테이블의 데이터를 연결할 수 있다.
·스칼라 서브쿼리-SELECT 절에 SELECT 절을 사용하는 데이터 연결
·서브쿼리-WHERE 절에 SELECT 절을 사용하는 데이터 연결
위와 같은 종류가 중요한 것은 아니다. 이와 같은 종류도 모두 조인에 해당하기 때문에 두 개 이상의 테이블에서 필요한 데이터를 추출하게 되며 그렇기 때문에 먼저 액세스되는 테이블과 뒤에 액세스되는 테이블이 존재하게 된다.
물론, 조인 방식도 앞서 언급한 세 가지 방식 중 하나를 이용하게 된다. 이와 같기 때문에 데이터 연결을 수행하는 대부분의 방식은 다양한 경우의 수가 존재하며 이 중 성능을 보장하는 경우는 몇 가지 존재하지 않게 된다.
결국, 테이블 분리에 의한 데이터의 연결을 수행하는 방식은 다양한 형태로 존재한다. 하지만, 대부분의 데이터 연결 방식이 다양하게 수행된다. 여기서 중요한 것은 다양한 경우의 수에서 성능을 보장하는 경우의 수는 많지 않다는 것이다. 그렇기 때문에 우리의 역할은 다양한 경우의 수에서 최적의 경우의 수를 찾아야 한다는 것이다. 이와 같이 최적의 경우의 수를 찾지 못한다면 우리는 평생 조인을 사용하지 말고 단일 테이블로 구성하여 단순 액세스를 수행해야 한다고 주장하게 될 것이다.
하지만, 최적의 성능을 보장하는 경우의 수를 찾아냈다면 드디어 조인의 혜택을 제대로 누릴 수 있게 되는 것이다. 조인은 절대 성능 저하의 아키텍처를 가지고 있지 않다. 단지, 우리가 모르고 사용하기 때문에 성능 저하를 발생시킨다고 생각하게 되는 것은 아닌가 생각한다.
지난 몇 년 동안 XML은 데이터 전송을 위한 새로운 표준으로 각광 받아 왔으며, 기업의 XML 기반 솔루션 도입 사례가 증가하면서 그 영향력 또한 증가하고 있습니다. 전체 데이터 전송 작업에 XML 표준을 적용하는 기업의 사례가 늘고 있으며, 이로 인해 사용되는 XML 포맷 또한 복잡해지고 있습니다. 이 과정에서 XML 포맷 내에 여러 개의 네임스페이스, 수천 개의 엘리먼트, 재귀적 정의 등이 사용되기도 합니다. 이러한 포맷을 통해 생성된 XML 문서의 규모와 복잡성 역시 증가하고 있으며, 따라서 컨텐트의 관리가 한층 까다로운 과제로 부각되고 있습니다. 하지만 이러한 문제를 해결하는데 도움이 될만한 정보는 부족한 것이 현실입니다.
본 문서에서는 Oracle Database 11g에 포함된 XML DB 기능을 이용하여 복잡한 XML 컨텐트를 관리하는 방법, 그리고 Oracle XML DB가 다른 상용 ETL 제품과 비교했을 때 제공하는 이점에 대해 설명하고 있습니다. 본 문서에서 설명되는 XML 스키마 예제는 아래와 같은 내용을 포함하고 있습니다:
• 복잡한 XML 스키마의 등록 • 데이터베이스에 XML 파일을 삽입 • 관계형 쿼리를 통해 XML 데이터를 조회 • XML 스키마 수정을 위한 In-Place Evolution 활용
그 밖에도, Oracle XML DB 솔루션의 성능과 처리 속도를 극대화하기 위한 전략과 복잡한 XML 포맷의 실제 활용 방안 등에 대한 설명이 제공됩니다.
Oracle XML DB 배경 정보
Oracle XML DB는 XML 컨텐트의 저장, 처리, 인출을 위한 강력한 툴로 Oracle Database에 기본 포함된 형태로 제공됩니다. Oracle XML DB는 다양한 XML 포맷에 수반되는 개별적인 요구 사항에 대응하기 위해 비구조형(structured), 바이너리(binary), 구조형(structured) 등의 여러 가지 저장 옵션을 제공합니다.
• 비구조형 저장 방식(CLOB, character large object). 전체 문서를 하나의 오브젝트로 취급하여 데이터베이스에 저장하는 방식으로, 데이터의 INSERT 작업 시 성능이 가장 뛰어나다는 이점을 제공합니다. 하지만 다른 방식에 비해 저장 효율성이 떨어질 뿐 아니라 관계형 쿼리에 의한 조회 시 가장 낮은 성능을 보인다는 단점이 있습니다. 관계형 접근이 요구되는 환경에서는 크고 복잡한 XML 문서를 비구조형 옵션으로 저장하는 것은 결코 바람직한 대안이 될 수 없습니다. 비구조형 저장 방식은 디스크 공간에 여유가 많고 문서를 원본 포맷 그대로 저장하고자 하는 경우에 주로 사용됩니다.
• 바이너리 저장 방식. Oracle Database 11g에 새로 추가된 옵션으로, XML 데이터를 위한 파싱 과정을 완료한 바이너리 포맷으로 데이터를 저장합니다. 이 옵션은 XML 스키마와 기본 호환하며 비구조형 저장 방식에 비해 디스크 공간 효율성과 쿼리 성능이 뛰어나다는 장점을 제공합니다. 바이너리 저장 방식은 비구조형 옵션과 비교가 어려울 정도로 개선된 성능을 제공하지만 구조형 저장 방식의 성능에는 미치지 못합니다. 바이너리 저장 방식은 관계형 접근의 성능을 일정 수준 보장할 수 있다고 판단되는 경우 효과적인 대안이 됩니다. 바이너리 저장 옵션은 그 활용이 매우 편리하므로 구조형 저장 옵션을 고려하기 전에 먼저 대안으로 생각해 볼 필요가 있습니다.
