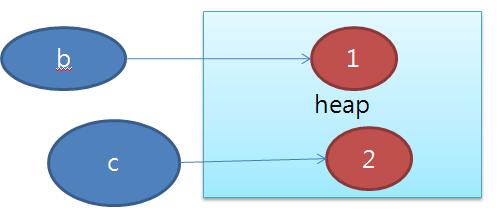
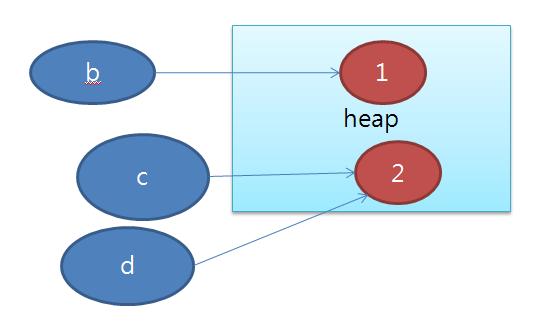
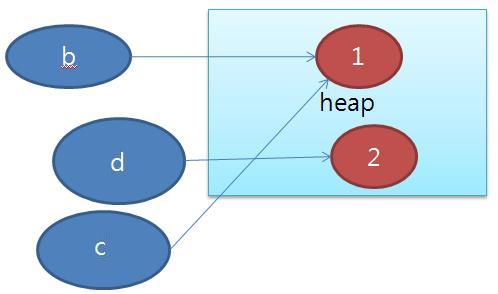
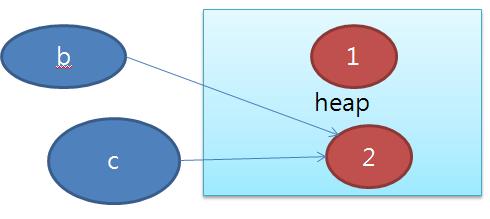
1. 연결된 상태에서 만약 클라이언트나 서버가 연결이 끊겼다면 이것에 대해서 처리가 힘들다. 특히 이전에 대한 상태 정보를 모두 잃어버린다.
2. 만약 어마어마한 양의 서버와 클라이언트가 물려있는 경우 비 활동적인 클라이언트로 인해 서버의 자원이 낭비될 수 있다.
3. 연결 지향 프로토콜은 방화벽을 통과하지 못한다.
4. 만약 프로토콜의 구조가 다른 서버, 클라이언트가 있다면 둘이 통신이 거의 불가능하다. 설사 가능하더라도 엄청 복잡하다. 만약 Client가 RMI를 사용하면 RMI를 사용하는 서버만 서버 쪽에 있는 메소드 호출이 가능하다.
이런 단점들이 있어서 나타난 것이 Web Service다.
웹 서비스는 XML기반이다. 즉 XML을 이용하면 서로 다른 시스템에서 응용프로그램끼리 공유가 가능하고 데이터 교환도 가능해진다. XML은 유니코드이기 때문에 유니코드를 인식하는 시스템에선 모두 사용이 가능하기 때문이다.
웹 서비스 이야기 (기초에서 실무까지 XML 웹서비스에서 발췌)
웹 서비스 시스템과 클라이언트는 지속적인 연결을 가지지 않는다. 클라이언트가 웹 서비스 시스템에서 제공하는 메서드를 호출하면, 웹 서비스 시스템은 메소드의 실행 결과를 클라이언트에게 보내주고 나서 즉시 연결을 해제한다
웹 서비스는 상태 정보를 유지하지 않는다. 클라이언트의 요청을 처리한 후 응답을 보내고 나서 즉시 연결이 해제되기 때문에 이전 클라이언트의 상태 정보를 웹 서비스는 유지하지 않는다. 이전에 접속한 클라이언트가 다시 접속하게 되면 새로운 클라이언트 접속으로 취급한다.
사용하는 프로토콜은 XML 기반의 SOAP이다. 웹 서비스와 클라이언트 간의 프로토콜로서 사용되는 것은 XML 기반의 SOAP이다. XML기반이 아주 중요한 의미를 가지는데 이것은 곧 플랫폼 중립적인 프로토콜을 말한다.
기존의 다른 프로토콜로 구현된 분산 컴포넌트 환경을 통합시킬 수 있다. 기존의 다른 프로토콜로 구현된 분산 컴포넌트 환경을 통합하는 것이 가능하다.인터넷상에서의 분산 컴퓨팅이 가능하다.
웹 서비스와 클라이언트는 SOAP을 사용해서 요청 및 응답을 한다. SOAP는 HTTP 전송 프로토콜에 의해서 운반될 수 있다. 방화벽은 일반적으로 HTTP 프로토콜은 통과시키기 때문에 SOAP 역시 통과될 수 있다. 이것은 큰 장점인 동시에 큰 단점으로 작용할 수 있다. 익명의 SOAP이 중요한 기능의 메소드를 실행시킬 수 있기 때문이다.
수많은 프로젝트에서 프로그램을 개발하면서 해당 프로그램에 필요한 인덱스를 생성하고 인덱스를 이용하여 성능 향상을 계획하는 사이트를 많이 보아왔다. 하지만, 많은 사이트에서 인덱스의 잘못된 선정으로 성능 문제가 발생하고 이로 인해 많은 고통을 경험하는 것을 수없이 많이 보아 왔다. 도대체 인덱스에는 어떠한 비밀이 존재하기 때문에 우리는 SQL을 위해 인덱스를 생성하고 성능 저하를 경험해야 하는 것인가? 이는 우리가 인덱스에 대해 두 가지의 잘못된 사실을 진실로 간주하기 때문이다. 이제부터 인덱스의 잘못된 두 가지 사실에 대해 정확히 파헤쳐 보자.
인덱스는 무엇인가?
나를 알고 적을 안다면 100전 100승이라고 했던가? 따라서, 인덱스를 효과적으로 이용하기 위해서는 인덱스에 대한 정확한 이해가 필요할 것이다. 인덱스의 정확한 이해 없이 인덱스를 논한다는 것은 수박 겉핥기에 지나지 않을 것이다.
여기서는 인덱스의 물리적 구조를 이야기하고 싶지는 않다. 인덱스의 물리적 구조도 필요하겠지만 우리가 반드시 이해해야 할 것은 인덱스의 논리적 구조이다. 많은 개발자들과 이야기를 하다 보면 인덱스에 대해 많은 것을 알고 있다고 생각하지만 많은 사람들이 인덱스의 논리적 구조에 대해 정확히 이해하지 못하는 경우가 매우 많았다. 필자는 인덱스의 논리적 구조는 사전의 인덱스와 동일하다고 자주 이야기를 한다. 그럼 이제부터 우리가 잘 알고 있는 사전의 인덱스를 정확히 분석해 보자. 이것이 우리가 인덱스의 논리적 구조를 정확히 이해하는 가장 빠른 지름길이 될 것이다.
우리가 학창 시절부터 사용하던 사전을 생각해 보자. 사전의 옆에는 사전의 인덱스가 존재할 것이다. 여기서 각각의 영어 알파벳은 컬럼의 값이라고 생각하면 된다. 예를 들어, GIRL이라는 단어는 4개의 컬럼의 값이며 첫 번째 컬럼의 값은 ‘G’이며 두 번째 컬럼의 값은 ‘I’가 된다고 가정하자. 이와 같은 가정에서 인덱스의 논리적 구조를 확인해 보자.
첫 번째로 인덱스는 첫 번째 컬럼의 값으로 정렬되어 구성되는 특징에 대해 확인해 보자. 사전의 인덱스를 확인해 보면 첫 번째 알파벳이 ‘A’로 시작하는 단어부터 시작하여 알파벳 순서로 정렬되어 사전을 구성하게 된다. 인덱스도 이와 같이 인덱스를 구성하는 첫 번째 컬럼의 값으로 정렬되어 구성된다. 이와 같은 사실은 대부분의 개발자들이나 또는 관리자들이 알고 있는 사실이다.
두 번째로 인덱스의 첫 번째 컬럼의 값이 동일한 경우에는 인덱스의 두 번째 컬럼의 값으로 정렬되는 특징에 대해 확인해 보자. 인덱스를 구성하는 첫 번째 컬럼의 값이 동일한 경우에는 어떻게 인덱스가 구성되겠는가? 이 또한 사전의 인덱스를 생각해보면 바로 답을 유추할 수 있음에도 불구하고 많은 사람들이 정확히 모르고 있다는 것이 현실이다. 만약, 사전이 ‘A’로 시작하는 단어를 순서 없이 모아두고 ‘B’로 시작하는 단어를 어떠한 순서에 상관 없이 모아 둔다면 이와 같이 구성된 사전이 의미 있겠는가?
예를 들어, GIRL이란 단어를 찾는다면 ‘G’로 시작하는 단어를 모아둔 사전의 페이지를 모두 읽어봐야 할 것이다. 이처럼 단어의 첫 번째 알파벳으로만 사전의 인덱스를 구성한다면 동일한 알파벳으로 시작하는 단어를 모아두었다는 약간의 의미는 있겠지만 그렇게 큰 의미는 없을 것이다. 사전의 인덱스를 확인해 보면 ‘A’로 시작하는 단어는 어떤 순서로 사전에 저장되어 있는가? 동일한 알파벳으로 시작하는 단어는 단어를 구성하는 두 번째 알파벳으로 정렬되어 저장된다.
이와 같기 때문에 GIRL이라는 단어를 찾는다면 ‘G’로 시작하는 단어 중 두 번째 알파벳이 ‘I’인 단어를 바로 찾게 된다. 두 번째 알파벳이 동일한 단어에 대해서는 세 번째 알파벳으로 정렬되어 사전에 저장될 것이다. 사전의 단어들이 이와 저장되기 때문에 우리는 사전을 효과적으로 사용할 수 있을 것이다. 정렬된 구조로 저장되기 때문에 우리가 원하는 단어를 바로 찾아갈 수 있을 것이다.
인덱스의 논리적 구조에는 위와 같은 특징을 가진다. 인덱스의 첫 번째 컬럼으로 인덱스는 정렬되어 구성되며 인덱스를 구성하는 첫 번째 컬럼의 값이 동일한 경우에는 인덱스를 구성하는 두 번째 컬럼으로 정렬되어 구성된다는 사실은 매우 중요한 사실이다. 이를 이해하고 이제부터 우리가 잘못 알고 있는 인덱스의 비밀을 확인해 보자.
인덱스를 이용해야만 성능은 향상되는가
우리가 SQL을 작성하면서 성능을 보장하기 위해 가장 먼저 무엇을 고려하는가? 가장 먼저 고려하는 사항은 인덱스일 것이다. 많은 경우에 작성한 SQL에 대해 인덱스를 생성한다면 성능을 보장 받을 수 있다고 생각하게 된다. 과연, 인덱스만 생성한다면 해당 SQL의 성능을 보장할 수 있겠는가? 어떤 SQL은 인덱스 때문에 성능이 엄청 저하될 수 있는 것이 현실이다. 이러한 경우는 경험해본 사람이라면 쉽게 이해할 수 있을 것이다.
그렇다면 어떤 경우의 SQL에는 인덱스가 필요하고 어떤 경우의 SQL에는 인덱스가 필요하지 않은 것일까? 인덱스를 이용하여 성능을 최적화하기 위해서 어떤 컬럼으로 인덱스를 구성할 것인가에 대한 것보다도 해당 SQL이 인덱스를 이용해야 할지 아니면 해당 SQL이 인덱스를 이용하면 안 되는지에 대한 정확한 기준이 필요하다. SQL을 작성하는 사람들은 이러한 기준을 가지고 있는가? 아마도 많은 사람들이 이러한 기준을 가지고 있지 않을 것이다. 이러한 문제는 SQL을 작성하는 개발자들만의 문제가 아니다.
