이기종 EAI 환경에 BPEL 추가하기
저자: Praveen Chandran and Arun Poduval
Oracle BPEL Process Manager의 통합(orchestration) 기능을 이용하여 고전적인 EAI 미들웨어를 아우르는 표준 기반 비즈니스 프로세스 통합 환경을 구현하는 방법에 대해 알아봅니다.
오늘날 대부분의 기업은 다수 벤더 제품으로 구성된 다양한 애플리케이션과 플랫폼, 그리고 서로 다른 테크놀로지를 포함하는 고도로 분산된 이기종 애플리케이션 인프라스트럭처를 보유하고 있습니다. 지난 10년 동안에는 TIBCO, webMethods, Vitria, SeeBeyond 등 고전적인 EAI(enterprise application integration) 벤더들이 통합 문제를 해결하기 위한 새로운 솔루션을 출시하는 움직임이 두드러지게 나타나기도 했습니다. 또 지난 몇 년 동안, 많은 기업이 이러한 EAI 솔루션에 많은 투자를 하면서, 기업 환경이 단일 벤더 환경에 종속되고 긴밀하게 커플링된(tightly coupled) 통합 컴포넌트 구성이 일반화되기 시작하였습니다.
이처럼 벤더 종속적인 통합 환경을 유지하고 관리하는 데에는 만만치 않은 비용이 듭니다. 비용과 안정성 문제를 해결하기 위해서는 전문적인 스킬이 요구될 뿐 아니라, 기존 EAI 솔루션을 다른 대안으로 완전하게 대체하려면 막대한 비용을 EAI 영역에 쏟아 부어야 할 수도 있습니다.
BPEL이 제공하는 표준 기반, 플랫폼 중립적인 솔루션을 이용함으로써 이러한 문제를 해결하는 것이 가능합니다. 느슨하게 커플링된(loosely coupled) BPEL 프로세스는 벤더 종속 요소를 제거하고, 통합 비용을 절감하고, 호환성을 개선하는 효과를 제공합니다. 또 보안, 예외 관리, 로깅 등을 위한 계층 구현을 가능하게 합니다. 가장 중요한 사실은 기업들이 기존 인프라스트럭처를 활용하여 서비스를 구현하고 BPEL을 이용하여 전체 서비스를 통합할 수 있다는 점입니다.
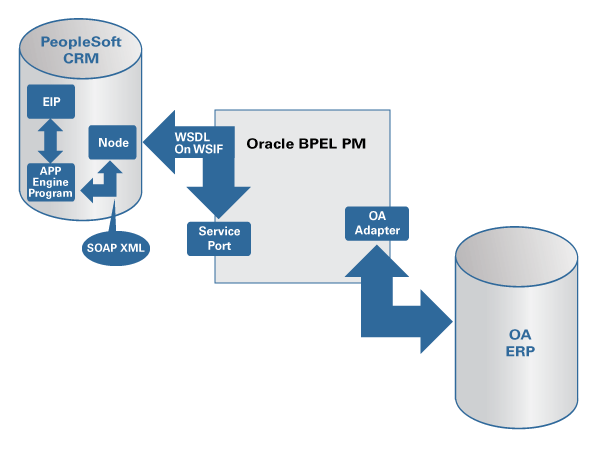
“BPEL Cookbook” 시리즈의 이번 연재에서는 Oracle BPEL Process Manager를 이용하여 새로운 통합 솔루션을 개발하고 기존 인프라스트럭처와 인터페이스 하기 위한 아키텍처의 청사진을 제시합니다. 또 TIBCO BusinessWorks와 webMethods에 기반한 이기종 EAI 솔루션을 웹 서비스와 통합하는 사례를 함께 살펴보기로 합니다.
또, 완벽한 비즈니스 프로세스의 구현을 위해서는 용의주도한 에러 관리, 보안, 로깅 프레임워크가 필수적입니다. 여기에서는 BPEL scope와 compensation handler를 이용하여 프로세스의 안정성을 높이고 BPEL 프로세스 및 서비스의 보안을 보장하는 방법에 대해 함께 알아보도록 하겠습니다.
사례 연구 배경정보
EAI는 기존 애플리케이션의 서비스화(service-enabling)을 위한 훌륭한 촉매제 역할을 합니다. 기존 미들웨어 프로세스를 웹 서비스로 공개하고, 이를 다시 BPEL을 통해 통합하는 것이 가능합니다.
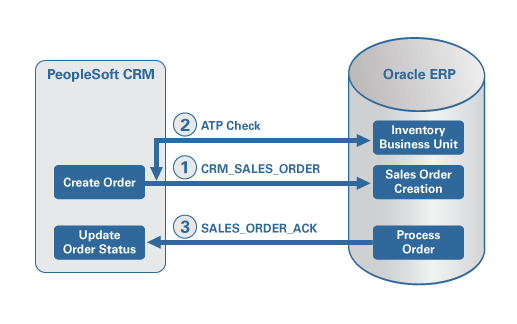
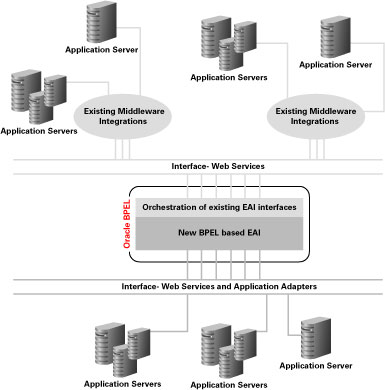
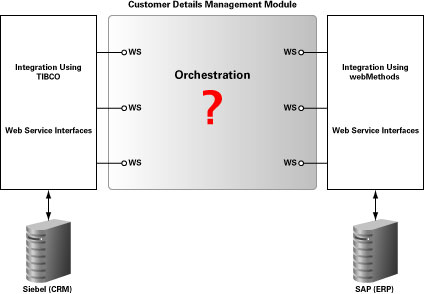
아래 다이어그램은 Oracle BPEL Process Manager를 이용하여 기존 EAI 인터페이스와 새로운 애플리케이션을 통합하는 일반적인 접근법을 보여주고 있습니다. 아래에서는 미들웨어가 비즈니스 프로세스를 웹 서비스 형태로 공개할 수 있으며, 애플리케이션 서버 내부적으로 웹 서비스 인터페이스가 구현되어 있다고 가정하고 있습니다.