• 구조형 저장 방식. 스키마 기반(schema-based) 저장 방식이라고도 불리는 이 옵션은 오브젝트-관계형 모델을 사용하여 데이터베이스에 XML 문서를 저장합니다. 구조형 저장 방식은 디스크 공간 효율성, 관계형 쿼리 성능의 측면에서 가장 뛰어나다는 이점을 갖습니다. 또 한편으로 파일의 INSERT 작업에서 높은 오버헤드를 수반하며 스키마 등록 과정에서 추가적인 준비 과정이 필요하다는 문제가 있습니다. 구조형 저장 방식은 최적화된 관계형 쿼리 성능을 구현하고자 하는 경우에 최적의 대안이 됩니다. 특히 매우 크고 복잡한 파일을 관계형 쿼리를 통해 효율적으로 처리하고자 하는 경우에 적합합니다.
XML 문서의 크기와 복잡성에 대한 인식은 기업 환경에 따라 크게 달라집니다. OLTP 데이터베이스에서 XML을 이용하여 EDI(electronic data interchange) 환경을 구현한 경우라면 파일의 라인 수가 수천 개 정도만 되어도 그 크기가 아주 큰 것으로 간주됩니다. 반면, 기가바이트 단위의 XML 문서를 주기적으로 처리하는 수 테라바이트급의 데이터 웨어하우스 환경에서는 라인 수가 수백만 개 정도는 되어야 큰 파일이라 할 수 있을 것입니다. XML 문서의 복잡성을 판단할 때에도 같은 개념이 적용됩니다.
본 문서에서는 문서가 다음과 같은 속성을 가질 때 "복잡한" 것으로 간주하고 있습니다.
• 싱글 루트(single-rooted) 파일에 여러 개의 네임스페이스를 가짐 • 검증 과정에서 다양한 옵션을 적용할 수 있도록 유연한 XML 정의를 허용함. • 재귀적 또는 순환적 참조를 가짐. • 정적이지 않은 XML 스키마를 포함함.
본 문서에서는 20MB 이상의 크기를 갖는 싱글-루트 XML 문서 파일을 "큰" 파일로 간주합니다. 이렇게 정의된 속성은 엔터프라이즈 솔루션이 요구하는 확장성, 관리성 등의 고려 사항에 영향을 미칩니다.
최적의 저장 방식을 선택하기 위한 황금률은 따로 존재하지 않습니다. 파일 구조, 성능 목표, 사용 가능한 리소스, 예상 데이터 량 등에 따라 최적의 대안이 달라질 수 있습니다. 어떤 저장 방식이 가장 좋을 것인지 판단하기 어렵다면 여러 가지 포맷을 적용해 가면서 최적의 대안을 확인하는 방법이 바람직합니다. 일반적으로 문서의 크기가 크고 관계형 쿼리가 실행되는 환경에서는 성능, 리소스의 측면에서 비구조형 저장 방식이 좋은 대안이 되기 어렵습니다. 바이너리 XML은 비즈니스 관점에서 쿼리 성능을 일정 수준 보장할 수 있다고 판단되는 경우, 또는 유지 보수에 수반되는 시간을 최대한 단축하고자 하는 경우에 적합합니다. 반면 관계형 쿼리의 성능이 가장 주된 관심사이고 XML 문서에 신속하게 접근해야 하는 경우라면 구조형 저장 방식이 최상의 대안이 될 가능성이 높습니다.
구조형 스토리지를 이용한 처리 속도의 극대화
구조형 저장 방식은 파일 INSERT 작업에 많은 오버헤드를 수반합니다. 하지만 큰 문서를 여러 개의 파일로 분할함으로써 오버헤드를 절감하는 것이 가능합니다. 예를 들어 700MB의 싱글-루트 XML 파일을, 올바른 XML 스키마를 갖는 10개의 작은 파일로 분할할 수 있습니다. 70MB 파일 10개를 처리하는 것이 700MB 파일 1개를 처리하는 것보다 성능 면에서 유리합니다. 작업의 동시성 레벨은 데이터베이스의 프로세싱 파워에 의해 결정됩니다. 이러한 방법으로 데이터베이스 동시성을 개선하고 처리 속도를 극대화할 수 있습니다.
Oracle XML DB를 사용할 때 고려해야 할 또 한 가지 사항으로, 하나의 XML 파일을 처리하는 속도는 개별 CPU 속도에 의해 제약된다는 점을 들 수 있습니다. 다시 말해, 프로세서를 여러 개 장착한다 해도 단일 문서의 처리 속도를 개선하는 데에는 도움이 되지 않습니다. 구조형 저장 방식으로 복잡한 싱글-루트 700MB 문서를 처리하는 경우를 생각해 봅시다. 1.35GHz 프로세서를 이용하여 이 문서를 처리하는 시간은 약 10분 정도 걸립니다. 데이터베이스의 CPU 수가 12개이든 72개이든 이 수치는 달라지지 않습니다. 단일 XML 문서의 처리 속도를 개선하려면 더 높은 성능의 CPU를 사용해야 합니다. 예를 들어 3.4GHz 프로세서를 사용한다면 처리 속도가 4분으로 단축될 수 있을 것입니다. 이에 반해, 여러 개의 XML 파일을 처리해야 하는 경우에는 여러 개의 프로세서를 사용하여 INSERT 작업의 동시성을 개선하고 처리 속도를 크게 향상시킬 수 있습니다. 예를 들어 700MB 파일이 10개의 70MB 문서로 분할되어 있다면, 1.35GHz 프로세서를 장착한 데이터베이스에서 1분 이내로 처리 시간을 단축할 수 있습니다. CPU의 수가 충분하다면 10개의 문서를 데이터베이스 내에서 동시에 처리할 수도 있을 것입니다.