우리가 많이 사용하는 툴들은 해당 SQL의 실행 계획에서 인덱스를 이용하지 못하는 경우에 빨간색을 표시하게 된다. 이와 같은 현상이 마치 무조건 문제인 것처럼 보이게 만들어 무조건 인덱스를 생성하게 만드는 경우도 많다. 이제부터 우리는 어떤 SQL은 인덱스를 이용하고 어떤 SQL은 인덱스를 이용해서는 안 되는지에 대해 정확하게 구분해야 할 것이다.
첫 번째로 인덱스를 이용해서는 안 되는 SQL에 대해 확인해 보자. 어떤 SQL이 인덱스를 이용하면 안 되는지에 대해 언급하기 전에 하나의 예제를 확인해 보자. 어떤 사이트를 지원 했을 때의 일이다. 개발 담당자는 매일 저녁 9시부터 1시간 동안 야간 통계 작업을 수행한 후 SQL의 수행 결과를 확인하고 퇴근을 하는 경우를 보았다. 해당 담당자는 매일 저녁 이와 같은 작업을 1년 동안 수행하고 있었다.
해당 SQL을 확인한 결과 해당 SQL은 해당 테이블의 대부분의 데이터를 액세스하여 통계 데이터를 추출하고 있었다. 해당 데이터를 액세스 하는 과정에는 인덱스를 이용하고 있었다. 해당 SQL을 최적화한 후에는 1시간 동안 수행되던 SQL이 단지 50초 정도에 종료할 수 있었다. 최적화 하는 과정은 해당 SQL이 인덱스를 이용하지 못하게 하고 테이블을 전체 스캔하도록 변경해 주었다.
단지, 인덱스를 이용하는가 아니면 인덱스를 이용하지 않는가에 의해 이와 같이 큰 영향을 미치게 된 것이다. 다른 어느 사이트에서도 이러한 문제를 인식하지 못하고 당연히 오래 수행되는 작업이라고 생각하고 매일 작업을 수행하고 있는 사이트가 있을 것이다.
바로 이것이 SQL이 인덱스를 이용해야 하는지 이용해서는 안 되는지에 기준을 제시해 줄 것이다. 그렇다면 인덱스를 이용해야 할지 인덱스를 이용하면 안되는지에 대한 기준을 제시하는 요소는 무엇인가? 바로 액세스 하는 데이터의 양이다.
해당 테이블에서 많은 양의 데이터를 액세스 한다면 인덱스를 이용하여 테이블을 액세스 하는 경우에는 인덱스를 액세스 한 후 테이블을 액세스 하는 랜덤 액세스 가 발생하기 때문에 성능은 매우 저하된다. 이와 같은 경우라면 인덱스를 이용하여 테이블을 액세스 하는 방법보다는 인덱스를 이용하지 않고 테이블을 전체 액세스 하는 경우가 더 빠른 성능을 보장하게 될 것이다.
예를 들어, 1만개의 단어를 저장하고 있는 사전에서 5000개의 단어를 찾는다고 가정하자. 해당 사전은 한 페이지에 20개 씩의 단어가 기록되어 있으며 그렇기 때문에 전체 페이지는 500 페이지가 된다고 가정하자. 이와 같다면 여러분들은 사전의 인덱스를 이용하여 원하는 5000개의 단어를 찾을 것인가 아니면 사전의 인덱스를 이용하지 않고 테이블의 데이터를 액세스 할 것인가?
대부분의 사람들은 사전의 인덱스를 이용하지 않고 테이블의 데이터를 액세스 해야 더 빠른 성능을 보장할 수 있을 거라고 이야기한다. 이는 분명히 맞는 답이다. 20개의 단어가 저장되어 있는 하나의 페이지에서 평균 10개의 단어는 우리가 찾고자 하는 단어일 것이다. 이와 같은 경우 사전의 인덱스를 이용한다면 하나의 페이지를 10번씩 액세스 하게 된다. 하지만, 사전의 인덱스를 이용하지 않고 사전을 처음부터 끝까지 읽게 된다면 하나의 페이지에서 10개의 단어를 찾을 수 있기 때문에 우리는 하나의 페이지를 한번만 액세스 하면 될 것이다. 하나의 페이지를 10번 액세스 하는 것이 빠르겠는가 아니면 하나의 페이지를 한번만 액세스 하는 것이 빠르겠는가? 두 말할 것도 없이 하나의 페이지를 한번만 액세스 하는 것이 빠를 것이다. 이와 같은 차이에 의해 성능에 있어서는 엄청난 차이가 발생할 수 밖에 없게 된다.
결국, 인덱스를 이용해야 할지 아닐지는 액세스 하는 데이터의 양에 의해 좌우된다. SQL의 성능을 최적화하기 위해 무조건 인덱스를 생성해서는 안될 것이다. 해당 SQL이 테이블의 많은 데이터를 액세스 해야 한다면 인덱스를 이용하는 것보다는 테이블을 전체 스캔하는 방법이 성능을 보장한다는 것을 명심하길 바란다.
두 번째로 인덱스를 이용해야 하는 SQL을 확인해 보자. SQL은 위와 같이 테이블을 전체 스캔해야 하는 SQL을 제외하면 인덱스를 이용하여 데이터를 액세스 해야 할 것이다.
그렇다면 테이블의 데이터 중 어느 정도의 데이터를 액세스 하는 것이 많은 양의 데이터를 액세스 하는 것일까? 또는 어느 정도의 데이터를 액세스 해야 적은 양의 데이터를 액세스 하는 것일까? 일반적으로 해당 테이블의 3%~5% 정도의 데이터가 기준이 된다. 해당 테이블의 데이터가 10만건이라고 가정하자. 그렇다면 3000건에서 5000건의 데이터가 기준이 될 것이다. 따라서, 1000건의 데이터를 액세스 해야 한다면 인덱스를 이용하는 것이 성능을 보장할 수 있게 된다.
하지만 10만건의 데이터를 액세스 하는 경우에는 3%~5%의 기준을 넘게 되므로 인덱스를 이용하는 것보다는 인덱스를 이용하지 않는 것이 더 유리할 것이다. 테이블의 데이터가 대용량이라면 3%~5%의 기준 값은 낮아질 것이다. 그렇기 때문에 초 대용량 테이블은 1%가 기준이 되기도 한다. 이와 같은 정확한 기준 값이 중요한 것은 아니다.
중요한 것은 많은 데이터를 액세스 하는 SQL이 인덱스를 이용한다면 우리가 원하는 성능을 보장 받을 수 없으며 반대로 인덱스를 이용해야 하는 SQL이 인덱스를 이용하지 않는다면 이 또한 성능을 보장 받을 수 없다는 것이다.
이와 같기 때문에 SQL을 작성하는 경우 해당 SQL이 인덱스를 이용해야 할지 아니면 테이블을 전체 스캔해야 할지를 가장 먼저 고려해야 할 것이다. 이제는 맹목적으로 해당 SQL에 인덱스를 생성해야 성능을 보장 받을 수 있다는 잘못된 사실에서 벗어나야 할 것이다.
인덱스 컬럼들의 순서와 분포도는 많은 상관 관계가 없다
SQL에 필요한 인덱스를 생성한다면 우리는 많은 경우에 결합 인덱스를 생성하게 된다. 결합 인덱스를 생성하면서 많은 경우에는 해당 컬럼의 분포도를 고려하여 분포도가 좋은 컬럼을 인덱스의 첫 번째 컬럼으로 구성하는 경우를 많이 보았을 것이다. 과연, 이와 같이 분포도가 좋은 컬럼을 결합 인덱스의 첫번째 컬럼으로 선정하는 방식이 우리가 선택할 수 있는 최상의 인덱스 선정일까?
결론부터 언급하자면 결합 인덱스에서는 컬럼의 분포도는 의미가 없게 된다. 이 뜻은 결합 인덱스를 생성하는 경우 각 컬럼의 분포도는 의미가 없다는 것이다. 분포도를 고려하지 않고 결합 인덱스를 생성한다는 것은 말이 되지 않는다고 할 수도 있을 것이다. 하지만, 분명한 것은 결합 인덱스에서의 분포도는 큰 의미를 가지지 않는다. 왜 이와 같은 현상이 발생하는 것일까?
카드 회사에서 카드 가입자의 카드번호만을 관리하는 테이블에서 카드번호 컬럼은 분포도가 매우 좋을 것이다. 하지만, 여기서 우리는 하나의 함정에 빠지게 된다. 그것은 무엇인가? 바로 분포도가 좋다는 뜻에 대한 함정이다. 우리가 카드번호 값에 대해 분포도가 좋다는 뜻은 무엇을 의미하는가? 이는 하나의 카드번호만을 액세스 하는 경우에 해당할 것이다.
모든 카드번호는 ‘1’로 시작한다고 가정하자. 만약, 카드번호 값에 대해 ‘1’로 시작하는 카드번호 값을 액세스 한다면 분포도는 어떠한가? 이와 같이 데이터를 액세스 한다면 아무리 분포도가 좋은 카드번호 컬럼도 많은 데이터가 추출되며 분포도는 안 좋게 된다. 결국, 우리가 항상 이야기 하는 분포도가 좋은 컬럼과 분포도가 나쁜 컬럼 컬럼의 기준에는 우리도 모르게 동일한 데이터를 액세스 하는 경우를 의미하게 된다.
‘111111’번 카드번호 값을 액세스 한다면 우리가 원하는 데이터는 한건의 데이터가 되므로 분포도는 좋게 된다. 하지만, SQL에서 ‘1’로 시작하는 모든 카드번호 데이터를 액세스 한다면 분포도는 나쁘게 된다. 이와 같이 우리가 말하는 분포도는 서로 약속은 안 했지만 해당 컬럼의 값과 동일한 데이터를 추출하는 경우에 해당하게 된다.
결국, 우리가 말하는 분포도는 동일한 값을 의미하게 된다. 하지만, 우리가 추출하고자 하는 데이터는 항상 동일한 데이터만을 의미하지는 않게 된다. 때로는 LIKE 연산자 또는 BETWEEN 연산자 등을 많이 이용하기 때문에 이런 경우라면 해당 컬럼의 분포도는 의미 없게 된다. 이와 같은 이유에서 해당 컬럼의 분포도는 더 이상 결합 인덱스를 생성하는 컬럼의 순서에 중요한 역할을 수행하지 못하게 된다.
인덱스 컬럼들의 순서를 효과적으로 선정하자
인덱스를 구성하는 각각의 컬럼의 분포도가 중요하지 않다면 결합 인덱스를 구성하는 컬럼의 순서를 고려할 경우 가장 먼저 고려해야 하는 요소는 무엇인가? 결합 인덱스를 구성할 경우 우리가 반드시 고려해야 하는 요소는 아래와 같다.
점 조건과 선분 조건
결합 인덱스의 순서를 정하는 가장 중요한 요소는 해당 컬럼에 사용되는 연산자이다. 아직도 많은 교육과 문서에서 컬럼의 분포도가 인덱스 선정에 중요하다고 언급하는 경우가 있다. 하지만, 이러한 것이 우리에게 많은 오류를 발생시킨다는 것을 이해하길 바란다. 가장 중요한 요소는 해당 컬럼을 액세스 하는 연산자라는 것을 명심하길 바란다. 위에서 점 조건에는 =과 IN 연산자만이 포함되며 나머지 연산자는 선분 조건에 해당된다.
SQL> SELECT …… FROM TAB1 WHERE COL1 = ‘A’ AND COL2 BETWEEN ‘A’ AND ‘B’;
위와 같은 SQL이 수행되며 각 컬럼의 분포도는 COL1 컬럼의 경우에는 분포도가 좋으며 COL2 컬럼의 경우에는 분포도가 좋지 않다고 가정하자. 그렇다면 많은 사람들은 분포도만을 고려하여 COL2+COL1 인덱스를 생성하려고 하는 경우가 많다. 하지만, COL2 컬럼은 BETWEEN 연산자를 사용했으므로 해당 컬럼의 분포도는 의미가 없게 된다. 따라서, 위의 SQL에서 최적의 인덱스는 COL1+COL2 인덱스가 된다.