그림 1 EAI 환경의 Oracle BPEL Process Manager — 전체 개념도
본 문서에서는 두 가지 고전적인 EAI 미들웨어 제품에 대한 사례 연구를 통해, BPEL이 제품간 통합 과정에서 어떤 역할을 담당하는지 알아보기로 하겠습니다.
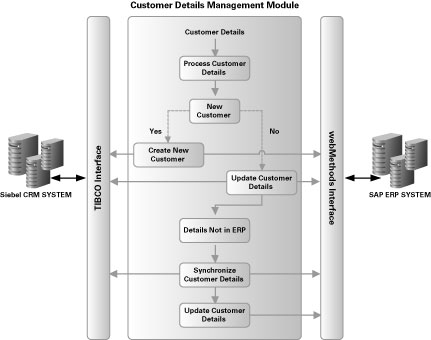
특정 고객의 “기록 시스템(system of record)”이 고객 데이터가 관리되고 있는 다른 시스템으로 원활하게 전달되지 않는 경우를 자주 찾아볼 수 있습니다. 이러저러한 이유로 기업이 두 가지 벤더의 미들웨어 제품(예: Siebel CRM과 TIBCO BusinessWorks, SAP R/3와 webMethods 등)을 동시에 사용하고 있는 경우를 고려해 봅시다. (그림 2 참고).
그림 2 Customer Details Management Module과 미들웨어 인터페이스
이러한 모델에서는, SAP 시스템과 Siebel 시스템 간의 고객 데이터 불일치로 인한 고객 서비스 수준의 저하, 또는 기업 매출의 저하가 발생할 소지가 높습니다. 따라서, TIBCO 및 webMethods와 다수의 인터페이스 포인트(interfacing point)를 갖는 공통 Customer Details Management Module을 구현함으로써 데이터 일관성을 보장하는 것이 바람직합니다. 예를 들어, Siebel 시스템에 고객 데이터가 접수된 경우, 시스템은 고객이 신규 고객인지 아니면 기존 고객인지 확인한 후 SAP 시스템에 새로운 데이터를 추가하거나 기존 데이터를 업데이트하는 작업을 수행하게 됩니다.
이러한 통합 목표의 달성을 위해 기존 미들웨어 툴(TIBCO와 webMethods)를 이용할 수도 있습니다. 하지만 이 경우 벤더 종속성이 더욱 심화될 뿐 아니라 표준 기반의 통합이 불가능하다는 문제가 있습니다. 따라서 이와 같은 환경을 애플리케이션의 서비스화(service-enabling)를 위한 새로운 기회로 활용하고, 표준 기반, 벤더 중립적인 솔루션을 구현하는 것이 바람직할 것입니다.
표준 기반의 EAI 인터페이스를 구현하기 위한 첫 단계로서, 프로세스를 웹 서비스로 공개하는 작업이 필요합니다. 대부분의 미들웨어 플랫폼은 웹 서비스를 이용한 다른 플랫폼 간의 커뮤니케이션을 지원합니다. 하지만 일련의 인터페이스 서비스를 관련된 비즈니스 로직과 연계해야 하는 경우에는 문제가 복잡해질 수 있습니다.
또 다른 미들웨어 프로세스, 또는 복잡한 Java 코드를 이용하여 웹 서비스를 통합하는 방법을 고려해 볼 수도 있습니다. 하지만 이 경우에도 아래와 같은 기능을 프로세스를 통해 직접 구현해야 한다는 문제가 남습니다:
- 병렬 웹 서비스 호출
- 비동기식 웹 서비스 호출
- 서비스 간의 느슨한 커플링(loose coupling) 및 호환성
- 표준 기반 인터페이스를 이용하여 전체 통합(orchestration) 환경을 공개
- 통합 모니터링 (orchestration monitoring)
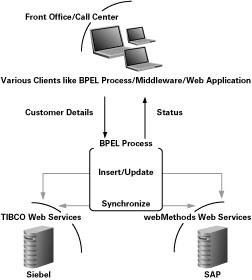
그림 3에서 확인할 수 있는 것처럼, BPEL을 기반으로 한 표준 기반 통합 솔루션을 이용하면 이러한 문제를 쉽게 해결할 수 있습니다.
그림 3 웹 서비스 인터페이스를 이용한 Customer Details Management Module
이와 같은 시나리오에 BPEL을 도입함으로써 기대할 수 있는 이점이 다음과 같습니다:
- BPEL은 느슨하게 커플링된(loosely coupled) 웹 서비스 통합을 지원합니다.
- 비즈니스 로직을 (심지어 병렬 플로우까지도!) 단순한 XML 태그를 이용해 표현할 수 있습니다.
- 간단한 assign (copy 룰),invoke 구문을 이용하여 서비스 간의 데이터 라우팅을 수행할 수 있습니다.
- 다른 통합 툴, 미들웨어 툴, 또는 웹 애플리케이션으로부터 Customer Details Management Module을 독립적인 웹 서비스 컴포넌트로 호출할 수 있습니다.
- Oracle BPEL Process Manager 등의 제품이 제공하는 단순한 GUI를 통해 프로세스를 쉽게 관리할 수 있습니다.