하지만 그 결과를 정확하게 예측하는 것은 불가능합니다. 데이터베이스의 성능은 운영 체제, 프로세싱 파워, 메모리, 스키마 정의 등 여러 가지 요인에 따라 달라질 수 있기 때문입니다. 주어진 환경의 성능을 최적화하기 위한 최선의 방안은 여러 가지 전략을 구현해 보면서 그 장단점을 직접 비교해 보는 것입니다.
Oracle XML DB와 상용 패키지 제품의 비교
파일의 데이터를 데이터베이스로 가져 오기 위한 ETL(extract, transform, load) 툴이 다양하게 출시되어 있습니다. 이러한 툴들은 일반적으로 드래그-앤-드롭 기능을 이용한 단순화된 프론트엔드 인터페이스를 통해 내부 프로세스의 복잡성을 숨길 수 있도록 구현됩니다. ETL 툴에서 XML 로드 작업을 생성하는 과정에서는 추출 대상 필드를 정의하는 작업이 필요합니다. XPath가 올바르게 정의되지 않은 경우 문서로부터 데이터가 제대로 수집되지 않을 것입니다. 복잡한 XML 문서 환경에서, Oracle XML DB는 문서에 대한 데이터베이스 중심형 뷰를 제공하고 각 문서를 오브젝트-관계형 모델로 전환하여 보여 준다는 이점을 제공합니다. 파일이 데이터베이스 내에 성공적으로 로드되면, 별도의 파싱 과정을 거치지 않고도 데이터에 즉각적으로 접근할 수 있습니다.
Oracle XML DB의 또 다른 장점으로, 이 기능이 Oracle Database에 기본 포함되어 있으며 별도의 라이센싱을 요구하지 않는다는 점을 들 수 있습니다. 하지만 라이센싱 비용을 추가로 부담하는 것이 문제가 되지 않는 경우라면 상용 ETL 패키지 대신 굳이 Oracle XML DB를 사용할 필요가 있을까요? 이 질문에 답변하기 위해서는, 먼저 Oracle XML DB가 매우 복잡한 형태의 XML 문서에 수반되는 요구 사항을 어떻게 해결하고 있는지 이해할 필요가 있습니다.
복잡한 XML 컨텐트의 처리 문제
XML 컨텐트가 유연하고, 지속적으로 변화하고, 재귀적으로 정의된 매우 큰 문서로 구성되어 있는 경우 개발자는 여러 가지 문제에 부딪힐 수 밖에 없습니다. 복잡한 XML 문서에서는 XML 스키마가 매우 크고 높은 수준의 유연성이 요구되는 경우가 많습니다. 따라서 업계 표준을 준수하는 동시에 기업 내부의 요구 사항을 반영하기 위해서는 유연한 XML 스키마가 반드시 필요합니다.
세 곳의 기업에서 동일한 XML 스키마를 표준으로 채택한 경우를 생각해 봅시다. 이 XML 스키마는 공유/표준 엘리먼트 이외에도 각 기업이 내부적으로 정의한 엘리먼트가 함께 포함되어 있어야 합니다. 이러한 요구 사항을 지원하기 위해서는 다양한 형태의 엘리먼트를 참조하는 제너릭 컨테이너 엘리먼트를 이용하여 유연성을 극대화해야 합니다. 그 결과로, 전혀 다른 엘리먼트를 갖는 문서들이 동일한 XML 스키마 내에서 사용될 수 있어야 합니다. 개발자의 관점에서 볼 때, 이러한 유연성은 XML 파서(parser)의 개발을 어렵게 합니다. 어떤 엘리먼트가 사용될지 예측하기가 어렵기 때문입니다. COTS ETL 툴과 커스텀 파서에는 데이터 추출을 위한 구체적인 XPath가 명시되어야 하며, 따라서 문서 내의 모든 데이터를 캡처하기 위해서는 가능한 모든 XPath가 확인되어야 합니다. 사용 가능한 XPath의 종류가 엄청나게 많음을 감안할 때 이는 매우 비현실적인 솔루션이 될 수 밖에 없습니다. 그 뿐 아니라 스키마에 재귀적/순환적 참조가 존재한다면 그 수는 무한대로 증가할 것입니다. 캡처되지 않은 데이터가 감지되는 경우 이를 해결하기 위한 유일한 방안은 전체 파일을 다시 파싱하는 것입니다.
아래와 같은 XML 스키마를 고려해 봅시다(스키마에는 순환적 참조가 사용되고 있으며, 제너릭 엘리먼트를 이용하여 유연성을 보장하고 있습니다):
이 XML 스키마는 세일즈/인벤토리 데이터의 전송을 위한 업계 표준으로 사용될 수 있습니다. standardData.xsd 네임스페이스에서 childContainer 엘리먼트와 companySpecificContainer 엘리먼트가 셀프-참조(self-referencing) 옵션을 제공하고 있음을 주목하시기 바랍니다. 이러한 설계를 통해 개별 기업들이 부모/자식 관계를 이용하여 데이터의 세분화 수준을 결정하도록 할 수 있습니다. 또 각각의 기업은 인벤토리, 세일즈 데이터 중 하나 또는 두 가지 모두를 포함시킬 수 있습니다. 또 각 기업의 요구 사항에 따라 상점, 제품, 세일즈 정보를 0개에서 무한대까지 포함시킬 수 있는 유연성이 제공됩니다.