결국, 분포도를 배제하고 연산자를 통해 결합 인덱스를 생성해야 한다. 이와 같이 인덱스를 구성해야만 COL1 컬럼과 COL2컬럼에 의해 처리 범위가 감소하게 된다. 앞의 값의 하나의 값이 아닌 선분 조건이라면 처리 범위는 증가하기 때문이다. 결합 인덱스는 반드시 아래와 같은 특성을 가지게 된다.
● 점 조건+점 조건: 두 컬럼에 의해 처리 범위 감소 ● 점 조건+선분 조건: 두 컬럼에 의해 처리 범위 감소 ● 선분 조건+선분 조건: 앞의 선분 조건에 의해서만 처리 범위 감소 ● 선분 조건+점 조건: 앞의 선분 조건에 의해서만 처리 범위 감소
위와 같이 컬럼의 분포도가 아닌 컬럼의 연산자에 의해 인덱스는 처리 범위를 감소시키게 되며 처리 범위를 가장 많이 감소시킬 수 있는 형태의 결합 인덱스만이 성능을 보장할 수 있게 된다. 분포도에 의한 결합 인덱스 선정이 아닌 연산자에 의한 결합 인덱스 선정의 중요성을 인식하길 바란다. 이것이야 말로 해당 SQL의 성능을 보장할 수 있는 유일한 방법이다.
SQL을 작성한 후 무조건 인덱스를 만들려고 하는 생각과 결합 인덱스에서 연산자를 고려하지 않고 분포도가 좋은 컬럼을 앞에 위치시키는 인덱스야 말로 성능을 저하시키는 주범이 된다. 이제부터 최적의 인덱스를 선정하기 위해 우리 함께 노력해야 할 것이다. 인덱스에 대한 우리가 쉽게 빠질 수 있는 함정에 빠지지 않게 항상 주의해야 할 것이다.
자바에서 static으로 선언하면 해당 메서드나 변수는 정적이된다. 만약 클래스의 변수를 static으로 선언하게 되면 그 변수는 객체의 변수가 되는 것이 아니라 클래스의 변수가 된다. 클래스의 변수이기 때문에 어떤 객체라도 동일한 주소의 변수를 참조하게 된다.
static의 특징
객체를 생성해도 static 변수는 메모리에 하나만 생성된다.
다른 JVM에서는 선언을 하면 다른 주소나 다른 값을 참조하지만 같은 JVM이나 WAS 인스턴스에서는 같은 주소와 같은 값을 참조한다.
CG의 대상도 되지 않는다.
지역변수에 static을 사용할 수 없다. (매서드 안에서 사용 불가능)
만약에 properties파일을 많이 사용한다면 차라리 static으로 읽어서 관리하는 것도 좋다. 왜냐하면 매번 클래스의 객체가 만들어질 때 properties를 불러오려면 부하가 많이 걸리기 때문이다.
조심해야할 것 위에 말했듯이 static은 CG 대상이 아니다. 그렇기 때문에 잘못하면 Memory Leak 현상이 발생하게 된다. 이는 시스템의 메모리를 마구 먹어서 결국은 OutofMemoryError을 발생시킬 수 있다. (Collection을 Static으로 잡고 안에 아무 데이터나 마구 넣은다음 돌려보길 바란다. 그럼 바로 GG..)
final
final은 한번 final로 지정한 값은 변하지 않는다. 변수 앞에 final이 붙으면 상수를 의미한다.
XPath uses path expressions to select nodes in an XML document. The node is selected by following a path or steps. The most useful path expressions are listed below:
Expression
Description
nodename
Selects all child nodes of the named node
/
Selects from the root node
//
Selects nodes in the document from the current node that match the selection no matter where they are
.
Selects the current node
..
Selects the parent of the current node
@
Selects attributes
Examples
In the table below we have listed some path expressions and the result of the expressions:
Path Expression
Result
bookstore
Selects all the child nodes of the bookstore element
/bookstore
Selects the root element bookstore
Note: If the path starts with a slash ( / ) it always represents an absolute path to an element!
bookstore/book
Selects all book elements that are children of bookstore
//book
Selects all book elements no matter where they are in the document
bookstore//book
Selects all book elements that are descendant of the bookstore element, no matter where they are under the bookstore element
//@lang
Selects all attributes that are named lang
Predicates
Predicates are used to find a specific node or a node that contains a specific value.
Predicates are always embedded in square brackets.
Examples
In the table below we have listed some path expressions with predicates and the result of the expressions:
Path Expression
Result
/bookstore/book[1]
Selects the first book element that is the child of the bookstore element.
Note: IE5 and later has implemented that [0] should be the first node, but according to the W3C standard it should have been [1]!!
/bookstore/book[last()]
Selects the last book element that is the child of the bookstore element
/bookstore/book[last()-1]
Selects the last but one book element that is the child of the bookstore element
/bookstore/book[position()<3]
Selects the first two book elements that are children of the bookstore element
//title[@lang]
Selects all the title elements that have an attribute named lang
//title[@lang='eng']
Selects all the title elements that have an attribute named lang with a value of 'eng'
/bookstore/book[price>35.00]
Selects all the book elements of the bookstore element that have a price element with a value greater than 35.00
/bookstore/book[price>35.00]/title
Selects all the title elements of the book elements of the bookstore element that have a price element with a value greater than 35.00
Selecting Unknown Nodes
XPath wildcards can be used to select unknown XML elements.
Wildcard
Description
*
Matches any element node
@*
Matches any attribute node
node()
Matches any node of any kind
Examples
In the table below we have listed some path expressions and the result of the expressions:
Path Expression
Result
/bookstore/*
Selects all the child nodes of the bookstore element
//*
Selects all elements in the document
//title[@*]
Selects all title elements which have any attribute
Selecting Several Paths
By using the | operator in an XPath expression you can select several paths.
Examples
In the table below we have listed some path expressions and the result of the expressions:
Path Expression
Result
//book/title | //book/price
Selects all the title AND price elements of all book elements
//title | //price
Selects all the title AND price elements in the document
/bookstore/book/title | //price
Selects all the title elements of the book element of the bookstore element AND all the price elements in the document
이번호 technical tips에서는 SQL문의 성능을 결정하는 비용기반 옵티마이저의 핵심 원리 중에 비용계산 방법에 대해 알아 보도록 하겠다. 대부분의 개발자들이 작성하는 SQL문은 비용기반 옵티마이저 환경에서 작성된 실행계획을 통해 실행 되어지는데, 이때 옵티마이저의 비용계산 방법에 대해 정확히 이해한다면 더 좋은 성능을 보장 받는 SQL문을 작성할 수 있을 것이다.
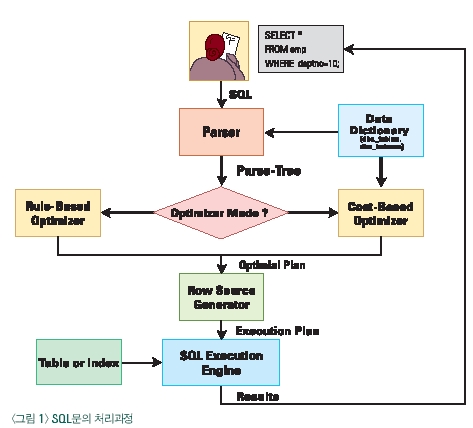
옵티마이저의 비용계산 방법을 소개하기 전에 우선 SQL문의 처리과정의 대해 알아보자. 사용자가 실행하는 SQL문은 파서(Parser)에게 전달되고 파서는 데이터 딕셔너리 정보를 참조하여 SQL문에 대한 구문분석(Syntax와 Symantics)을 수행한다. 이 결과를 파스-트리(Parse-Tree)라고 한다. 파스-트리는 옵티마이저에게 전달되는데 오라클 데이터베이스에는 공식기반 옵티마이저(Rule-Based Optimizer)와 비용기반 옵티마이저(Cost-Based Optimizer)가 있다. 비용기반 옵티마이저에 의해 산출된 적정 플랜(Optimal Plan)은 로우 소스 생성기(Row Source Generator)에게 전달되고 이것은 실행 계획(Execution Plan)으로 결정된다. 우리가 SET AUTOTRACE, SQL*TRACE와 TKPROF와 같은 튜닝 도구들을 통해 참조할 수 있는 결과에 바로 이 실행계획이 포함되어 있다. 이 실행계획은 SQL 실행엔진(SQL Execution Engine)에 의해 테이블과 인덱스를 참조하여 그 결과를 사용자에게 리턴하게 되는 것이다.
이어서, 비용기반 옵티마이저가 어떤 비용계산 방법을 통해 적절한 실행 계획을 찾아내는지를 소개할 것이다. 개발작업 때 처음부터 좋은 실행계획을 작성할 수 있도록 SQL문을 작성한다면 SQL 튜닝에 대한 불필요한 시간과 비용을 줄여 나감으로써 좋은 성능의 시스템을 개발할 수 있는 첫걸음이 되는 것이다.
2. 비용기반 옵티마이저의 구조
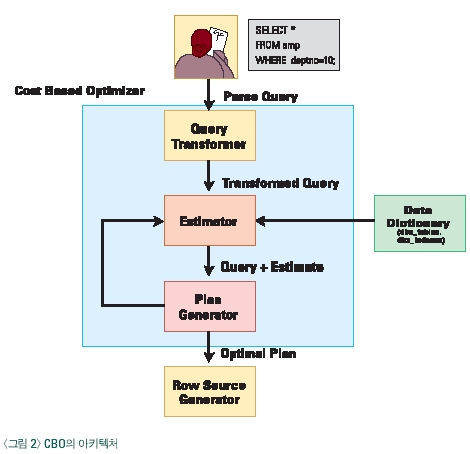
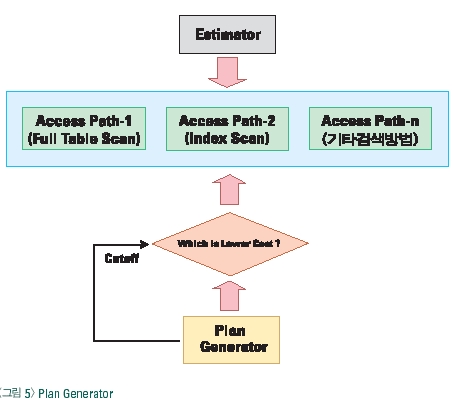
이번에는 구체적으로 비용기반 옵티마이저의 아키텍처에 대해 알아보도록 하겠다. CBO(Cost Based Optimizer)가 어떻게 비용을 계산하고 어떻게 실행계획을 작성하는지를 알기 위해서는 보다 구체적으로 CBO의 아키텍처의 대해 알고 있어야 한다. <그림 2>에서와 같이 CBO는 쿼리 변형기(Query Transformer), 비용 계산기(Estimator), 쿼리 작성기(Query Generator) 3가지 구조로 구성되어 있다. 그럼, 각 구성 요소와 비용계산 알고리즘을 통해 실행계획 작성 방법에 대해 알아 보자.
3. 쿼리 변형기(Query Transformer)
쿼리 변형기는 파서(Parser)에 의해 구문 분석된 결과를 전달 받아 잘못 작성된 SQL문을 정확한 문장으로 변형시키는 역할을 수행한다.
? 잘못된 데이터 타입으로 조건 값을 검색하면 변형된다. (S_DATE 컬럼은 날짜 컬럼인데 문자 값을 검색할 때 사용하는 인용부호를 사용한 경우)
SQL> SELECT * FROM emp WHERE s_date = '1999-01-01'; --> SQL> SELECT * FROM emp WHERE s_date = TO_DATE('1999-01-01');
? LIKE 연산자는 %(와일드 카드)와 함께 검색하는 경우 사용되지만, 그렇지 않은 경우 =(동등) 조건으로 변형되어 검색된다.