대부분의 미들웨어 툴은 비즈니스 프로세스를 웹 서비스의 형태로 공개함으로써, BPEL을 이용한 통합을 한층 용이하게 하는 기능을 제공합니다. 더 나아가, 사용 중인 모든 미들웨어 서비스 인터페이스가 공통 메시지 포맷을 사용하도록 설정하는 것도 가능합니다.
이제, Oracle BPEL Process Manager를 이용하여 SAP 시스템과 Siebel 시스템의 고객 데이터를 동기화하는 방법에 대해 알아보기로 합시다.
Customer Details Management Module의 구현
BPEL은 SAP 시스템과 Siebel 시스템 간의 고객 데이터 동기화 프로세스를 자동화하는 과정에서 매우 중요한 역할을 담당합니다. BPEL 프로세스를 구현하기 위한 작업 단계가 아래와 같습니다:
- TIBCO, webMethods 프로세스를 웹 서비스로 공개합니다.
- BPEL 프로세스를 이용하여 웹 서비스를 통합(orchestrate)합니다.
- BPEL 프로세스에 예외 관리(exception management) 기능을 추가합니다.
- Oracle BPEL Process Manager, 애플리케이션 어댑터, EAI 툴 간의 커뮤니케이션 보안 환경을 구현합니다.
- 로깅, 통보 프로세스를 중앙집중화 합니다.
1 단계: TIBCO, webMethods 프로세스를 웹 서비스로 공개. 고객 정보는 정규 포맷(canonical format)으로 표시되며, 포맷 내에는 SAP과 Siebel이 사용하는 필드가 모두 포함되어 있습니다. TIBCO와 webMethods는 이 포맷을 각각 Siebel, SAP 고객 레코드 포맷으로 변환하여 사용합니다.
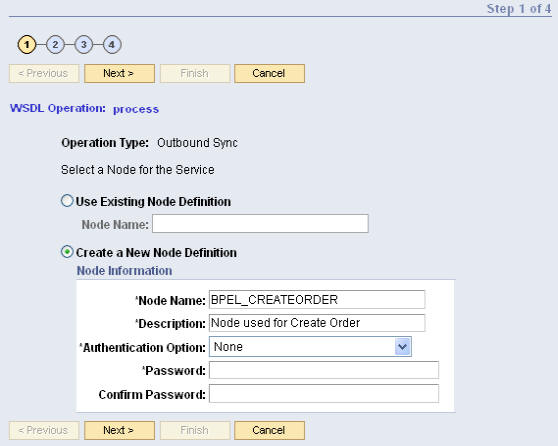
BusinessWorks 프로세스를 웹 서비스로 공개하기 위한 방법이 아래와 같습니다:
- BusinessWorks 프로세스가 제공하는 기능을 분석하고, 해당 기능이 통합 시나리오 내에서 독립적인 컴포넌트로써 구현될 수 있는지 확인합니다.
- 프로세스 입력 및 출력을 정의합니다.
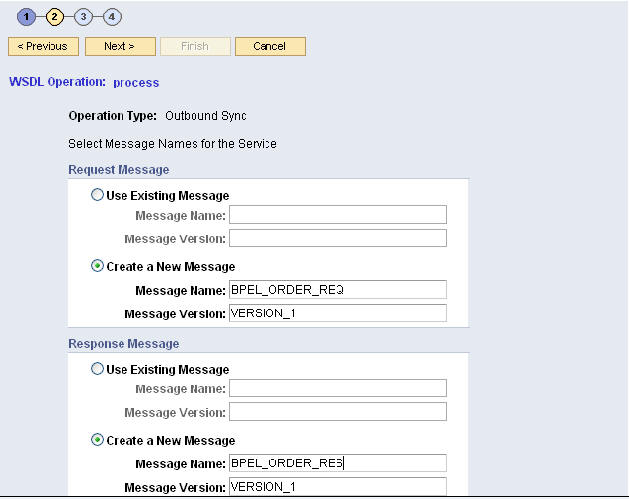
- input과 output이 복잡한 경우, W3C XML 스키마(XSD)를 이용하여 정의합니다. XSD를 이용하여 커스텀 폴트 스키마(custom fault schema)를 정의할 수도 있습니다.
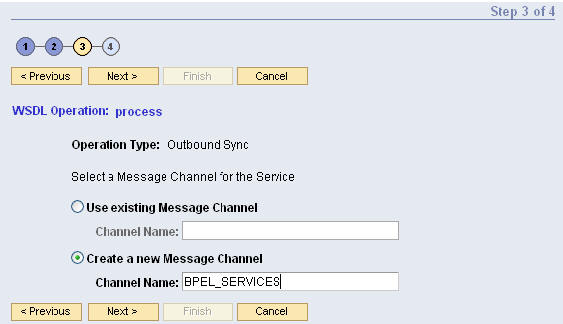
- WSDL 팔레트를 이용하여 WSDL을 생성하고input과 output 메시지 포맷을 정의합니다 (이때 필요한 경우, 메시지 포맷을 사전정의된 XSD와 연결합니다). 기존 WSDL을 임포트(import)할 수도 있습니다.
- HTTP Connection 리소스를 설정합니다.
- SOAP Event Source 를 첫 번째 액티비티로 사용하고, 비즈니스 로직, SOAP Send Reply 등의 순으로 프로세스를 서비스 형태로 공개합니다.
- HTTP Connection 리소스와 Event Source를 연결(associate)합니다.
- WSDL과 Send Reply를 Event Source와 연결합니다.
- 발생 가능한 예외(exception)을 처리하고 SOAP Send Fault를 이용하여 서비스 클라이언트에 예외를 전달합니다.