ABC라는 회사가 여러 상점의 인벤토리/세일즈 데이터를 포함시키고자 하는 경우를 가정해 봅시다. 이를 위해 CompanySpecificContainer 엘리먼트들을 사용하여 각 상점(부모)을 정의하고, CompanySpecificContainer 엘리먼트들을 사용하여 각 상점의 제품(자식)을 정의할 수 있습니다. ABC 회사가 사용할 수 있는 문서의 예가 아래와 같습니다:
이에 반해 XYZ라는 기업은 단 하나의 상점만을 갖고 있으며, 파일 내에 표준적인 세일즈 데이터만을 포함시키고자 합니다. 이 경우 childContainer 엘리먼트를 제외하고 salesInformation 엘리먼트들만을 포함시킬 수 있습니다. 표준 세일즈 데이터만을 기술하는 XYZ 회사의 문서 예가 아래와 같습니다:
두 가지 문서는 서로 매우 다르지만 동일한 XML 스키마를 공유합니다. 이처럼 하나의 유연한 XML 포맷을 이용하여 다양한 기업의 요구 사항을 반영하는 업계 표준을 구현하는 것이 가능합니다. 또 제너릭 컨테이너 엘리먼트를 위한 재귀적 참조를 활용하여 각 기업이 얼마나 세분화된 정보를 포함시킬 것인지 결정하도록 지원할 수 있습니다. 예를 들어 CompanyABC.xml로부터 현재 재고량에 대한 데이터를 추출하기 위한 XPath가 아래와 같습니다.
이러한 XML 스키마 설계는 각 기업의 요구 사항에 따라 컨텐트를 자유롭게 배치할 수 있는 여지를 제공합니다. 제너릭 컨테이너 엘리먼트와 참조 옵션을 이용하여 각 문서가 별도의 데이터베이스처럼 기능하도록 구성할 수 있습니다. 이러한 파일의 예측 불허적인 성격을 감안할 때, 커스텀 코드 또는 상용 ETL 패키지를 이용하여 이 XML 데이터를 관리하기 위해서는 매우 번거로운 개발 작업이 필요할 것이며 유지보수에도 많은 비용이 필요할 것입니다. 이 XML 스키마를 사용 중인 회사가 새로운 XPath를 포함시키는 경우, 추출 작업을 위한 코드에도 데이터 캡처를 위한 내용이 추가되어야 합니다. 또 업데이트된 XPath가 적용되지 않은 상태에서 파싱된 파일들은 다시 처음부터 파싱 처리 되어야 합니다. 이처럼 복잡한 XML 스키마의 컨텐트를 관리하기 위해서는 여러 가지 까다로운 문제를 고려해야 합니다.
Oracle XML DB 솔루션
Oracle XML DB는 모든 파일을 데이터베이스 내에 저장하므로 위에서 설명한 XPath 매핑 문제로 고민할 필요가 없습니다. Oracle XML DB 환경에서는 문서가 INSERT 처리되는 즉시 문서의 컨텐트를 바로 조회할 수 있습니다. XML 스키마의 유연성 수준에 관계 없이, 문서에 포함된 데이터는 적절한 XPath를 통해 접근될 수 있습니다. 따라서 데이터의 가용성을 극대화하는 한편 유지 보수 비용을 최소화하는 것이 가능합니다.
XML DB 솔루션을 구현하기 위해서는 먼저 XML 스키마를 등록하는 과정이 필요합니다. (정의 파일과 문서는 XML_TEST 디렉토리에 위치합니다):
XML 스키마를 위한 오브젝트-관계형 구조를 생성한 다음에는, (root 엘리먼트의 주석에 명시된) 디폴트 테이블에 XML 파일을 INSERT 처리합니다.
insert into XML_DEFAULT values (XMLTYPE(BFILENAME ('XML_TEST','CompanyABC.xml'),nls_charset_id('AL32UTF8'))); /
파일의 INSERT 작업은 수 분의 일 초 내에 신속하게 완료됩니다. 그리고 바로 관계형 쿼리를 통해 데이터에 접근할 수 있습니다. 현재 인벤토리 현황을 조회하기 위한 쿼리의 예가 아래와 같습니다:
크게보기
이렇게 구현된 환경에서는 XML 스키마 정의를 준수하는 어떤 문서든 관리가 가능합니다. Oracle XML DB의 데이터 중심형 XML 뷰를 이용하여 다양한 컨텐트의 XML 문서를 작성하고 추상화 계층의 구현을 통해 (다른 ETL 툴에서는 불가피하게 수반되는) 개발 과정의 복잡성을 제거할 수 있습니다.
위의 예는 Oracle XML DB의 강력한 XML 저장/인출 기능을 보여 주고 있습니다. 하지만 복잡한 XML 스키마의 경우 변경 작업 또한 매우 빈번하게 발생할 수 있다는 점을 고려할 필요가 있습니다. Oracle XML DB는 변경 사항을 XML 스키마에 어떤 방식으로 적용할까요?
XML 스키마 변경 내역의 관리
앞의 예를 통해 제너릭 컨테이너 엘리먼트와 참조 옵션을 이용하여 스키마의 유연성을 구현하는 방법에 대해 설명하였습니다. 이러한 설계가 XML 스키마의 유연성을 매우 높여 주는 것은 분명합니다. 하지만 각 기업의 요구 사항이 변경될 때마다 CompanySpecific.1.0.xsd 네임스페이스를 수정해야 할 필요성을 함께 고려할 필요가 있습니다.
스키마 정의에 발생하는 변경 사항을 관리하는 것은 XML 기반 솔루션에서 오래 전부터 문제가 되어 왔습니다. XML 스키마가 XML 문서의 검증을 위해 사용된다는 점을 감안하면 이는 당연한 것입니다. 스키마에 정의되지 않은 엘리먼트가 문서에 포함된 경우, 이 문서는 올바르지 않은 포맷을 가진 것으로 간주됩니다. 과거에는 Oracle XML DB에 이에 관련한 약점이 존재했습니다. 등록된 XML 스키마를 변경하기 위해서는 copyEvolve 프로시저를 사용하여 매우 복잡한 작업을 수행해야 했기 때문입니다. copyEvolove 프로시저는 리소스에 락을 걸고, 임시 테이블을 생성하고, 스키마 내의 모든 XML 테이블 데이터를 임시 테이블로 이동하고, 스키마 변경을 적용한 뒤, 다시 데이터를 XML 테이블로 가져옵니다. XML 테이블의 데이터 용량이 증가하면 할 수록 이 작업에 걸리는 시간은 증가합니다. 테이블의 크기에 따라 다를 수 있지만, 하나의 엘리먼트 또는 속성을 스키마에 추가하는 데에도 수 시간이 걸릴 수 있습니다. 복잡한 XML 환경에서는 이러한 해법이 결코 스키마 관리를 위한 대안으로 고려될 수 없습니다.