SQL> SELECT * FROM emp WHERE ename LIKE '주종면‘; --> SQL> SELECT * FROM emp WHERE ename = ‘주종면’;
? BETWEEN ~ AND 조건은 > AND < 조건으로 변형되어 검색된다.
SQL> SELECT * FROM emp WHERE salary BETWEEN 100000 AND 200000; --> SQL> SELECT * FROM emp WHERE salary >= 100000 and salary <= 200000;
? 인덱스가 생성되어 있는 컬럼의 IN 연산자의 조건은 OR 연산자의 조건으로 변형된다.
SQL> SELECT * FROM emp WHERE ename IN ('SMITH', 'KING'); --> SQL> SELECT * FROM emp WHERE ename = 'SMITH' or ename = 'KING';
? 인덱스가 생성되어 있는 컬럼의 OR 연산자의 조건은 UNION ALL로 변형된다.
SQL> SELECT * FROM emp WHERE ename = 'SMITH' or sal = 1000; SQL> SELECT * FROM emp WHERE ename = 'SMITH' UNION ALL SELECT * FROM emp WHERE sal = 1000;
이와 같이 쿼리 변형기는 부적절하거나 잘못 작성된 SQL문장을 정확한 문장으로 변형시켜주는 역할을 수행하는 알고리즘이다.
4. 비용 계산기(Estimator)
비용 계산기는 비용기반 옵티마이저가 가지고 있는 비용 계산 공식에 의해 다양한 실행방법 중에 가장 좋은 성능의 실행계획을 찾아 주는 알고리즘이다.
1) 테이블과 인덱스의 통계정보
먼저, ANALYZE 명령어에 의해 수집되는 통계정보의 상태와 용어에 대해 설명하겠다. 먼저, 테이블에 대한 통계정보이다.
NUM_ROWS : 인덱스 행 수 L_BLOCKS : 하나의 LEAF 블록에 저장되어 있는 인덱스 키의 수 D_BLOCKS : 하나의 DATA 블록에 저장되어 있는 인덱스 키의 수 CL-FAC : CLUSTER FACTOR BLEVEL : INDEX의 DEPTH LEAF : LEAF 블록의 수
통계 정보는 오라클 10g 이전 버전까지는 사용자가 실행하는 ANALYZE 명령어에 의해 생성되었으며 10g 버전부터는 오라클 서버의 자동화된 알고리즘에 의해 자동 생성된다. 오라클 9i 버전 때까지는 사용자에 의해 통계정보를 생성해 주지 않으면 비용기반 옵티마이저는 부정확한 실행계획을 작성함으로써 성능이 저하되는 경우들이 많이 발생했었다. <그림 3>은 통계정보가 생성되어 있지 않은 경우 비용기반 옵티마이저가 참조하는 통계정보의 기본 값이다. 데이터를 저장하고 있는 테이블과 인덱스의 실제 구조정보와 다른 값을 참조하기 때문에 결론적으로 좋은 실행계획을 작성하지 못하는 것이다.
2) 용어에 대한 이해 SQL> SELECT * FROM big_emp;
Execution Plan ---------------------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=19 Card=28955 Bytes=1042380) 1 0 TABLE ACCESS (FULL) OF 'BIG_EMP' (Cost=19 Card=28955 Bytes=1042380)
COST : SQL문을 실행하여 조건을 만족하는 행을 검색하는데 소요되는 횟수 CARDINALITY : 전체 테이블에서 SQL문의 조건을 만족하는 행 수
3) Cardinality
일반적으로 cardinality는 SQL문이 실행되었을 때 조건을 만족하는 행수를 의미하는 것이긴 하지만 이것은 검색되는 컬럼이 어떤 속성을 가지고 있느냐에 따라 계산 공식이 달라진다.
3-1) Distinct Cardinality(Unique-Key)인 경우
이 경우는 주로 Full Table Scan과 같이 테이블 전체 행을 검색하는 경우의 cardinality를 계산하는 공식이다.
SQL> SELECT count(*) FROM big_dept; count(*) ------------------ 289
SELECT * FROM emp WHERE empno > 200; --> Selectivity = (범위값 - 최소값) / (최대값 - 최소값) = (29799 - 1) / (29999 - 1) = 29798 / 29998 = 0.9 SELECT * FROM emp WHERE empno BETWEEN 100 AND 200; --> Selectivity = (최대 조건값 - 최소 조건값) / (최대값 - 최소값) = (200 - 100) / (29999 - 1) = 100 / 29998 = 0.003
4-4) 바인드 변수를 가진 비동등식의 경우
SELECT * FROM emp WHERE empno < :a ; --> Selectivity = 0.25 % (나쁜 선택도)
SELECT * FROM emp WHERE empno BETWEEN :a AND :b ; --> Selectivity = 0.5 % (나쁜 선택도)
5. 비용 계산 방법
지금까지 비용기반 옵티마이저가 비용을 계산하기 위해 알아야 할 여러 가지 내용에 대해 알아보았다. 그럼 지금부터는 다양한 SQL문의 비용 계산 공식에 대해 알아보자.
5-1) Full Table Scan인 경우
Cost = 전체 블록 수 / DB_FILE_MULTIBLOCK_READ_COUNT의 보정 값
인덱스를 사용하지 않고 해당 테이블의 첫 번째 블록부터 전체 블록을 검색해야 하는 전체 테이블 스캔의 경우에는 init.ora 파일에 정의되어 있는DB_FILE_MULTOBLOCK_READ_COUNT 파라메터 값에 의해 비용이 계산된다. 이 파라메터는 FULL TABLE SCAN의 경우 한번에 하나의 I-O로는 성능을 기대할 수 없기 때문에 보다 빠른 성능을 기대하기 위해 제공되는 다중 블록 읽기를 위한 파라메터이다. 즉, 한번 I-O에 8개, 16개, 32개, 64개의 다중 블록을 읽게 하기 위함이다.
SQL> SHOW PARAMETER db_file_multiblock_read_count NAME TYPE VALUE ------------------------------------------------------------------------------------- db_file_multiblock_read_count integer 16 SQL> SELECT * FROM big_emp;
Execution Plan ---------------------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=19 Card=28955 Bytes=1042380) 1 0 TABLE ACCESS (FULL) OF 'BIG_EMP' (Cost=19 Card=28955 Bytes=1042380)
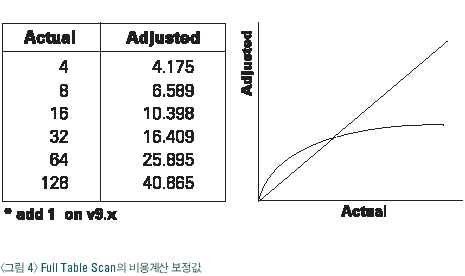
앞에서 소개된 비용 계산 공식을 적용해보면 COST = 180 / 16 = 11.25의 결과가 나와야 하는데 실제 비용은 COST=19의 결과가 계산되었다 !! 이것은 DB_FILE_MULTIBLOCK_READ_COUNT 파라메터의 실제 값처럼 한번 I-O에 8, 16, 32, 64개의 블록을 읽을 수는 없기 때문에 파라메터의 실제 값이 아닌 보정 값으로 비용을 계산했기 때문이다. <그림 4>의 왼쪽 표는 ACTUAL (DB_FILE_MULTIBLOCK_READ_COUNT 파라메터 값)에 따른 Adjusted(보정 값)이며 <그림 4>의 오른쪽 그림은 이 파라메터가 실제로 성능의 영향을 미치게 되는 영향도를 그림으로 나타낸 것이다. 즉, COST = 19는 (180 / 10.398) +1의 계산 공식 결과임을 알 수 있다. 사용자가 실행하는 SQL문의 실행계획이 FULL TABLE SCAN으로 결정되도록 유도하기 위해서는 이 파라메터 값을 조절하면 된다.
SQL> ALTER SESSION SET db_file_multiblock_read_count = 8; SQL> SELECT * FROM big_emp;
Execution Plan ------------------------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=29 Card=28955 Bytes=1042380) 1 0 TABLE ACCESS (FULL) OF 'BIG_EMP' (Cost=29 Card=28955 Bytes=1042380)
위 SQL문의 비용은 Cost = (180 / 6.589) + 1 = 29 이다. 파라메터 값의 변경에 따라 비용이 달라지는 것을 확인할 수 있을 것이다.
SQL> ALTER SESSION SET db_file_multiblock_read_count = 32; SQL> SELECT * FROM big_emp;
Execution Plan ------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=13 Card=28955 Bytes=1042380) 1 0 TABLE ACCESS (FULL) OF 'BIG_EMP' (Cost=13 Card=28955 Bytes=1042380)
위 SQL문의 비용은 Cost = (180 / 16.409) + 1 = 13이다.
5-2) Unique Index Scan인 경우
Cost = blevel + 1
UNIQUE INDEX를 이용한 비용은 LEAF 블록의 DEPTH +1 이 된다.
SQL> CREATE UNIQUE INDEX I_big_emp_empno ON BIG_EMP (EMPNO); SQL> ANALYZE INDEX I_big_emp_empno compute statistics;
SQL> SELECT INDEX_NAME, BLEVEL FROM USER_INDEXES WHERE INDEX_NAME = 'I_BIG_EMP_EMPNO';
SQL> SELECT /*+index(big_emp I_big_emp_empno )*/ ename FROM big_emp WHERE empno = 7499; -------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=1 Bytes=20) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'BIG_EMP' (Cost=2 Card=1 Bytes=20) 2 1 INDEX (UNIQUE SCAN) OF 'I_BIG_EMP_EMPNO' (UNIQUE) (Cost=1 Card=100)
위 SQL문의 비용은 Cost = 1 + 1 = 2이다.
5-3) Fast Full Index Scan인 경우
Cost = leaf_blocks / db_block_size
SQL> CREATE INDEX emp_job_deptno ON BIG_EMP (job, deptno); SQL> ANALYZE INDEX emp_job_deptno compute statistics; SQL> SELECT INDEX_NAME, LEAF_BLOCKS FROM USER_INDEXES WHERE INDEX_NAME = 'EMP_JOB_DEPTNO';
SQL> SELECT /*+INDEX(BIG_EMP i_big_emp_deptno)*/ * FROM BIG_EMP WHERE DEPTNO = 10 ;
Execution Plan ------------------------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=53 Card=294 Bytes=10584) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'BIG_EMP' (Cost=53 Card=294 Bytes=10584) 2 1 INDEX (RANGE SCAN) OF 'I_BIG_EMP_DEPTNO' (NON-UNIQUE) (Cost=1 Card=294)
위 SQL문의 비용은 Cost = 1 + (1/98 * 57) +(1/98 * 5036) = 53이다.
SQL> ALTER SESSION SET optimizer_index_cost_adj = 50; SQL> SELECT /*+INDEX(BIG_EMP)*/ * FROM BIG_EMP WHERE DEPTNO = 10 ;
Execution Plan ------------------------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=27 Card=294 Bytes=10584) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'BIG_EMP' (Cost=27 Card=294 Bytes=10584) 2 1 INDEX (RANGE SCAN) OF 'I_BIG_EMP_DEPTNO' (NON-UNIQUE) (Cost=1 Card=294)
위 SQL문의 비용은 Cost = 53 X 0.5 = 27이다.
SQL> ALTER SESSION SET optimizer_index_cost_adj = 150; SQL> SELECT /*+INDEX(BIG_EMP)*/ * FROM BIG_EMP WHERE DEPTNO = 10 ;
Execution Plan ------------------------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=80 Card=294 Bytes=10584) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'BIG_EMP' (Cost=80 Card=294 Bytes=10584) 2 1 INDEX (RANGE SCAN) OF 'I_BIG_EMP_DEPTNO' (NON-UNIQUE) (Cost=1 Card=294)
위 SQL 문의 비용은 Cost = 53 X 1.5 = 80이다.