- 10. 머신 네임이 mymachine이고, HTTP Connection 리소스를 위해 8000번 포트를 사용하며, 프로세스 네임이 SOAPService인 경우, 다음 URL을 통해 서비스에 접근할 수 있습니다. http://mymachine:8000/SOAPService.
- Event Source 액티비티의 WSDL 탭에서 서비스의 WSDL을 가져옵니다.
webMethods에서 사용하는 방법이 아래와 같습니다:
- webMethods Flow Service가 통합 시나리오에서 독립적인 컴포넌트로써 구현될 수 있는지 확인합니다.
- 해당 웹 서비스를 별도의 인증 과정 없이 webMethods 외부에서 호출하고자 하는 경우 Permissions 탭의 "Execute ACL to Anonymous"를 체크합니다.
- webMethods Developer에서 해당 Flow Service를 선택하고, Tools 메뉴에서 Generate WSDL을 클릭합니다.
- WSDL 다큐먼트를 생성하는 과정에서 프로토콜(SOAP-RPC/SOAP-MSG/HTTP-GET/HTTP-POST)과 전송 메커니즘(HTTP/HTTPS)을 정의합니다.
- WSDL 다큐먼트의 타겟 네임스페이스(target namespace)를 정의합니다.
- webMethods Integration Server가 실행되는 호스트명 또는 IP 주소를 Host 필드에 입력합니다.
- 현재 Integration Server에 연결할 때 사용하는 포트 넘버를 Port 필드에 입력합니다.
- WSDL 다큐먼트를 로컬 파일 시스템에 저장합니다. 생성된 WSDL 다큐먼트에서 서비스 엔드포인트(service endpoint)를 확인할 수 있습니다.
참고: webMethods Integration Server는 특정 에러 상황이 발생한 경우 사전 정의된 SOAP 폴트(fault)를 전송합니다. 커스텀 SOAP 폴트를 전송하고자 하는 경우에는 커스텀 SOAP 프로세서를 이용해야 합니다. 또 서비스를 다큐먼트/리터럴(document/literal) 웹 서비스로 공개하고자 하는 경우에는 래퍼 서비스(wrapper service) 또는 커스텀 SOAP 프로세서를 사용해야 합니다.
이제, 아래와 같은 3 개의 TIBCO 웹 서비스가 존재한다고 가정해 봅시다 (TIBCO BusinessWorks 프로세스와 TIBCO Adapter for Siebel을 사용하여 구현).
- Siebel Add
- Siebel Update
- Siebel Query
마찬가지로, 아래와 같은 webMethods 웹 서비스가 존재합니다 (webMethods Integration Server와 webMethods SAP R/3 Adapter를 이용하여 구현).
솔루션 아키텍처는 아래와 같이 요약할 수 있습니다:
그림 4 솔루션 아키텍처
위 그림에서 확인할 수 있는 것처럼, BPEL 프로세스는 EAI 툴을 이용한 프론트 오피스 콜 센터와 백엔드 SAP 및 Siebel CRM 애플리케이션 간의 커뮤니케이션을 중개하는 역할을 담당합니다.
미들웨어 프로세스를 웹 서비스로 공개하기 위한 몇 가지 베스트 프랙티스가 아래와 같습니다:
- 가능한 한 WS-I 표준을 준수합니다.
- 서비스를 리터럴 인코딩(literal encoding)을 사용한 “document” 스타일로 공개합니다. 이것이 불가능한 경우에는, 리터럴 인코딩을 이용한 “rpc” 스타일로 공개합니다. 두 가지 스타일 모두 WS-I 표준에 의해 권장되고 있지만, document 스타일이 좀 더 사용하기 쉬운 것이 사실입니다 (특히 BPEL assign 액티비티에 대한 copy 룰을 생성하는 경우에 특히 그러합니다). rpc 스타일의 경우 모든 스키마 엘리먼트가 별도의 메시지 파트로 구성되는 반면, document 스타일에서는 전체 메시지가 하나로 전달됩니다. 따라서 전체 스키마를 하나의 copy 룰을 사용하여 복사할 수 있기 때문에, 개발 작업이 단순화되고 최종 WSDL 다큐먼트의 스타일과 인코딩을 검증하기 쉽다는 장점이 있습니다.
- SOAP 인코딩의 사용을 피합니다. WSDL의 SOAP Action 속성은 빈 문자열(empty string)으로 구성됩니다.
- 미들웨어가 웹 서비스의 인터페이스 기술을 위해 WSDL 1.1을 사용하고 있는지 확인합니다.
- SOAP의 HTTP 바인딩을 사용합니다.
- 스키마 기술에 사용되는 모든 XSD가 W3C가 제안한 XML Schema Specification을 준수하는지 확인합니다. 예를 들어, 글로벌 엘리먼트 선언에 다른 글로벌 엘리먼트에 대한 참조가 포함되어서는 안됩니다 (다시 말해, ref 속성 대신 type 속성이 사용되어야 합니다).
2 단계: 웹 서비스의 통합(orchestration). H미들웨어 프로세스를 웹 서비스로 공개했다면, 다음은 Oracle BPEL Process Manager의 강력한 GUI 기반 BPEL 인터페이스를 이용하여 서비스들을 통합할 차례입니다.