오라클은 이러한 문제의 해결을 위해 Oracle XML DB 11g에 inPlaceEvolve라는 새로운 프로시저를 추가하였습니다. inPlaceEvolve 프로시저는 데이터 이동 작업 없이 온라인 상태에서 스키마 수정 작업을 수행할 수 있도록 지원합니다. 따라서 복잡한 XML 환경에서 빈번하게 발생하는 변경 작업을 신속하게 완료할 수 있습니다.
앞의 예에서 csProduct 정의에 새로운 엘리먼트를 추가해야 하는 경우를 생각해 봅시다:
Oracle XML DB 11g에서는 이 변경 작업을 매우 쉽고 간단하게 완료할 수 있습니다. 새로운 inPlaceEvolve 프로시저는 스키마 URL과 xdiff XML 스키마를 준수하는 XMLType 문서(XMLDiff)를 필요로 합니다. XMLDiff 문서는 XML 스키마의 변경 사항을 반영한 특수한 포맷의 문서입니다. XMLDiff 문서를 수동으로 생성하는 대신, 오라클 데이터베이스의 xmldiff 함수를 이용하여 자동으로 생성할 수 있습니다.
먼저 업데이트된 XML 스키마 정의 파일인 CompanySpecific.1.1.xsd를 이용하여 새로운 스키마 파일을 생성합니다. 그런 다음 기존 스키마를 첫 번째 매개변수로, 새로운 스키마를 두 번째 매개변수로 사용하여 오라클 데이터베이스 xmldiff 함수를 실행합니다.
XMLDiff 문서를 조회하기 위한 쿼리는 아래와 같습니다.
select xmldiff(xmltype(:oldSchemaDoc),xmltype(:newSchemaDoc)).getClobVal() from dual; /
본 예제에서는 XMLDiff 문서의 저장을 위해 CLOB 변수를 사용하고 있습니다.
var diffXMLDoc clob; begin select xmldiff(xmltype(:oldSchemaDoc),xmltype(:newSchemaDoc)).getClobVal() into :diffXMLDoc from dual; end; /
XMLDiff 문서를 생성했다면, 이제 PlaceEvolve 프로시저를 호출하여 온라인 상태에서 XML 스키마를 변경할 수 있습니다.
트레이스 파일을 조회해 보면 새로운 엘리먼트가 추가된 것을 확인할 수 있습니다:
change to ct sqltype = csProduct1046_T ------------ QMTS Executing SQL ------------ ALTER TYPE "XMLTEST"."csProduct1046_T" ADD ATTRIBUTE "class" VARCHAR2(4000 CHAR) CASCADE NOT INCLUDING TABLE DATA / --------------------------------------------
이 새로운 기능을 이용하여 XML 스키마에 대한 관리 효율성을 크게 개선할 수 있습니다. Oracle XML DB를 대규모 엔터프라이즈 환경에서 사용할 수 있는 가능성 또한 크게 높아졌다고 볼 수 있습니다.
실제 적용
Oracle XML DB 11g는 다른 어떤 대안보다도 유용하고 실질적인 포괄적 컨텐트 관리 솔루션을 제공합니다. Oracle XML DB는 각 문서에 대한 데이터베이스 중심형 뷰를 기반으로, XML 컨텐트의 저장 및 인출을 위한 혁신적이고 강력한 대안을 제공합니다. 다양한 저장 옵션을 이용하여 모든 유형의 문서들을 그 크기나 복잡성에 관계 없이 효과적으로 관리할 수 있습니다. XML 스키마 정의의 온라인 업데이트 기능은 컨텐트가 자주 변경되는 환경에서 Oracle XML DB를 이상적인 솔루션으로 활용될 수 있게 합니다.
본 문서에서 설명된 XML 문서의 처리 방법이 꽤 복잡해 보일 수도 있겠지만, 이러한 방법은 실제로 여러 업계에서 표준으로 활용되기 시작하고 있습니다. 통신 업계의 경우, 무선 업체들이 분산 전송 지표(distributing transmission metrics)를 위해 위에서 설명한 것과 유사한 XML 스키마를 이용하고 있기도 합니다. 복잡한 XML 포맷이 제공하는 가치와 유연성, 그리고 Oracle XML DB의 강력한 컨텐트 관리 기능을 감안할 때, Oracle XML DB 11g의 미래는 매우 밝다고 볼 수 있습니다.