5-5) Sort-Merge Join인 경우
다음은 소트-머지 조인의 경우 비용 계산 공식이다. Cost = (Outer 테이블의 Sort Cost +Inner 테이블의 Sort Cost) -1 SQL> SELECT /*+use_merge(big_dept big_emp)*/ * FROM big_emp, big_dept WHERE BIG_EMP.DEPTNO = BIG_DEPT.DEPTNO;
사용자가 실행한 SQL문은 쿼리 변형기의 비용 계산기에 의해 여러 가지 유형의 실행계획으로 비용 분석된다. 그 중에 가장 적은 비용으로 실행되어질 수 있는 실행계획 하나가 선택되는데 이것을 Optimal Plan이라고 한다. 다음 문장들은 동일한 결과를 제공하지만 실행계획 생성기에 의해 가장 적은 비용의 실행계획을 선택한 결과이다.
6-1) 적정 플랜(Optimal Plan)
Index Scan인 경우
SELECT ename FROM big_emp WHERE deptno = 20 AND empno BETWEEN 100 AND 200 ORDER BY ename; Execution Plan ------------------------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=9 Card=1 Bytes=12) 1 0 SORT (ORDER BY) (Cost=9 Card=1 Bytes=12) 2 1 TABLE ACCESS (BY INDEX ROWID) OF 'BIG_EMP' (Cost=5 Card=1 Bytes=12) 3 2 INDEX (RANGE SCAN) OF 'I_BIG_EMP_EMPNO' (UNIQUE) (Cost=2 Card=1)
이 실행계획은 비용기반 옵티마이저에 의해 I_BIG_EMP_EMPNO 인덱스가 선택되었으며 이때 계산된 I-O COST는 9이다. I_BIG_EMP_DEPTNO 인덱스가 선택된 경우
SELECT /*+index(big_emp I_BIG_EMP_DEPTNO)*/ ename FROM big_emp WHERE deptno = 20 AND empno BETWEEN 100 AND 200 ORDER BY ename;
Execution Plan ------------------------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=70 Card=1 Bytes=12) 1 0 SORT (ORDER BY) (Cost=70 Card=1 Bytes=12) 2 1 TABLE ACCESS (BY INDEX ROWID) OF 'BIG_EMP' (Cost=66 Card=1 Bytes=12) 3 2 INDEX (RANGE SCAN) OF 'I_BIG_EMP_DEPTNO' (NON-UNIQUE) (Cost=2 Card=1)
이 실행계획은 I_BIG_EMP_DEPTNO 인덱스가 선택되었으며 이때 계산된 I-O COST는 70이다.
Full Table Scan인 경우
SELECT /*+full(big_emp)*/ ename FROM big_emp WHERE deptno = 20 AND empno BETWEEN 100 AND 200 ORDER BY ename; Execution Plan ------------------------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=61 Card=1 Bytes=12) 1 0 SORT (ORDER BY) (Cost=61 Card=1 Bytes=12) 2 1 TABLE ACCESS (FULL) OF 'BIG_EMP' (Cost=57 Card=1 Bytes=12)
이 실행계획은 Full Table Scan이 선택되었으며 이때 계산된 IO COST는 61이다. 결론적으로, 5-1, 5-2, 5-3의 SQL문장들은 동일한 문장, 동일한 결과를 제공하지만 이 문장이 실행될 수 있는 실행계획은 다양하다는 것을 알 수 있다. 이와 같이, 비용기반 옵티마이저는 여러 가지 실행계획 중에 가장 비용이 적게 발생하는 I_BIG_EMP_EMPNO 인덱스를 이용한 실행계획을 Optimal Plan으로 선택하게 된다.
6-2) 비용계산 분석 명령어
다음 문장은 비용분석기(Estimator)와 실행계획 생성기(Plan Generator)에 의해 비용 분석된 결과를 모니터링 하는 방법이다. SQL> ALTER SESSION SET EVENTS '10053 trace name context forever, level 1'; SQL> SELECT * FROM BIG_EMP, BIG_DEPT, ACCOUNT WHERE BIG_EMP.DEPTNO = BIG_DEPT.DEPTNO AND ACCOUNT.CUSTOMER = BIG_EMP.EMPNO SQL> EXIT [C:\] CD C:\ORACLE\ADMIN\ORA92\UDUMP [C:\] DIR ORA92_ORA_xxxx.trc <-- 워드패드 편집기를 통해 결과 확인
<분석결과>
*** 2005-07-17 10:41:27.000 *** SESSION ID:(10.976) 2005-07-17 10:41:27.000 QUERY SELECT * FROM BIG_EMP, BIG_DEPT, ACCOUNT WHERE BIG_EMP.DEPTNO = BIG_DEPT.DEPTNO AND ACCOUNT.CUSTOMER = BIG_EMP.EMPNO
분석된 결과 중에 Join order[n]는 여러 개의 테이블을 조인하는 경우 어떤 테이블부터 검색하여 어떤 순서에 의해 조인해 나가는 방법인지 분석하는 경우를 나타낸다. Join order[1]에서 Best NL cost: 5493은 중첩루프 조인의 비용 결과이며, Best SM cost : 257은 소트-머지 조인의 경우 비용 결과이다. 비용기반 옵티마이저는 하나의 조인순서가 결정되면 다양한 실행 방법들에 대한 비용을 일일이 계산하게 된다. 그 중에 가장 적은 비용이 발생하는 조인 순서와 실행 방법을 실행 계획으로 선택하게 되는 것이다.
요즘 20대 후반 부터 30대 중반까지 6년 전만 해도 다음 메일을 안쓴 사람은 거의 없었을 것이다. 그 당시 Daum이 웹포탈을 주름잡았었고(오만한 경영으로 네이버에게 1위자리를 내어주긴 했지만..) '카페'하면 Daum이었다. 하지만 지금은 이미 네이버와 Daum은 매출액만 10배 차이가 나고 사원수가 nhn이 Daum의 4배에 가깝게 많다. 이는 2008년 현재 공시에 의한 데이터이다.
지금 네이버는 오로지 포탈로만 돈을 벌고 있다 올해 연 매출액이 5000억이라 골드클럽에 가입할 정도로 잘나간다. 이는 단기간 성장세로 봐도 대단한 것이지만 앞으로 중장기적으로 봤을 때도 현재 Daum이 지금과 같은 서비스 체제를 가지게 된다면 아마 네이버를 따라잡기는 힘들 것 같다. 그 이유는 쥬니버에서 찾을 수 있다.
20대~30대는 쥬니버의 위력을 잘 모른다. 하지만 아이가 있는 가정이라면.. 특히 아이가 유치원생이나 초등학교 저학년 가정이라면 쥬니버의 위력을 잘 알 것이다. 쥬니버는 어린 아이들 사이에서 많은 인기 포털 중 하나이다. 이유는 쥬니버가 가지는 각종 컨텐츠 및 UI가 아이들에 맞게 잘 설계되어있기 때문이기도 하지만 포탈 중 어린이의 시점에 맞춰 운영하는 포탈이 전무하기 때문이다. 어린이를 상대로 한 포탈의 위력은 당장은 의미가 없을지도 모르지만 중장기적으로 어마어마 한 가치를 가지고 있다. 이유인 즉, 우선 한번 자신이 사용하는 포탈에 길들여지게 되면 계속 그 사람은 습관적으로 그 포탈을 사용하기 때문이다. 마치 네이버가 좋지 않다고, 필터링이 심하다고 말하는 사람도 서비스를 이용하기 위해 네이버를 들어가서 검색을 하는 것을 보면 가히 포탈을 이용한다는 것은 습관이라고 말할 수 있다. 쥬니버가 아이들의 포탈 검색습관을 바꾼다는 것이 지금의 시점에서는 별로 의미가 와닿지 않는다. 하지만 이들이 나이가 들어서 커간다고 해보자. 즉 쥬니버에서 네이버로 자신의 검색 포탈을 바꾸는 것이 더 쉽지 네이버에서 Daum으로 자신의 검색포털을 사용할 가능성은 작다는 이야기다. 물론 이들이 성인이 되어 자기 입맛에 맞는 포털을 사용하거나 혹은 웹상의 독과점을 인식하여 포털을 옮길 수도 있지만 역시나 Daum의 입장에서 보면 시간이 지남에 따라 자연스럽게 고객을 빼앗기게 된다. 고객을 빼앗긴다는 것은 결국 기업의 입장으로 보면 치명적이다. 물론 과연 Daum이 불특정 다수 접속자를 고객이라고 인지한다면 그나마 나은 것이다. 만약 자신의 포탈에 광고를 올리고 비용을 지불하는 사람만 고객이라고 인지한다면 10년이나 20년 뒤는 Daum은 적대적 M&A의 먹이감이 될 가능성이 매우 크다.
물론 Daum에서 유아용 포털을 운용하지 않는 것은 아니다. "Daum 키즈짱"이라는 포털이 있다. 어린이들의 눈높이에 맞춘 사이트이지만 사실 포털이라고 보기엔 아직 미흡한 면이 많다. 특히 학습에 대한 자료는 많이 후달린다. 물론 오픈한지 얼마 되지 않았기 때문에 그런 부분은 차차 개선되리라고 생각하지만 얼마나 비중을 두고 운영할 것인지는 잘 모르겠다. 참고로 키즈짱은 초등교육에 대한 자료는..글쎄다..;; 유아용 포털이라 그런지 모르겠지만 유아가 직접 컴퓨터를 이용해서 사이트를 돌아다니기 보단 부모님과 함께 컴퓨터를 사용하며 정보를 찾는데 더 초점이 맞춰져 있는 것 같다. 쥬니버와 키즈짱 어느게 더 좋다고 이야기는 못하겠다. 그건 아이들이 판단하는거니까.
그럼 Daum이 지금 대처해야 하는 방법은 무엇일까? 그것은 각각의 세대 별로 맞춤 포털 서비스를 제공하는 것이다. 특정 기업에 충성하는 고객은 서비스를 실제적으로 이용하기 보다는 서비스 자체를 영위하는 것이 더 크다. 예를 들어 나이키 운동화와 일반 운동화는 이용하는 면에서는 똑같지만 이를 이용하는 고객은 나이키라는 브랜드를 통해 자신의 삶의 질을 영위한다고 볼 수 있다. Daum도 각각의 맞춤 포털 서비스를 가지고 있어야 한다. 지금은 정말 불특정 다수에게 서비스하는 포털의 개념이 강하지만 만약 불특정의 사람들이 로그인을 한다면 그 순간부터 맞춤형 서비스로 바뀌어야 한다. 각각의 세대별로 관심사가 다르고 사용하는 포털의 특정 컨텐츠의 이용빈도도 다르다. 이를 CRM을 통해서 알아내든 아니면 설문을 하든 어떤 수로 알아내고 서비스하는게 Daum이 네이버를 견제할 수 있는 방법 중 하나라고 본다. 물론 검색의 질은 당연한 것이다. (검색의 질에 대한 이야기는 후에 구글과 Daum을 비교할 때 이야기 하겠다.) -----------------------------------------------------------------------------------------
위의 글은 2007년도 연구실에서 네이버와 구글의 기술적 측면을 분석할 때 잠깐 다음과 네이버를 비교하면서 생각한 글을 옮긴 것이다. 얼마 전 키즈짱이란 포털이 새로 나왔다. 이 포털을 테스트하기 위한 가장 큰 테스터들은 어린아이겠지 뭐.