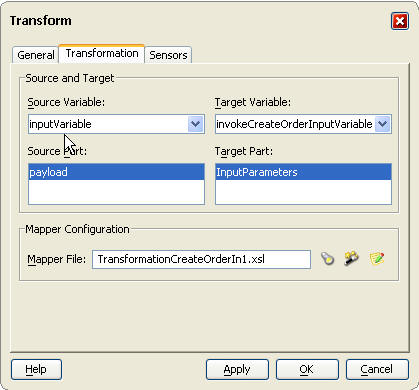
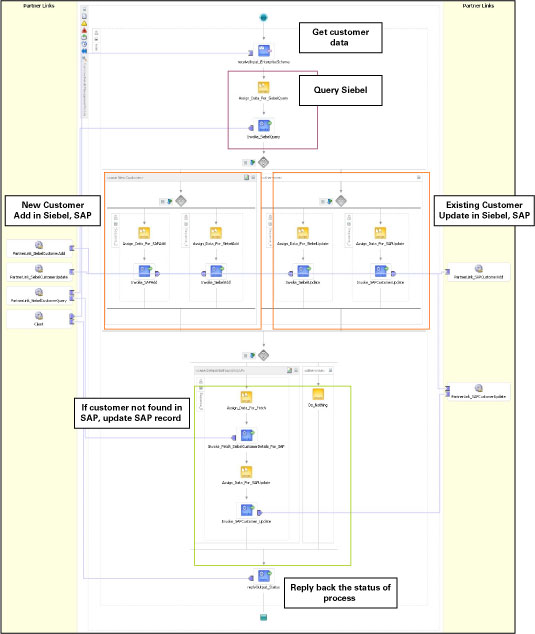
앞부분에서 Customer Details Management Module이 SAP 시스템 및 Siebel 시스템의 고객 데이터를 동기화하는 역할을 담당한다고 설명한 바 있습니다. 이 프로세스를 BPEL Designer의 비주얼 인터페이스를 이용하여 생성한 결과가 아래 그림과 같습니다.
그림 5 Oracle BPEL Process Manager를 이용한 Customer Details Management Module의 통합
프로세스 플로우는 아래와 같이 요약될 수 있습니다:
- receive 액티비티가 customer detail 정보를 접수합니다 (enterprise schema).
- Detail 정보가 assign, invoke (Siebel Query 서비스) 액티비티를 통해 Siebel에 전달됩니다.
- pick 액티비티에서 Siebel Query의 결과를 통해 고객이 신규 고객인지 기존 고객인지를 확인합니다.
- 신규 고객인 경우 병렬 플로우가 호출되고, flow 액티비티가 Siebel와 SAP에 고객 정보를 동시에 추가합니다. 또는 기존 고객인 경우, 양쪽 애플리케이션에 고객 정보를 업데이트하기 위한 병렬 플로우가 호출됩니다.
- 고객 정보가 SAP에 존재하지 않는 경우, Siebel Query 를 통해 필요한 필드를 가져옵니다. 업데이트가 필요한 SAP 필드는 일련의 assign copy 룰을 통해 SAP Update로 전달됩니다.
- reply 액티비티를 통해 Customer Update/Addition의 최종 결과가 반환됩니다.
그림에서 확인할 수 있는 것처럼, 양측의 비즈니스 프로세스에는 Siebel 및 SAP 데이터의 추가와 업데이트를 위한 웹 서비스가 각각 구현됩니다. 1 단계에서 설계되는 이 웹 서비스들은 내부적으로EAI 프로세스들을 호출합니다.
이 BPEL 프로세스는 고객 관에 관련한 비즈니스 요구사항을 해결하고 있지만, 여전히 예외 사항을 처리하고 있지 못하다는 문제가 있습니다. 예를 들어, 특정 고객의 레코드가 Siebel에서는 성공적으로 추가되었지만 SAP에서 실패한 경우에는 어떻게 해야 할까요? 이러한 문제를 해결하기 위해서는 비즈니스 프로세스에 예외 관리(exception management)가 구현되어야 합니다.
3 단계: 예외 관리(Exception Management) 기능의 추가. 예외 관리 기능을 구현함으로써 BPEL 프로세스 또는 웹 서비스 외부에서 반환되는 에러 메시지 및 기타 예외 사항을 처리하고 비즈니스 에러 또는 런타임 에러 발생시 대응되는 에러 메시지를 생성할 수 있습니다.
아래 표는 고객 관리 BPEL 프로세스를 보다 안정적으로 구현하기 위한 예외 상황을 요약하고 있습니다.
| No. |
Case |
해결 방안 |
| 1 |
Siebel Query 실패 |
프로세스 종료; 재시도 |
| 2 |
Siebel Add 실패; SAP Add 성공 |
SAP 레코드의 삭제를 통한 보정; 재시도 |
| 3 |
Siebel Add 성공; SAP Add 실패 |
정상 플로우; 재시도 |
| 4 |
Siebel Add 실패; SAP Add 실패 |
정상 플로우; 재시도 |
| 5 |
Siebel Update 성공; SAP Update 실패 |
정상 플로우; 재시도 |
| 6 |
Siebel Update 실패; SAP Update 성공 |
SAP 레코드 롤백을 통한 보정; 재시도 |
| 7 |
Siebel Update 실패; SAP Update 실패 |
정상 플로우; 재시도 |
1, 2, 6 번을 제외한 나머지 케이스는 별도의 예외 처리를 필요로 하지 않음을 확인할 수 있습니다.
Exception을 캐치하고 적절한 대응 조치를 취하기 위해서는 웹 서비스의 상태를 추적하는 것이 중요합니다. 케이스 1, 2, 6이 어떻게 처리되는지 논의 하기 전에, 특정 웹 서비스의 상태를 어떻게 추적할 수 있는지 설명해 보기로 하겠습니다.
BPEL 프로세스에는 아래와 같은 reply 스키마 속성이 포함됩니다:
- Siebel_Add_Status
- Siebel_Update_Status
- SAP_Add_Status
- SAP_Update_Status
위의 4가지 속성은
Failed ,
Success 또는
NA 의 값을 가지며, BPEL 프로세스에 의해 임의의 시점에 설정될 수 있습니다.