 invalid-file
invalid-file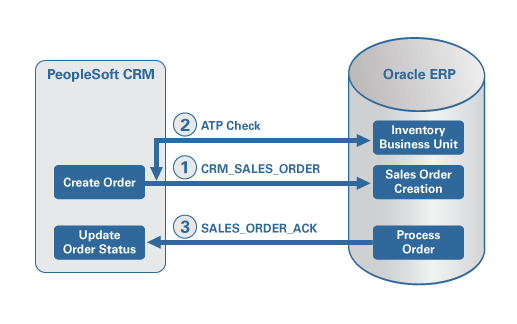
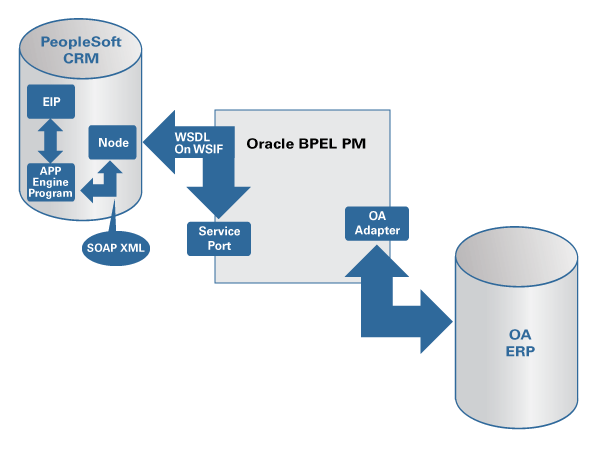
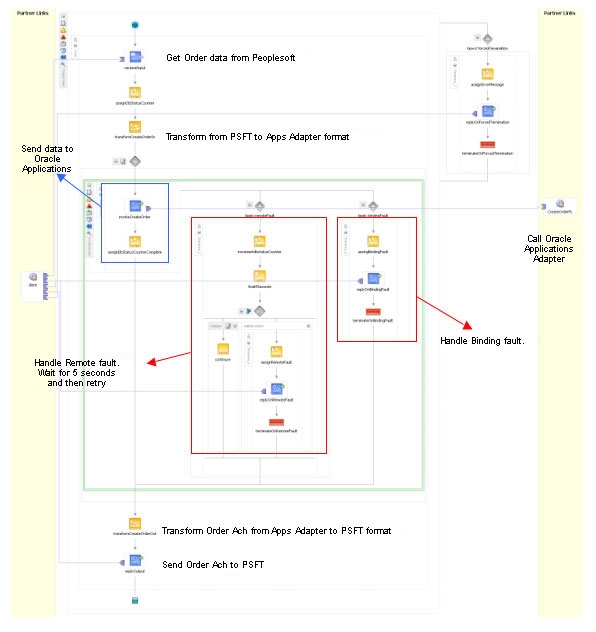
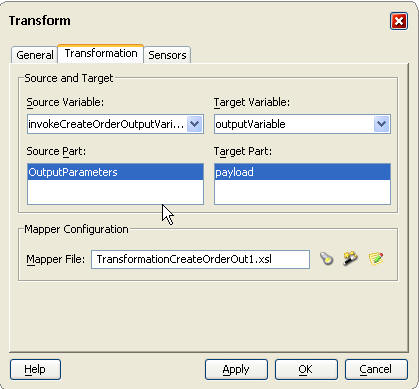
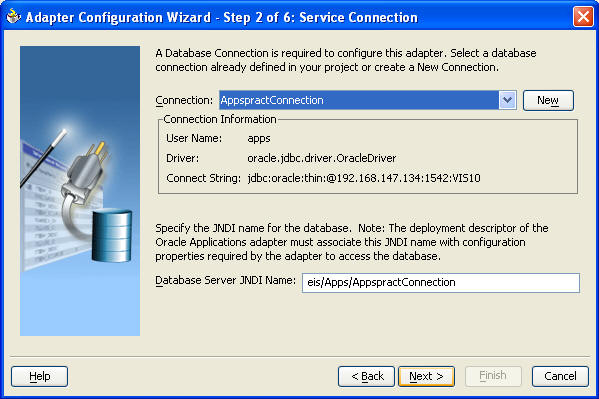
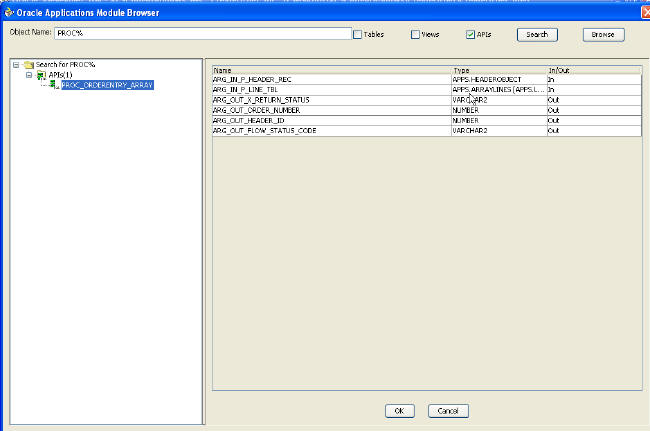
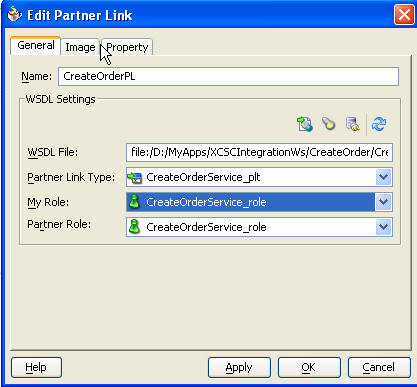
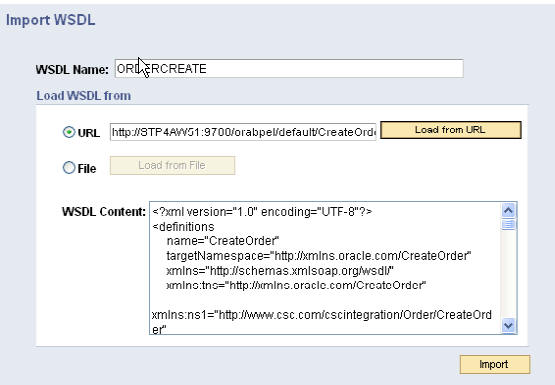