난 대학생이고 곧 취직을 할 것이다. 뭐 이미 nhn은 떨어졌으니까 하반기에 노리고 하반기에 Daum도 있으니까 둘 다 지원해보려고 한다. 어느 기업에 취직을 한 다는 것은 결국 내 생각과 내 열정이 그 기업안에서 일어나야 하는 것이기 때문에 생각의 폭이 내가 속한 기업으로 치우치기 쉽다. 어느 기업을 가든 자신의 기업에 유리하게 생각할테니까. 얼마 전에 Daum에서 이런 광고를 봤다. "네이버vs다음" 근데 난 참 이 광고가 웃겼다. Daum이 도데체 무엇을 가지고 승부를 거는 것일까? 권투와 같이 단기적 성과를 가지고 순 잉여금이 2000억이 넘게 남는 기업을 이길 수 있을까? 물론 Daum 내부적으로 무엇인가 준비를 하고 있다. 내 선배가 Daum에서 일을 하는데 무엇인가 비장의 무기를 준비한 듯 하다. 다만 난 단지 거창하게 VS 할 생각 말고 우선 장기적으로 Daum이 공룡 네이버를 이길 방법을 다양한 측면에서 모색하는게 좋겠다는 생각을 했다. 어차피 1등과 2등의 전쟁은 끊이지 않을테니 말이다. 물론 3위의 초대형 공룡 google이 있긴 하지만 이이 초대형 google이란 공룡은 국내에선 그다지 가치가 없나보다. (사실 난 google 직원들이 무엇을 하는지 궁금하다.. 하긴 기업이 크니까 성과같은 것은 아예 안볼지도 모르지만..) 개인적으로 1등과 2등은 늘 공존해야 한다. 그래야 둘 다 성장하니까..
Daum과 naver의 이야기는 앞으로 생각 날 때마다 계속 올릴 생각이다. 주로 Daum이 네이버를 이길길 방법을 생각해서 올려야겠다. 이유는 그냥 2등이 1등을 이기면 멋지니까..ㅎㅎ 그래서 Daum이 1등이 되면 네이버의 측면에서 Daum을 이기는 법을 생각해보겠지..ㅎㅎ 물론 양쪽 기업 중 한군데도 안들어간다면 말이다. 뭐 안들어가는게 아니라 못들어가는게 더 맞는 말일 수 도 있지만.. 근데 항상 왜 Daum은 네이버를 뒤쫓아간다는 생각뿐이 안들까.. 마치 네이버가 무엇인가 서비스를 하면 따라가기 식으로 말이다.
멀티 티어, 분산된 시스템은 티어들 사이에 데이터를 보내고 받기 위한 RMI(remote method invocations)가 필요하다. 클라이언트들은 분산된 컴포넌트들을 다루어야 하는 복잡성에 노출되어 있다.
Problem
프리젠테이션-티어 컴포넌트들은 비지니스 서비스들과 직접적으로 상호 작용한다. 이런 직접적인 상호 작용은 프리젠테이션 티어에 대한 비지니스 서비스 API(application program interface)의 기본적인 구현 상세사항들을 외부에 노출한다. 결과적으로, 프리젠테이션-티어 컴포넌트들은 비지니스 서비스들의 구현을 바꾸는것에 취약하다: 비지니스 서비스의 구현이 바뀌면 프리젠테이션 티어에서 외부에 노출된 구현 코드또한 바뀌어야 한다.
또한, 그것들은 네트웍 성능상 불리한 요소가 될 것이다. 비지니스 서비스 API를 사용하는 프리젠테이션-티어 컴포넌트들이 네트웍 상에 너무많은 호출을 만들기 때문이다. 이것은 프리젠테이션-티어 컴포넌트들이 클라이언트 쪽의 캐쉬 메카니즘 또는 서비스를 모으는일 없이 기본적인 API를 직접적으로 사용할때 발생한다.
마지막으로, 서비스 API들을 직접적으로 외부에 노출하는 것은 EJB(Enterprise JavaBeans) 기술의 분산된 특성들에 대한 네트웍관련 문제점을 클라이언트가 다루게 한다.
Forces ● 프리젠테이션-티어 클라이언트들이 비지니스 서비스에 접근해야 한다.
● 다양한 클라이언트들(디바이스들, 웹 클라이언트들, thick 클라이언트들)이 비지니스 서비스에 접근해야 한다. ● 비지니스 서비스 API들은 비지니스 요구사항들의 변화에 따라 바뀔수 있다. ● 프리젠테이션-티어 클라이언트들과 비지니스 서비스들 간의 결합을 최소화 시키는것이 바람직하다.
그러므로, lookup과 access과 같은 서비스들의 기본적인 구현 상세 사항들을 숨긴다. ● 클라이언트들은 비지니스 서비스 정보를 위한 캐쉬 메카니즘을 구현해야 할 필요성이 있을 수 있다. ● 클라이언트과 비지니스 서비스들 간의 네트웍 트래픽을 줄이는 것이 바람직 하다.
※ thick 클라이언트 Thick 클라이언트는 Rich 클라이언트라고 지칭 되기도 한다. Thick 클라이언트의 대표적인 예 가 될 수 있는 환경으로는 금융권 사이트들을 들 수 있다. 키보드의 후킹(키보드로 보낸 메시지를 가로채는 작업)과 같은 작업을 보안하기 위해서는 클라이언트는 반드시 보안 모듈을 포함해야만 한다. 모듈을 배포하는 예로서는 ActiveX가 될 수가 있다. 하지만 ActiveX는 보안의 문제와 배포, 생산성 저하라는 단점들을 가지고 있다. 이와 반대로 Thin 클라이언트는 순수한 웹사이트를 그려보면 될 것이다. Thin 클라이언트는 배포가 쉽고, 유지할 수 있는 장점이 있는 반면에 사용자를 100% 만족시키지 못한다. 즉, 브라우저 기술의 한계가 나타나게 되는 것이다.
Solution(해결방안) 프리젠테이션-티어 클라이언트들과 비지니스 서비스들 간의 결합을 줄이기 위해 Business Delegate를 사용하라. Business Delegate는 EJB 기술의 lookup과 access와 같은 비지니스 서비스의 기본적인 구현 상세 사항들을 숨긴다.
Business Delegate는 클라이언트-측 비지니스 abstraction 처럼 동작한다; 이것은 비지니스 서비스들의 구현을 위한 abstraction을 제공하며 서비스들을 숨긴다. Business Delegate를 사용하면 프리젠테이션-티어 클라이언트들과 시스템의 비지니스 서비스들간의 결합을 줄인다. 구현 전략에 따라 Business Delegate는 비지니스 서비스 API의 구현안에서 발생 할 수 있는 휘발성(※서비스가 없어지는경우?)으로 부터 클라이언트들을 보호한다. 잠재적으로 이것은 비지니스 서비스 API 또는 이것의 기본적인 구현이 변할때 프리젠테이션-티어 클라이언트 코드가 수정되어야 하는 수를 감소시킨다.
그럼에도 불구하고, 기본적인 비지니스 서비스 API가 바뀌면 Business Delegate 안의 인터페이스 함수들은 여전히 수정을 필요로 할 수도 있다. 그렇지만, Business Delegate 보다 비지니스 서비스가 바뀌는 경우가 더 일반적인 경우일 것이다.
때때로, 개발자들은 비지니스 레이어를 추상화 하는것과 같은 미래에 이익이 될만한 디자인 목표가 추가적인 선행 작업을 야기시키는 것에 대해 회의적이다.
그럼에도 불구하고, 이 패턴 또는 이것의 전략들을 이용하는 것은 작은 양의 추가적인 선행 작업만으로 중요한 이점들을 제공하는 결과를 가져온다.
중요한 이점은 기본적인 서비스의 상세 사항을 숨기는 것이다. 예를 들면, 클라이언트는 naming과 lookup 서비스들에 대해 명쾌해 진다.
또한 Business Delegate는 비지니스 서비스들로 부터의 예외(java.rmi.Remote exceptions, Java Messages Service (JMS) exceptions 등등)를 처리한다.
Business Delegate는 서비스 레벨의 예외들을 중간에 가로채고 대신에 어플리케이션 레벨의 예외들을 생성한다.
어플리케이션 레벨의 예외들은 클라이언트에 의해 처리되기가 더욱 쉽고 사용자에게 친숙 할 것이다.
또한 Business Delegate는 서비스 실패시 발생하는 이벤트에서 필요한 모든 retry 또는 recovery 오퍼레이션들을 해결하지 못 할 문제라고 결정되기 전까지 클라이언트에 문제점을 노출하지 않고 명쾌하게 수행한다. 이런 점들이 패턴을 사용하는 이유이다.
또다른 이점은 delegate가 결과들을 캐쉬 할 수 있고 리모트 비지니스 서비스들을 참조 할 수 있다는 것이다.
캐쉬는 네트웍을 통한 불필요하고 값비싼 왕복들(round trips)을 제한하기 때문에 성능을 매우 많이 향상 시킨다.
Business Delegate는 Lookup 서비스에 의해 호출되는 컴포넌트를 이용한다.
Lookup 서비스는 비지니스 서비스 lookup 코드의 기본적 상세 구현을 숨길 책임이 있다.
Lookup Service는 Delegate의 일부분으로 작성될 수 있지만 우리는 Service Locator 패턴이 적용된 분리된 컴포넌트로 구현되기를 추천한다. (368 페이지의 "Service Locator" 참조.)
Business Delegate가 Session Facade와 함께 사용될때 일반적으로 둘 사이에 one-to-one 관계가 성립한다.
이런 one-to-one 관계는 여러개의 비지니스 서비스들과 상호작용 하는것(one-to-many 관계를 생성하는것)과 관련된 Business Delegate안에 캡슐화 되어져 있을 수 있는 로직이 때때로 Session Facade를 하나의 요인으로 다시 포함되기 때문에 존재한다.
마지막으로, 이 패턴이 간단히 프리젠테이션과 비지니스 티어들이 아니라, 다른 티어들간의 결합을 줄이는데 사용될수 있다는 것이 주목받을 만한 것이다.
Structure(구조)
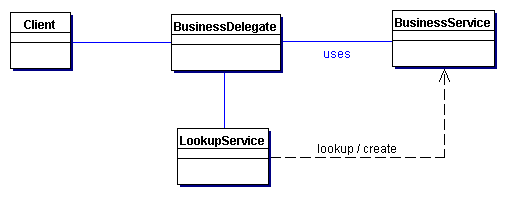
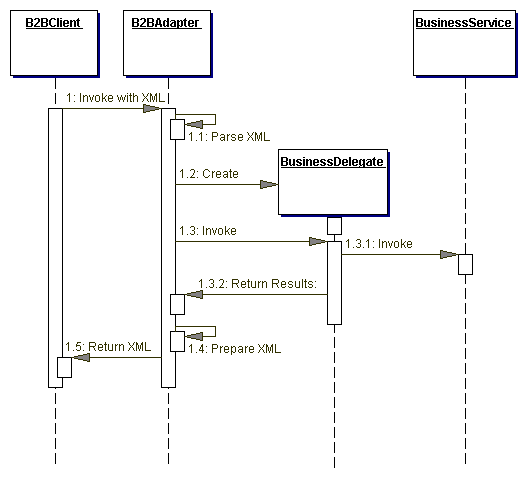
Figure 8.1은 Business Delegate 패턴을 표현하는 클래스 다이어그램을 보여준다. 클라이언트는 기본적인 비지니스 서비스에의 접근을 제공하기 위해 BusinessDelegate를 요청한다. BusinessDelegate는 요청된 BusinessService 컴포넌트를 얻기 위해 LookupService를 이용한다.