Failed 상태로 설정하려는 경우, 프로세스는 타겟 웹 서비스에서 발생되는 SOAP 폴트(fault)를 캐치합니다 (이때 각각의
invoke 액티비티에 대해 catch handler가 사용됩니다). Customer Details Management Module을 호출하는 클라이언트는 에러가 발생한 경우 고객 상세정보를 재전송할 수 있습니다.
이제 각 케이스 별로 예외가 어떻게 관리되는지 살펴보기로 합시다:
Case 1
Siebel 쿼리가 실패한 경우, 프로세스를 종료하고 클라이언트 호출 과정을 재시도합니다.
Case 2
고객 상세정보의 INSERT 작업이 Siebel에서는 실패하고 SAP에서는 성공한 경우 (두 가지 작업은 병렬적으로 실행됩니다), 데이터 일관성이 훼손될 수 있습니다. 또, 같은 작업을 재시도하는 경우 아래와 같은 문제가 발생할 수 있습니다:
- BPEL 프로세스를 호출하여 Siebel에 고객 상세정보를 INSERT하려 시도하는 과정에서, SAP에 중복된 정보가 입력될 수 있습니다.
- 해당 고객의 정보를 업데이트하는 BPEL 프로세스를 호출하려 시도하는 경우, Siebel에서의 업데이트가 (해당 레코드가 존재하지 않기 때문에) 실패하게 됩니다.
위의 상황을 처리하려면, 같은 작업이 재시도되기 전에 다른 webMethods 웹 서비스와 BPEL compensation handler 및 scope를 사용하여 SAP 고객 레코드를 먼저 삭제해야 합니다.
scope와 compensate 액티비티는 가장 핵심적인 BPEL 개발 툴의 하나입니다. 스코프(scope)는 다른 액티비티에 대한 container 겸 context로써 활용됩니다. 스코프 액티비티(scope activity)는 프로그래밍 언어의 {} 블록에 대응됩니다. 스코프는 BPEL 플로우를 기능적으로 유사한 구조로 그룹화하고, 에러, 이벤트, 보정(compensation) 및 데이터 변수, correlation set 등을 위한 핸들러(handler)를 제공합니다.
Oracle BPEL Process Manager는 보정 처리를 위해 두 가지 컨스트럭트를 제공합니다:
- Compensation handler—롤백 작업을 위한 비즈니스 로직을 처리합니다. 프로세스 및 스코프 별로 핸들러를 정의할 수 있습니다.
- Compensate activity—이 액티비티는 성공적으로 완료된 inner scope 액티비티를 통해 compensation handler를 호출합니다. 그리고 이 액티비티는 fault handler 또는 다른 compensation handler 내부에서만 호출이 가능합니다.
Exception은 catch handler를 통해 스코프 레벨에서 캐치됩니다. 그런 다음, catch handler는 compensate activity를 이용하여 inner scope를 위한 compensation handler를 호출합니다. 이 compensation handler는 롤백에 필요한 작업을 수행하게 됩니다.
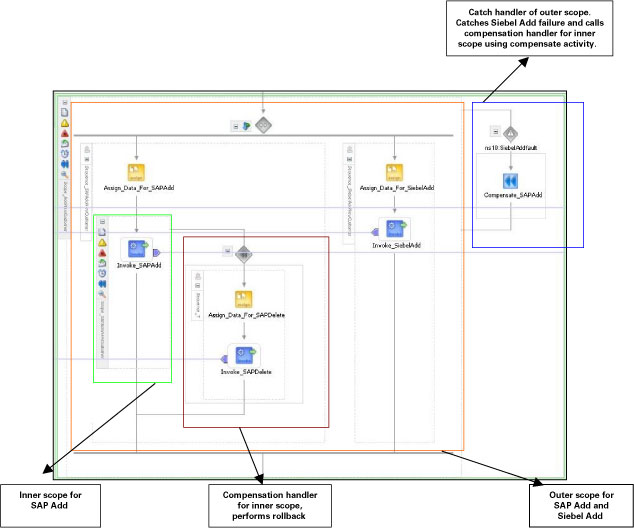
다시 예제로 돌아가, BPEL 프로세스가 내부(inner), 외부(outer)의 두 가지 스코프를 갖는다고 가정해 봅시다. SAP Add 및 Siebel Add 서비스의 호출은 outer scope를 통해 수행되며, SAP Add 서비스 만이 inner scope를 통해 수행됩니다. compensation handler는 inner scope와 연계가 가능하며, SAP Delete 서비스를 위한 액티비티를 호출합니다.
BusinessWorks 웹 서비스가 전송한 SiebelAddfault 를 캐치하기 위해 catch block을 outer scope와 연계할 수 있습니다. SiebelAddfault가 발생할 때마다, compensate activity는 inner scope에 대한 보정작업을 수행하고 SAP 고객 레코드를 삭제합니다. 이때 inner scope의 모든 액티비티가 성공적인 경우에만 보정 작업이 성공적으로 완료될 수 있음을 참고하시기 바랍니다.
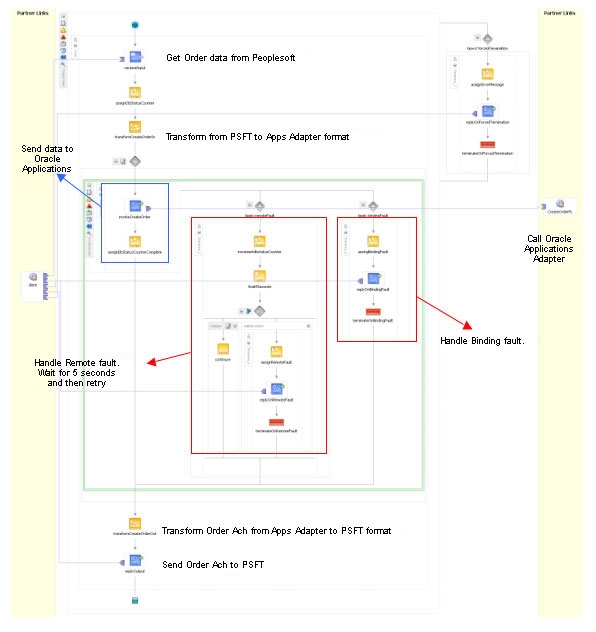
scope와 compensation handler를 수정한 BPEL 프로세스가 그림 6과 같습니다.