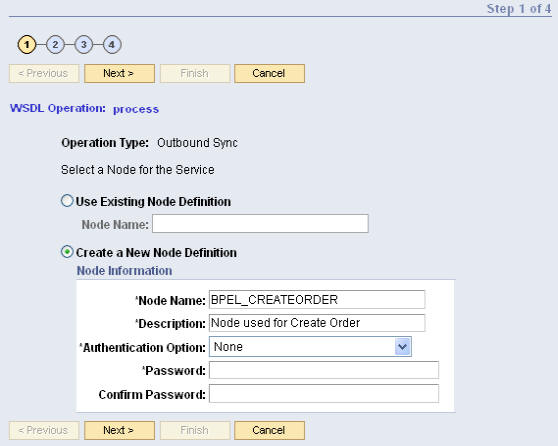
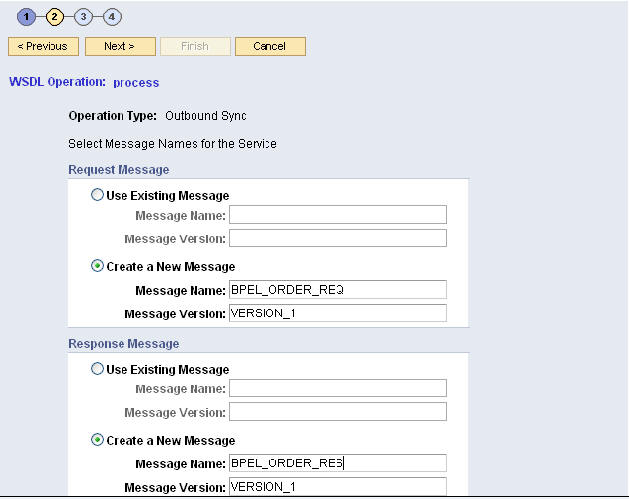
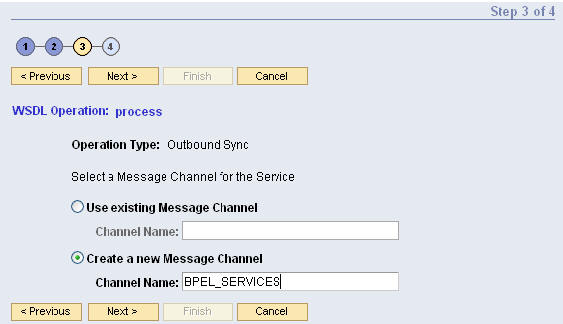
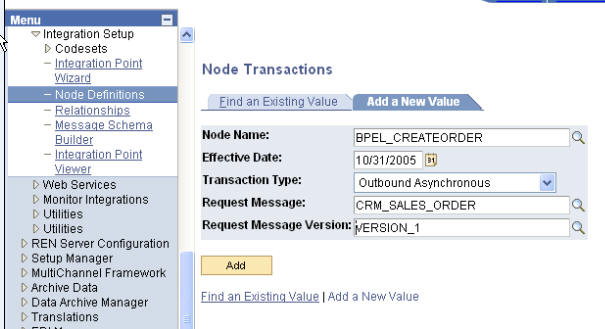
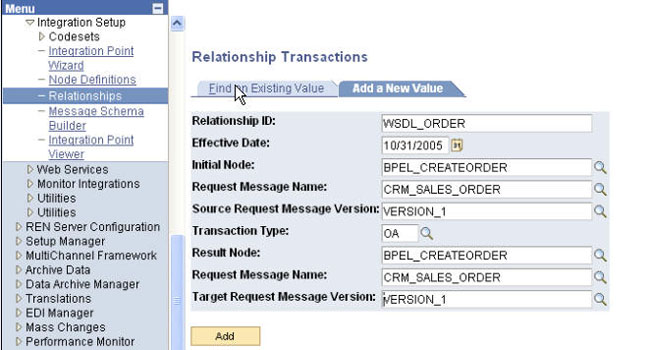
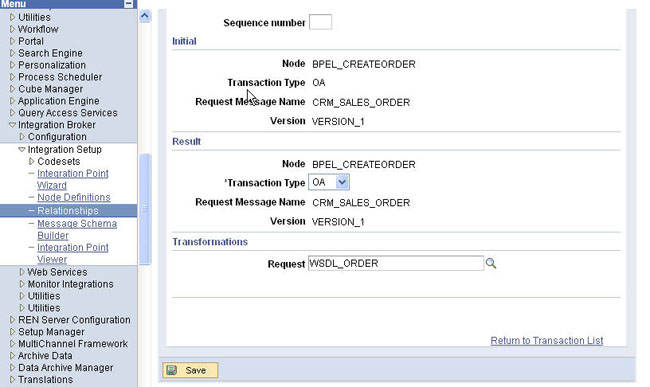
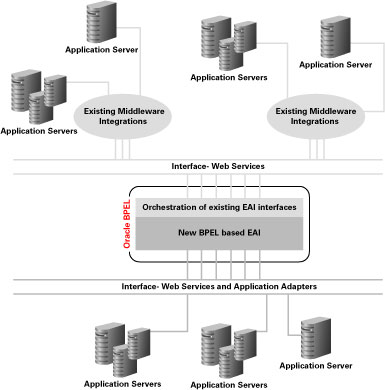
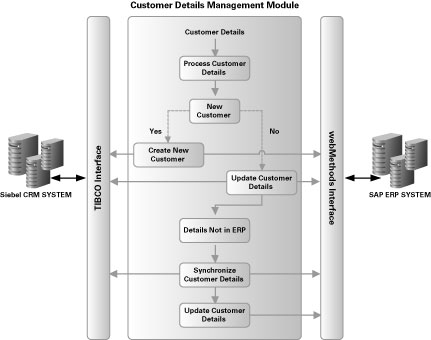