Figure 8.1 BusinessDelegate class diagram
Participants and Responsibilities
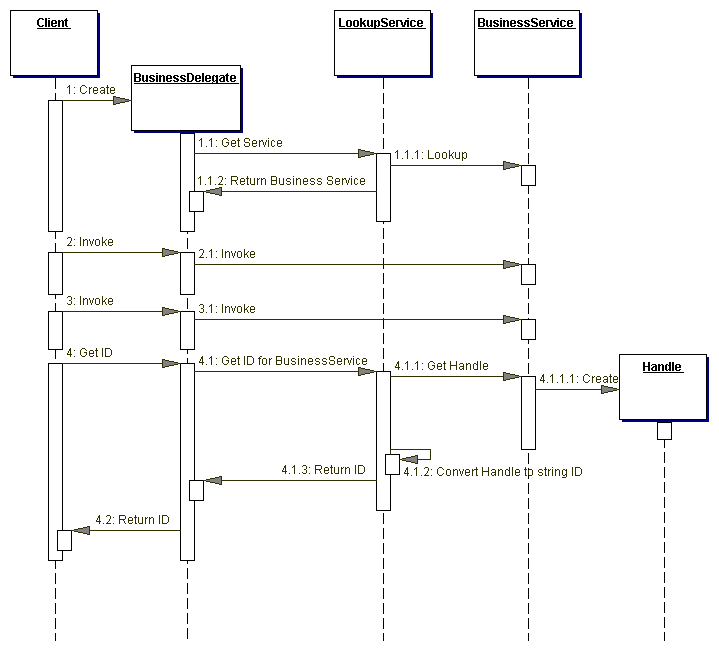
Figure 8.2 와 Figure 8.3 은 Business Delegate 패턴의 일반적인 상호작용을 설명하는 시퀀스 다이어그램을 보여준다.
Figure 8.2 BusinessDelegate sequence diagram
BusinessDelegate는 business service를 얻기위해 LookupService를 이용한다. business service는 클라이언트 관점에서 보면 비지니스 함수들을 호출하기 위해 사용된다. Get ID 함수는 BusinessDelegate가 비지니스 서비스를 위한 handle(예, EJBHandle 객체)의 String 버젼을 얻은다음 클라이언트에 String으로 리턴 할 수 있다는 것을 보여준다. 클라이언트는 나중에 비지니스 서비스에 다시 연결하기 위해 handle을 얻었을때 사용된 handle의 String 버젼을 이용할 수 있다. 이 기술은 새로운 lookup들을 피하려고 한다, handle은 이것의 비지니스 인스턴스에 다시 접속할 수 있는 능력이 있기 때문이다.
handle 객체들이 컨테이너 제공자에 의해 구현되었으며 다른 벤더들이 만든 컨테이너들 에서는 사용할 수 없다는 것을 주의하라.
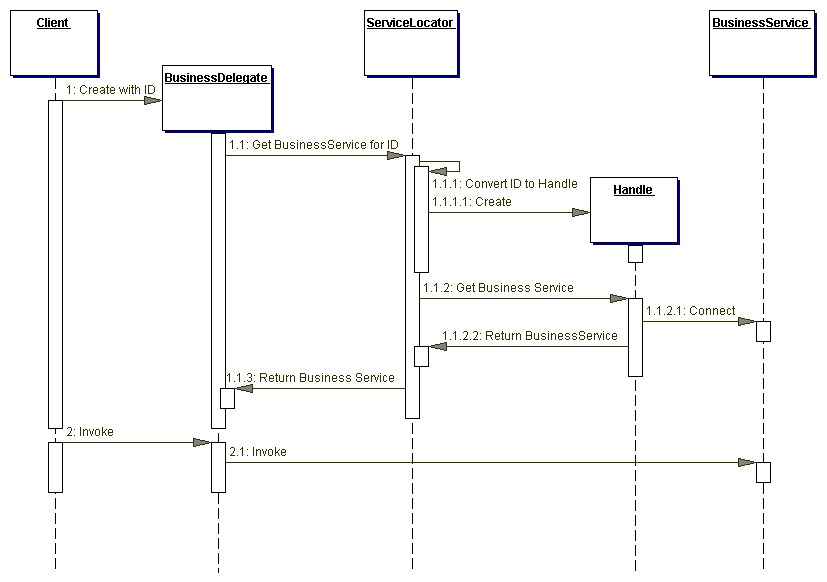
Figure 8.3 의 시퀀스 다이어그램은 handle을 이용해 BusinessService(예, session 또는 entity bean)를 얻는 것을 보여준다.
Figure 8.3 BusinessDelegate with ID sequence diagram
BusinessDelegate
BusinessDelegate의 역활은 business service의 제어와 보호이다. BusinessDelegate는 클라이언트에 2가지 타입으로 노출될 수 있다. 첫번째 요청 타입은 ID없이 BusinessDelegate를 설명한다, 반면 다른 하나는 ID를 가지고 설명한다, ID는 EJBHome 또는 EJBObject와 같은 remote object 참조의 String version 이다.
ID없이 초기화 할때 BusinessDelegate는 Lookup 서비스로 부터 서비스를 요청한다. 일반적으로 EJBHome 같은 Service Factory를 리턴하는 Service Locator 로서 구현된다. (368 페이지의 "Service Locator" 참조) BusinessDelegate는 Service Factory가 enterprise bean 같은 BusinessService를 얻고, 생성하고, 또는 제거하는 것을 요청한다.
ID string을 가지고 초기화 할때 BusinessDelegate는 BusinessService에 재접속하기 위해 ID string을 사용한다. 그러므로, BusinessDelegate는 BusinessService의 naming과 lookup의 기본적 상세 구현 으로부터 클라이언트를 보호한다. 여기에 더해, 프리젠테이션-티어 클라이언트는 결코 BusinessSession에 원격 호출을 직접적으로 하지 않는다; 대신에, 클라이언트는 BusinessDelegate를 이용한다.
LookupService
BusinessDelegate는 BusinessService를 얻기위해 LookupService를 이용한다. LookupService는 BusinessService lookup의 상세 구현을 갭슐화 한다.
BusinessService
BusinessService는 클라이언트에 요청된 서비스를 제공하는 비지니스-티어 컴포넌트(예, enterprise bean 또는 JMS component) 이다.
Strategies(전략)
Delegate Proxy Strategy
Business Delegate는 business service API의 기본 함수들을 클라이언트가 접근할 수 있게 하기위한 인터페이스를 외부에 노출한다. 이 전략에서, Business Delegate가 클라이언트 함수들을 session bean에 넘기는 proxy 기능을 제공하는 이것은 갭술화 이다. Business Delegate는 추가적으로 필요한 모든 데이터(lookup횟수를 줄여 성능향상을 얻을 수 있는 세션빈의 홈 또는 리모트 객체들의 리모트 참조)를 캐쉬 할 수 있다. Business Delegate는 또한 Service Locator의 서비스들을 이용해 이런 참조들을 String versions (IDs) 바꿀 수 있으며 그 반대도 가능하다.
이 전략을 위한 예제 구현은 이 패턴의 "Sample Code" 섹션에서 논의된다.
Delegate Adapter Strategy
Business Delegate는 Java 2 플랫폼, Enterprise Edition (J2EE) 기반의 서비스와 통신하는 B2B 환경에 매우 적합하다. 다른 종류의 시스템들은 통합 언어로 XML을 사용할 것이다. 어떤 시스템을 다른 시스템에 통합하는 것은 일반적으로 두개의 다른 시스템들을 통합하기 위한 Adapter [GoF] 를 필요로 한다. Figure 8.4 에서 예제를 볼수 있다.
Figure 8.4 Using the Business Delegate pattern with an Adapter strategy
Consequences (결론)
Reduces Coupling, Improves Manageability (결합을 줄이고, 관리성을 향상시킨다) Business Delegate는 비지니스-티어 상세 구현을 숨김으로서 프리젠테이션 티어과 비지니스 티어간의 결합을 줄인다. 이것은 Business Delegate라는 하나의 공간에 집중화 시킴으로서 변화를 관리하기 더 쉽다.
Translates Business Service Exceptions (비지니스 서비스 예외들을 변환한다) Business Delegate는 network 또는 infrastructure-related 예외들을 비지니스 예외들로 변환하고 기본적인 구현 명세서의 정보로 부터 클라이언트들을 보호하는데 적합하다.
Implements Failure Recovery and Thread Synchronization (실패 복구와 스레드 동기화를 구현한다) 비지니스 서비스 실패가 발생하면 Business Delegate는 클라이언트에 문제를 노출하지 않고 자동 복구 기능을 실행할 수 있다. 복구가 성공적으로 이루어 지면 크라이언트는 이 실패에 대해 알 필요가 없다. 만약 복구시도가 성공적이지 못하면 Business Delegate는 실패에 대해 클라이언트에 알릴 필요가 있다. 추가적으로, 만약 필요하면 비지니스 delegate 함수들은 동기화(synchronized) 될수 있다.
Exposes Simpler, Uniform Interface to Business Tier (비지니스 티어에 간결하고 일관된 인터페이스를 노출한다) 클라이언트에 더 나은 서비스를 하기위해 Business Delegate는 기본적인 엔터프라이즈 빈들에 의해 제공되는 다양한 인터페이스를 제공 할수도 있다.
Impacts Performance (성능 효과) Business Delegate는 공통적인 서비스 요청들을 위해 프리젠테이션 티어에 캐쉬 서비스(그리고 더 좋은 성능)를 제공할 수 있다.
Introduces Additional Layer (추가적인 레이어 삽입) Business Delegate는 클라이언트와 서비스 사이의 불필요한 레이어의 추가로 인해 추가적인 복잡성이 추가되고 유연성을 줄이는 것으로 보여질 수 있다. 어떤 개발자들은 Delegate Proxy 전략을 이용한 구현들을 가지고 Business Delegates를 개발하는 것은 불필요한 노력을 들이는 것으로 느낄수 있다. 그렇지만, 일반적으로 그런 약점들 보다 패턴이 주는 잇점들이 더 중요하다.
Hides Remoteness (원격특성들을 숨긴다) location의 명쾌함이 이 패턴이 주는 잇점중 하나인 반면, 개발자가 로컬에 있는 remote service를 다루기 때문에 다양한 문제점이 발생 할 수 있다. 만약 클라이언트 개발자가 Business Delegate는 remote service의 클라이언트 측 프록시라는 것을 이해하지 못하면 이런 문제점이 발생할 수 있다. 일반적으로, Business Delegate에 있는 함수 호출은 내부에 있는 원격 함수 호출의 결과를 가져온다. 이것을 무시하고 개발자가 단일 업무를 수행하기 위해 많은 양의 함수 호출을 만들려고 시도한다면 네트웍 트래픽을 증가시킬 것이다.
Sample Code (예제 코드)
Implementing the Business Delegate Pattern (Business Delegate 패턴 구현)
Professional Services Application (PSA) 를 고려하는 웹-티어 클라이언트는 Session Facade 패턴을 구현하는 세션빈에 접근하기를 필요로한다. Business Delegate 패턴은 ResourceDelegate(Delegate class)를 디자인하기 위해 적용될 수 있다. ResourceDelegate는 ResourceSession(session bean)을 다루를 복잡성을 갭슐화 한다. ResourceDelegate는 Example 8.1 에서 보여지는 이 예제를 구현한다. 그리고 상응하는 원격 인터페이스인 ResourceSession(Session Facade bean)은 Example 8.2 에서 볼수 있다.