그림 6 SAP 고객 레코드 삭제를 위한 compensation logic
Case 6
Siebel 업데이트가 실패하고 SAP 업데이트만 성공한 경우에도 트랜잭션은 실패합니다. 이로 인해 데이터 일관성에 문제가 발생할 수 있습니다. 따라서, SAP에서 발생한 트랜잭션을 롤백 하기 위한 compensation logic이 필요합니다. Compensation handler는 SAP Update 서비스와 연계되어 SAP Rollback 서비스를 호출합니다. BPEL 프로세스의 수정 작업은 위에서 설명한 가이드라인을 준수하는 형태로 수행됩니다.
compensate activity를 명시적으로 호출할 수 있는 기능은 BPEL 에러 핸들링 프레임워크의 핵심으로 활용됩니다. 고전적인 EAI 보정 메커니즘과 달리, BPEL은 표준화된 롤백 방법론을 제공하고 있습니다.
TIBCO 및 webMethods 서비스의 통합을 위한 BPEL 프로세스를 생성했다면, 이제 BPEL 어댑터와 EAI 툴 간의 커뮤니케이션을 보다 효과적으로 수행할 수 있는 방법을 알아보기로 합시다.
4 단계: 비즈니스 커뮤니케이션의 보안. 보안은 아웃바운드(TIBCO, webMethods 서비스 호출의 보안)와 인바운드(BPEL 프로세스의 보안)의 두 레벨로 나누어 구현됩니다.
아웃바운드 보안 (Outbound Security)
먼저 TIBCO 및 webMethods 서비스에 대한 불법적인 액세스를 차단하기 위한 보안 대책이 필요합니다. Oracle BPEL Process Manager는 외부 서비스 호출 시 HTTP basic authentication 또는 WS-Security authentication을 지원합니다. 본 문서의 예제에서는 HTTP 인증을 사용하여 TIBCO 및 webMethods 서비스 및 BPEL 프로세스로부터의 호출 메커니즘의 보안을 구현하는 방법을 설명합니다.
TIBCO BusinessWorks와 webMethods Integration Server에 구현된 웹 서비스는 기본적으로 HTTP basic authentication을 지원합니다. TIBCO 웹 서비스를 설계하는 과정에서 SOAP event source activity의 Transport Details 탭에서 Use Basic Authentication 체크박스를 체크해야 합니다. TIBCO Administrator를 이용하여 웹 서비스를 구축하는 과정에서 사용자/역할 별로 서비스 액세스 레벨을 설정할 수 있습니다. 또 webMethods Developer를 이용하여 웹 서비스를 설정하는 과정에서 각각의 operation 별로 ACL(Access Control List)을 작성할 수 있습니다.
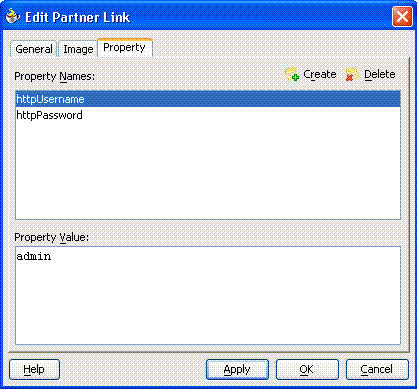
TIBCO, webMethods 서비스를 구축하는 과정에서 basic authentication을 사용하였다면, 서비스에 대한 호출이 수행될 때마다 인증정보가 BPEL 프로세스에 전달되어야 합니다. 두 개의 Partner Link 속성(httpUsername과 httpPassword)을 이용하면 이 작업을 쉽게 수행할 수 있습니다. 이 속성의 값은 아래와 같이 정적으로 설정될 수 있습니다.
그림 7 httpUsername과 httpPassword의 설정
인증정보를 다이내믹하게 전달하고자 하는 경우에는 copy rule을 사용합니다.
<copy>
<from variable="varUsername"/>
<to partnerLink="p1" bpelx:property="httpUsername"/>
</copy>
또, WS-Security를 이용하여 TIBCO, webMethods 서비스의 보안을 구현하는 것도 가능합니다. 이때 BPEL 프로세스는 WS-Security authentication header를 웹 서비스로 전달합니다. 이때 서비스가 지원하는 WS-Security 헤더를 WSDL 다큐먼트에 정의해 두어야 합니다. message body 데이터 엘리먼트와 마찬가지로, 이 헤더 필드는 BPEL 프로세스에 의해 변수로 활용됩니다. WS-Security 인증에 대한 자세한 정보는 OTN에서
HotelShopFlow 샘플 코드를
다운로드하셔서 확인하실 수 있습니다.
인바운드 보안 (Inbound Security)
HTTP 인증을 이용하면 BPEL 프로세스가 불법적인 사용자에 의해 차단되는 것을 방지할 수 있습니다. 또 각 BPEL 프로세스 별로 다른 인증 정보를 설정하는 것이 가능합니다.
이 기능을 사용하려면, 애플리케이션 서버 레벨에서 HTTP basic authentication을 활성화해야 합니다. 그런 다음 인증 정보는 BPEL 프로세스에 의해 호출되고 Partner Link 속을 통해 TIBCO, webMethods 웹 서비스로 전달됩니다.