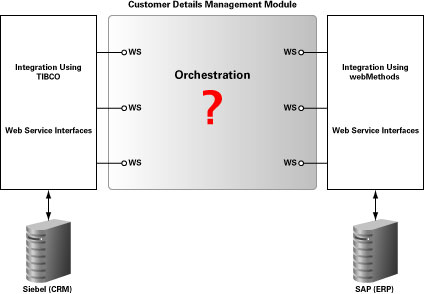
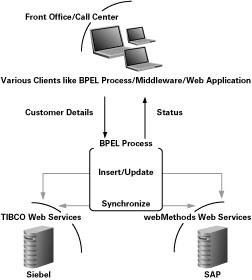
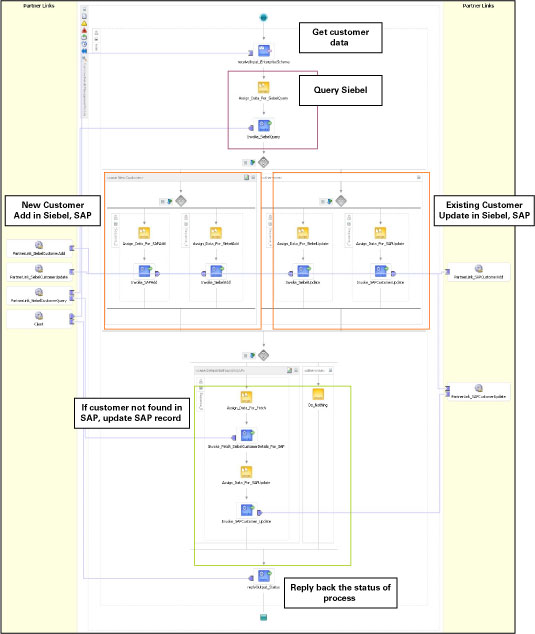
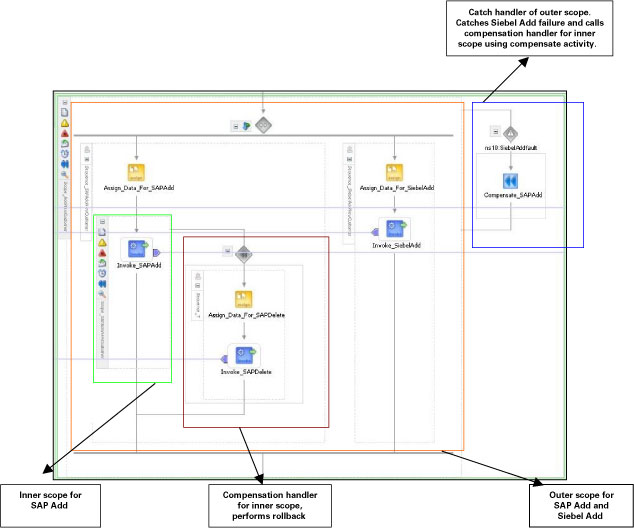
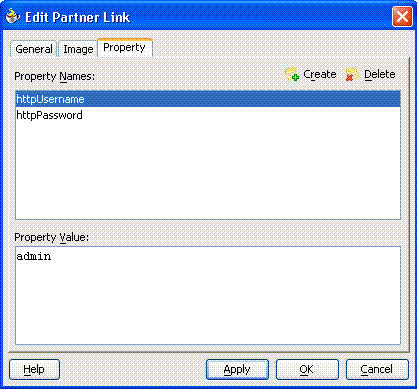
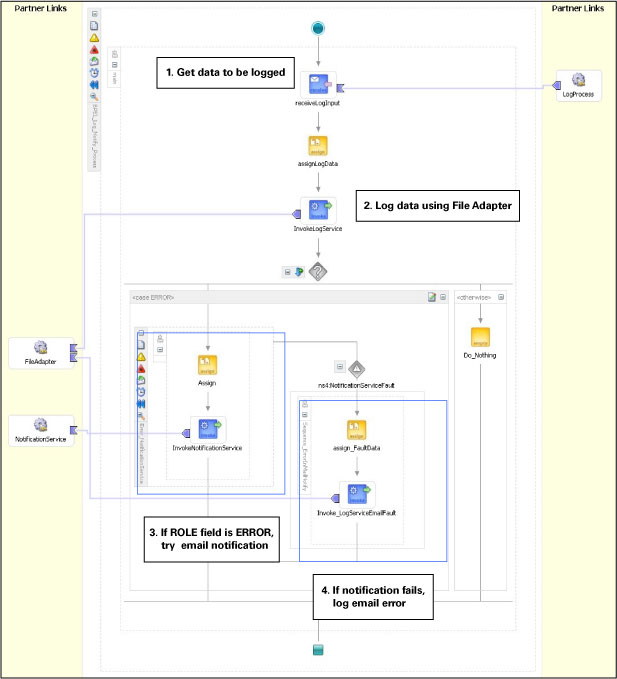
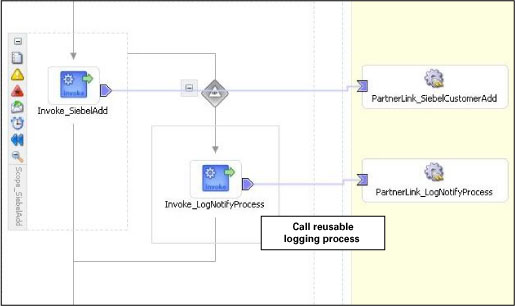
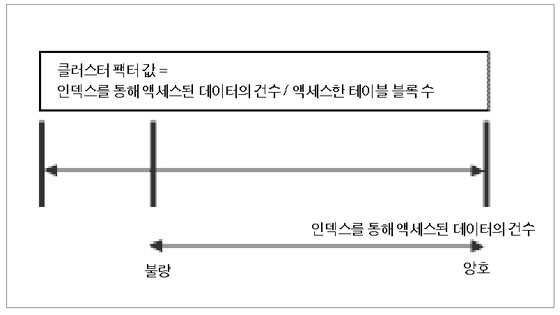
 invalid-file
invalid-file