Example 8.1 Implementing Business Delegate Pattern - ResourceDelegate
// Remote reference for Session Facade private ResourceSession session;
// Class for Session Facade's Home object private static final Class homeClazz = corepatterns.apps.psa.ejb.ResourceSessionHome.class;
// Default Constructor. Looks up home and connects // to session by creating a new one public ResourceDelegate() throws ResourceException { try { ResourceSessionHome home = (ResourceSessionHome) ServiceLocator.getInstance().getHome( "Resource", homeClazz); session = home.create(); } catch(ServiceLocatorException ex) { // Translate Service Locator exception into // application exception throw new ResourceException(...); } catch(CreateException ex) { // Translate the Session create exception into // application exception throw new ResourceException(...); } catch(RemoteException ex) { // Translate the Remote exception into // application exception throw new ResourceException(...); } }
// Constructor that accepts an ID (Handle id) and // reconnects to the prior session bean instead // of creating a new one public BusinessDelegate(String id) throws ResourceException { super(); reconnect(id); }
// Returns a String ID the client can use at a // later time to reconnect to the session bean public String getID() { try { return ServiceLocator.getId(session); } catch (Exception e) { // Throw an application exception } }
// method to reconnect using String ID public void reconnect(String id) throws ResourceException { try { session = (ResourceSession) ServiceLocator.getService(id); } catch (RemoteException ex) { // Translate the Remote exception into // application exception throw new ResourceException(...); } }
// The following are the business methods // proxied to the Session Facade. If any service // exception is encountered, these methods convert // them into application exceptions such as // ResourceException, SkillSetException, and so // forth.
public ResourceTO setCurrentResource( String resourceId) throws ResourceException { try { return session.setCurrentResource(resourceId); } catch (RemoteException ex) { // Translate the service exception into // application exception throw new ResourceException(...); } }
public ResourceTO getResourceDetails() throws ResourceException {
try { return session.getResourceDetails(); } catch(RemoteException ex) { // Translate the service exception into // application exception throw new ResourceException(...); } }
public void setResourceDetails(ResourceTO vo) throws ResourceException { try { session.setResourceDetails(vo); } catch(RemoteException ex) { throw new ResourceException(...); } }
public void addNewResource(ResourceTO vo) throws ResourceException { try { session.addResource(vo); } catch(RemoteException ex) { throw new ResourceException(...); } }
// imports ... public interface ResourceSession extends EJBObject {
public ResourceTO setCurrentResource( String resourceId) throws RemoteException, ResourceException;
public ResourceTO getResourceDetails() throws RemoteException, ResourceException; public void setResourceDetails(ResourceTO resource) throws RemoteException, ResourceException;
public void addResource(ResourceTO resource) throws RemoteException, ResourceException;
public void removeResource() throws RemoteException, ResourceException;
// methods for managing blockout time by the // resource public void addBlockoutTime(Collection blockoutTime) throws RemoteException, BlockoutTimeException;
public void updateBlockoutTime( Collection blockoutTime) throws RemoteException, BlockoutTimeException;
public void removeBlockoutTime( Collection blockoutTime) throws RemoteException, BlockoutTimeException;
public void removeAllBlockoutTime() throws RemoteException, BlockoutTimeException;
// methods for resource skillsets time by the //resource public void addSkillSets(Collection skillSet) throws RemoteException, SkillSetException;
public void updateSkillSets(Collection skillSet) throws RemoteException, SkillSetException;
public void removeSkillSet(Collection skillSet) throws RemoteException, SkillSetException;
일반적으로 String 객체를 가지고 조작하는 일들이 빈번하게 일어나는데 가장 흔하게 볼 수 있는 사례가 다음과 같다.
String name = "아무개"; System.out.println("안녕하세요, 저는 " + name + "입니다");
이 예에서는 3 개의 String 객체들이 사용되고 있다.
"아무개"
"안녕하세요, 저는 "
"입니다"
이 세 개의 String 객체들이 + 연산자에 의해 더해지고 그 결과를 System.out.println()으로 전달한다.
문제는 String 클래스가 불변 클래스라는 데에 있다. 불변 클래스란 내부 속성이 변하지 않는 클래스를 말한다. 따라서 String 객체에 대한 + 연산자는 첫 번째 String 객체에 다음 String 객체를 더하는 것이 아니라 둘을 포함하는 새로운 String 객체를 생성한다. 위의 예가 처리되는 과정을 자세히 살펴보면 다음과 같다.
String 객체0 "아무개"를 String 변수 name에 설정한다.
String 객체1 "안녕하세요, 저는 "을 생성한다.
String 객체2 "입니다"를 생성한다.
객체1과 객체0를 이용하여 String 객체3 "안녕하세요, 저는 아무개"를 생성한다.
객체3과 객체2를 이용하여 String 객체4 "안녕하세요, 저는 아무개입니다"를 생성한다.
객체4를 System.out.println()으로 전달한다.
알게 모르게 객체3과 객체4라는 낭비가 발생한다. 사실 이 예에서는 그리 심각한 문제가 아니지만 String에 대한 + 연산이 매우 빈번하게 일어나면 티끌 모아 태산이라고 퍼포먼스 저하를 발생시킬 수 있다. 이는 전적으로 String 클래스가 불변 클래스이기 때문에 발생한다.
이러한 문제 때문에 JDK는 StringBuffer 클래스를 제공한다. StringBuffer 클래스는 불변 클래스가 아니며, append() 를 통해 내부 속성을 변형시킬 수 있다. StringBuffer 클래스를 이용해 수정한 코드는 다음과 같다.
String name = "아무개"; StringBuffer buffer = new StringBuffer(); buffer.append("안녕하세요, 저는 ").append(name).append("입니다"); System.out.println(buffer.toString());
StringBuffer 클래스를 이용하면 위의 예에서 생긴 객체3과 객체4와 같은 낭비를 발생시키지 않는다. toString()을 호출할 때 비로소 최종 결과물을 String 객체로 반환하는 것이 전부일 뿐이다.
StringBuffer 클래스의 모든 메소드는 동기화되어있다. 멀티스레딩 환경에 적응하기 위함인데 두 번째 예에서처럼 멀티스레딩을 고려할 필요가 없는 상황에서라면 동기화는 역시 퍼포먼스 저하를 일으킨다. JDK는 이에 대해 StringBuilder 클래스를 제공한다. StringBuilder 클래스는 StringBuffer 클래스와 API가 동일하며 동기화를 하지 않는다.
String 객체에 대한 + 연산은 사실 개발 과정에서 매우 빈번하게 일어난다. 대부분 로그를 남기는 목적으로 사용하는데 로그를 남기는 행위가 필요 이상으로 퍼포먼스를 갉아먹는 것은 꽤나 바람직하지 못하다. 로그 등의 목적이라면 StringBuilder 클래스를, 동기화가 필요한 곳이라면 StringBuffer 클래스를 사용하라!
데이터베이스 관련 책을 읽다보면 Relation과 Table을 같은 용어로 이야기하는 경우가 있다.
어떤 책의 경우 "릴레이션이 테이블이다." 라고 되어있다. 하지만 사실상 릴레이션은 테이블과는 약간 다르다. 결론적으로 말하자면 릴레이션은 모두 테이블이지만 모든 테이블이 다 릴레이션은 아니라는 이야기다.
Codd, E.F의 "A Reational Model of Data for Larger Shared Databanks"의 논문에 보면 릴레이션의 특징을 정의하였다.
행은 개체에 대한 데이터를 포함한다.
열은 개체의 속성에 대한 데이터를 포함한다.
한 열의 모든 항목은 동일한 종류다.
각 열은 유일한 이름을 가진다.
테이블의 셀은 단일 값을 포함한다.
열의 순서는 중요하지 않다.
행의 순서는 중요하지 않다.
어떤 두개의 행도 동일하지 않다.
아래는 DAVID M. KROENKE의 DATABASE PROCESSING이라는 책에서 나온 해설이다.
테이블이 릴레이션이 되기 위해서는 테이블의 행들이 개체에 대한 데이터를 저장해야하고, 테이블들의 열이 그 개체들의 특성에 대한 데이터를 저장해야 한다. 릴레이션은 한 열의 모든 값들이 동일한 종류여야 한다.
예를 들어 어떤 릴레이션의 첫번째 행의 두번째 열이 FirstName을 가진다면 그 릴레이션의 모든 행의 두번째 열도 FistName을 가져야 한다. 또한 열의 이름은 유일해야 한다. 즉 동일 릴레이션에 속한 두 열은 같은 이름을 가질 수 없다.
릴레이션의 각 Cell은 단일한 값 또는 항목만 가진다. 다중 항목은 허용되지 않는다. (제 1 정규화)
마지막으로 주어진 테이블이 릴레이션이 되기 위해서는 동일한 행이 존재하면 안된다.
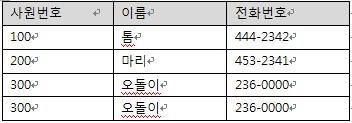
간단한 예를 들면
위의 표는 테이블이지만 릴레이션은 아니다.
사원번호 300의 오돌이가 복수로 테이블 안에 저장되어 있기 때문이다.
릴레이션 특성에서 "어떤 두개의 행도 동일하지 않다."를 위반했다.
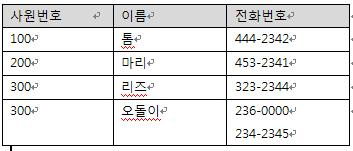
또 하나의 예를 들면
이 표도 역시 테이블이지만 릴레이션은 아니다.
릴레이션의 특성에서 "테이블의 셀은 단일 값을 포함한다."를 위반하였다.
설명 XP는 애자일 개발 방법론의 한 종류로서 1990년대 초 Kent Beck에 의해 고안되었다. 기존의 방법과는 달리 요구사항의 변경으로 인한 비용이 개발 기간에 상관없이 일정하게 유지되도록 하는 것이 핵심이다. XP는 의사소통, 단순성, 피드백, 용기를 중시하는 개발 방법론이다. XP에서 프로그래머와 고객, 동료 프로그래머와의 의사소통을 중시하고, 설계를 단순하고 명확하게 유지하려고 하며, 비즈니스에서 가장 우선순위가 높은 것 부터 개발한다 이런 것은 고객의 요구사항과 기술의 변경에 대응할 수 있다.
XP는 2종류의 약속을 한다. 프로그래머에게 대해, XP는 프로그래머가 매일, 중요한 업무에 열중 할수 있도록 약속한다. 프로그래머는 불안한 상황에 자기 혼자만 직면하지 된다. 시스템을 성공 시키기 위해서, 자신의 힘으로 모든 할 수 있는 일을 할 수 있도록 된다. 최선을 위해서 결단을 내리고, 자신이 적임이지 않은 일에 관해서는 결정은 내리지 않는다. 고객과 매니져에 대해, XP는 매주마다 어느 프로그래밍으로부터 최고의 가치를 얻을 수 있다는 것을 약속한다. 수주간마다 골을 향해서 구체적인 진보가 보일도록 한다. 계획 외의 코스트가 생기지 않도록 하고, 개발 도중에서 프로젝트의 방향이 변하는 것이 가능하도록 한다. 다시 말해, XP는 프로젝트의 리스크를 줄이고, 비지니스 변화에 리스폰스(적응)를 개선 하고, 시스템의 가동기간(라이프)을 통해서 생산성을 향상시키고, 동시에 팀에게 소프트웨어를 만들때 기쁨을 느낄 수 있도록 약속한다.
역할 프로그래머 분석, 설계, 테스트, 코딩, 시스템 통합을 하며 업무에 대한 난이도 조정 및 시스템 관리를 한다.
관리자 고객과 프로그래머가 함께 일할 수 있도록 해준다. 프로잭트 총괄의 의미보다는 진행에 도움을 주는 역할을 한다.
고객 실제적으로 시스템에 대한 요구사항을 정의하고 우선순이를 설정한다. 고객이 필요한 범위를 결정하면 개발자는 개발을 한다.
관계도
XP의 12가지 실천사항 계획세우기: 고객이 요구하는 비즈니스 가치를 정의하고 개발자에게 필요와 어떤 부분이 지연될지 알려준다 소규모릴리즈: 작은 시스템을 만들고 단위별로 업데이트한다. 상징: 공통적인 이름 체계를 갖는다. 단순한 디자인: 현재의 요구사항에 맞는 단순한 시스템을 설계한다. 지속적인 테스팅: XP는 적합성을 중요시 여긴다. 리팩토링: 개발하는 동안 제품 설계를 향상시킨다. 짝프로그래밍: 개발자 두명이서 5분동안 번갈아가며 하나의 개발을 서로 쭉 내려가며 코딩한다. 공동 코드 소유: 누구나 코드 수정이 가능하며 그에 대한 책임도 공유한다. 지속적인 통합: 매일 여러번 소프트웨어를 통합하고 빌드한다. 주당 40시간의 업무: 피곤한 개발자가 실수를 더 많이하기 때문에 휴식을 보장한다. 현장 고객 지원: 의사소통을 향상시키고 문서양을 줄일 수 있다. 코딩 표준: 코딩 가이드라인을 작성하여 모두 가이드라인을 따른다.
 invalid-file
invalid-file