BPEL 보안에 대한 보다 자세한 정보가 필요하신 경우 OTN의 "Securing BPEL Processes & Services" Webinar를 확인하시기 바랍니다.
5 단계: 중앙집중적 로깅 및 에러 핸들링. 비즈니스 프로세스의 보안과 안정성을 확보하는 것만큼이나, 중앙집중적인 로깅, 통보 기능을 구현하는 것 또한 중요합니다. 중앙집중적인 로깅, 에러 핸들링 프레임워크를 구현함으로써 애플리케이션의 안정성을 한층 더 강화하고, 재활용성을 증가시키고, 개발 비용을 절감할 수 있습니다. BPEL 프로세스의 웹 서비스 또는 미들웨어를 이용하여 이러한 프레임워크를 구축하는 것이 가능합니다. Oracle BPEL Process Manager의 파일 어댑터를 이용하여 서비스에 로깅 기능을 추가하고 에러 발생시 이메일 통보 기능을 구현할 수 있습니다.
프레임워크에 사용하게 될 샘플 스키마가 아래와 같습니다:
| 스키마 엘리먼트 |
설명 |
| ROLE |
ERROR, DEBUG, WARNING, INFO 등 |
| CODE |
에러 코드 |
| DESCRIPTION |
에러 설명 |
| SOURCE |
에러 소스 |
| EMAIL |
통보를 전달할 이메일 ID |
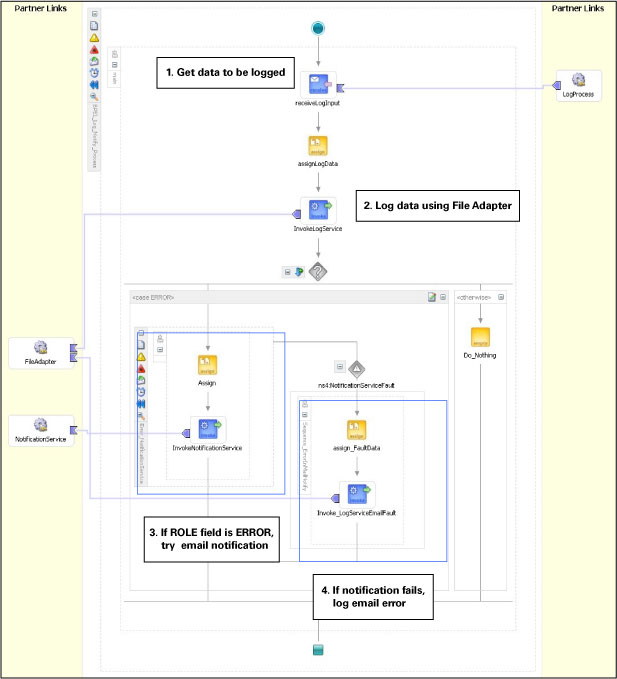
이 BPEL 프로세스는 비동기식 단방향 웹 서비스로서 공개되므로, 서비스의 클라이언트에는 별도의 시간 지연이 수반되지 않습니다. 중앙집중적 로깅 및 통보를 위한 LogNotify 프로세스가 아래 그림과 같습니다.
그림 8 Oracle BPEL Process Manager를 이용한 로깅 및 에러 핸들링 프레임워크
그림 8에서 확인할 수 있는 것처럼, LogNotify 프로세스는 아래와 같은 작업을 수행합니다:
- 외부 프로세스로부터 전달되는 정보를 로그에 저장합니다
- Log Service를 호출하여 데이터를 로그 파일에 저장합니다. 이 과정에서 Log Service는 파일 어댑터를 활용합니다.
- 로깅이 성공적인 경우 프로세스가 완료됩니다. 또 ROLE 필드에ERROR가 포함된 경우, 서비스는 이메일을 통해 담당자에게 통보를 수행합니다. 이메일 정보는 수신된 메시지 원본으로부터 추출됩니다 (샘플 스키마를 참고하십시오.).
- 이메일 통보 작업이 실패한 경우, 에러가 로그 파일에 저장된 후 프로세스가 종료됩니다.
메인 BPEL 프로세스에 포함된 각각의 invoke 액티비티는 별도의
try-catch 블록을 갖습니다. 미들웨어 프로세스가 전송한 SOAP 폴트(애플리케이션에서 발생한 exception 포함)는
catch블록에 의해 처리되며, 중앙 로깅/에러 핸들링 프레임워크에 라우팅됩니다.
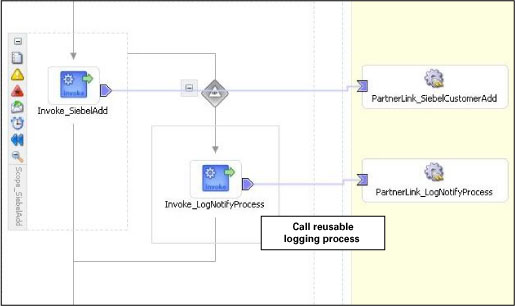
그림 9는
Siebel Add가 실패한 경우
LogNotify 프로세스가 호출되는 과정을 보여주고 있습니다.
결론
오늘날의 통합 시장은 강력한 EAI 제품으로 넘치고 있으며, 많은 통합 기능이 구현되어 제공되고 있습니다. BPEL은 기존 EAI 솔루션의 서비스 전환을 위한 독자적인 대안을 제공합니다. 기존 미들웨어 프로세스를 웹 서비스로 공개하고, 웹 서비스들을 Oracle BPEL Process Manager로 통합함으로써, 기업은 SOA를 위한 첫 걸음을 내디딜 수 있을 것입니다.
- 한국 오라클 -
 invalid-file
invalid-file